







数据预处理分析,最后面附有决策树算法的实现
原始数据:
原数据地址

计算第一次决策如果
分别对在14天各个属性下是否进行施肥的统计情况且计算该属性的基尼指数,同一种属性不同表现的基尼指数表示为M,加权平均之后为节点的基尼指数,用N表示
天气:
#encoding = utf-8
import pandas as pd
Base_file = pd.read_excel('Data.xlsx')
Base_file.head(15)
#Base_file.head()
Weather_Sunny = Base_file[Base_file['天气'] == '晴天']['是否施肥'].value_counts()
#print(Weather_Sunny)['否' '否' '否' '是' '是']
Weather_Rainy = Base_file[Base_file['天气'] == '雨天']['是否施肥'].value_counts()
Weather_Overcast = Base_file[Base_file['天气'] == '阴天']['是否施肥'].value_counts()
Weather_Overcast['否'] = 0
Weather_df = pd.DataFrame([
pd.Series([Weather_Sunny['是'], Weather_Sunny['否']], index = ['是', '否']),
pd.Series([Weather_Rainy['是'], Weather_Rainy['否']], index = ['是', '否']),
pd.Series([Weather_Overcast['是'], Weather_Overcast['否']], index = ['是', '否'])
], index=['晴天', '雨天', '阴天'])
Weather_df.head()
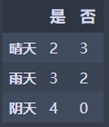
晴天:M1 = 2 * 2/5 * (1 - 2/5) = 0.444444445
雨天:M2 = 2 * 3/5 * (1 - 3/5) = 0.48
阴天:M3 = 0
N1 = 5/14 * M1 + 5/14 * M2 = 0.343
温度:
Hot = Base_file[Base_file['温度'] == '炎热']['是否施肥'].value_counts()
Cool = Base_file[Base_file['温度'] == '温']['是否施肥'].value_counts()
Cold = Base_file[Base_file['温度'] == '冷']['是否施肥'].value_counts()
Temperature_df = pd.DataFrame([
pd.Series([Hot['是'], Hot['否']], index = ['是', '否']),
pd.Series([Cool['是'], Cool['否']], index = ['是', '否']),
pd.Series([Cold['是'], Cold['否']], index = ['是', '否'])
], index = ['炎热', '温', '冷'])
Temperature_df.head()
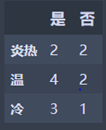
炎热:M1 = 2 * 2/4 * (1 - 2/4) = 0.5
温 : M2 = 2 * 2/6 * (1 - 2/6) = 0.44444445
冷: M3 = 2 * 3/4 * (1 - 3/4) = 0.375
N2 = 4/14 * M1 + 6/14 * M2 + 4/14 * M3 = 0.440
湿度:
Humidity_high = Base_file[Base_file['湿度'] == '高']['是否施肥'].value_counts()
Humidity_mid = Base_file[Base_file['湿度'] == '中']['是否施肥'].value_counts()
Humidity_df = pd.DataFrame([
pd.Series([Humidity_high['是'], Humidity_high['否']], index = ['是', '否']),
pd.Series([Humidity_mid['是'], Humidity_mid['否']], index = ['是', '否'])
], index = ['高', '中'])
Humidity_df.head()
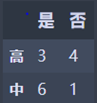
高:M1 = 2 * 3/4 * (1 - 3/4) = 0.375
中:M2 = 2 * 6/7 * (1 - 6/7) = 0.245
N3 = 1/2 * M1 + 1/2 * M2 = 0.310
风力:
Wind_strong = Base_file[Base_file['风力'] == '强风']['是否施肥'].value_counts()
Wind_weak = Base_file[Base_file['风力'] == '弱风']['是否施肥'].value_counts()
Wind_df = pd.DataFrame([
pd.Series([Wind_strong['是'], Wind_strong['否']], index = ['是', '否']),
pd.Series([Wind_weak['是'], Wind_weak['否']], index = ['是', '否'])
], index = ['强风', '弱风'])
Wind_df.head()
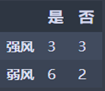
强风:M1 = 2 * 3/6 * (1 - 3/6) = 0.5
弱风:M2 = 2 * 6/8 * (1 - 6/8) = 0.375
N4 = 6/14 * M1 + 8/14 * M2 = 0.429
因为N2 > N4 > N1 > N3,所以第一次决策应根据湿度来分类:

因为此次分类之后,然未出现叶子节点,所以需要分别对第二排的两个节点进行分类,过程与第一次决策类似,计算各个属性下是否进行施肥的统计情况且计算该属性的基尼指数
左右节点的数据分别如下:
Base_file = pd.read_excel('Data.xlsx')
Base_file.head(15)
Temperature_df_high = Base_file[Base_file['湿度'] == '高']
Temperature_df_high.head(14)

