







 lightGBM是微软推出的高效、轻量级的梯度提升机,针对xgboost的内存消耗和速度问题进行优化。其特点包括基于Histogram的决策树算法、带深度限制的Leaf-wise生长策略,支持并行化学习和处理大规模数据。通过调整num_leaves等参数,可以在防止过拟合的同时提高模型精度。
lightGBM是微软推出的高效、轻量级的梯度提升机,针对xgboost的内存消耗和速度问题进行优化。其特点包括基于Histogram的决策树算法、带深度限制的Leaf-wise生长策略,支持并行化学习和处理大规模数据。通过调整num_leaves等参数,可以在防止过拟合的同时提高模型精度。
1. foreword
TSA比赛中,开始整的LR,把原始特征one-hot处理后输入LR训练。过了段时间开始搞RF和XGB,再后面搞LightGBM。
2. lightGBM简介
xgboost的出现,让数据民工们告别了传统的机器学习算法们:RF、GBM、SVM、LASSO……..。现在微软推出了一个新的boosting框架,想要挑战xgboost的江湖地位。
顾名思义,lightGBM包含两个关键点:light即轻量级,GBM 梯度提升机。
LightGBM 是一个梯度 boosting 框架,使用基于学习算法的决策树。它可以说是分布式的,高效的,有以下优势:
更快的训练效率
低内存使用
更高的准确率
支持并行化学习
可处理大规模数据
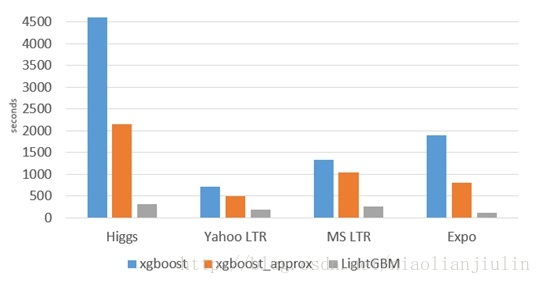
与常用的机器学习算法进行比较:速度飞起
3. xgboost缺点
XGB的介绍见
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 176
176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