先对左边节点分析:
天气:
Weather_Sunny = Temperature_df_high[Temperature_df_high['天气'] == '晴天']['是否施肥'].value_counts()
Weather_Sunny['是'] = 0
#print(Weather_Sunny)['否' '否' '否' '是' '是']
Weather_Rainy = Temperature_df_high[Temperature_df_high['天气'] == '雨天']['是否施肥'].value_counts()
Weather_Overcast = Temperature_df_high[Temperature_df_high['天气'] == '阴天']['是否施肥'].value_counts()
Weather_Overcast['否'] = 0
Weather_df = pd.DataFrame([
pd.Series([Weather_Sunny['是'], Weather_Sunny['否']], index = ['是', '否']),
pd.Series([Weather_Rainy['是'], Weather_Rainy['否']], index = ['是', '否']),
pd.Series([Weather_Overcast['是'], Weather_Overcast['否']], index = ['是', '否'])
], index=['晴天', '雨天', '阴天'])
Weather_df.head()
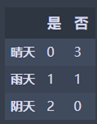
晴天:M1 = 0
雨天:M2 = 0.5
阴天:M3 = 0
N1 = 2/7 * M2 = 0.143
温度:
Hot = Temperature_df_high[Temperature_df_high['温度'] == '炎热']['是否施肥'].value_counts()
Cool = Temperature_df_high[Temperature_df_high['温度'] == '温']['是否施肥'].value_counts()
Cold = Temperature_df_high[Temperature_df_high['温度'] == '冷']['是否施肥'].value_counts()
Cold['是'] = 0
Cold['否'] = 0
Temperature_df = pd.DataFrame([
pd.Series([Hot['是'], Hot['否']], index = ['是', '否']),
pd.Series([Cool['是'], Cool['否']], index = ['是', '否']),
pd.Series([Cold['是'], Cold['否']], index = ['是', '否'])
], index = ['炎热', '温', '冷'])
Temperature_df.head()
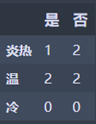
炎热:M1 = 0.44444444445
温: M2 = 0.5
冷: M3 = 0
N2 = 3/7 * M1 + 4/7 * M3 = 0.476
风力:
Wind_strong = Temperature_df_high[Temperature_df_high['风力'] == '强风']['是否施肥'].value_counts()
Wind_weak = Temperature_df_high[Temperature_df_high['风力'] == '弱风']['是否施肥'].value_counts()
Wind_df = pd.DataFrame([
pd.Series([Wind_strong['是'], Wind_strong['否']], index = ['是', '否']),
pd.Series([Wind_weak['是'], Wind_weak['否']], index = ['是', '否'])
], index = ['强风', '弱风'])
Wind_df.head()
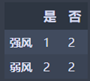
强风:M1 = 0.44444444445
弱风:M2 =0.5
N3 = 3/7 * M1 + 4/7 * M2 = 0.476
N1 > N2 = N3
所以左边的节点来说应该根据天气情况来分类
对右边节点分析:
天气:
Weather_Sunny = Temperature_df_mid[Temperature_df_mid['天气'] == '晴天']['是否施肥'].value_counts()
Weather_Sunny['否'] = 0
Weather_Rainy = Temperature_df_mid[Temperature_df_mid['天气'] == '雨天']['是否施肥'].value_counts()
Weather_Overcast = Temperature_df_mid[Temperature_df_mid['天气'] == '阴天']['是否施肥'].value_counts()
Weather_Overcast['否'] = 0
Weather_df = pd.DataFrame([
pd.Series([Weather_Sunny['是'], Weather_Sunny['否']], index = ['是', '否']),
pd.Series([Weather_Rainy['是'], Weather_Rainy['否']], index = ['是', '否']),
pd.Series([Weather_Overcast['是'], Weather_Overcast['否']], index = ['是', '否'])
], index=['晴天', '雨天', '阴天'])
Weather_df.head()
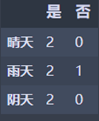
晴天:M1 = 0
雨天:M2 = 0.444444444445
阴天:M3 = 0
N1 = 3/7 * M2 = 0.190
温度:
Hot = Temperature_df_mid[Temperature_df_mid['温度'] == '炎热']['是否施肥'].value_counts()
Hot['否'] = 0
Cool = Temperature_df_mid[Temperature_df_mid['温度'] == '温']['是否施肥'].value_counts()
Cool['否'] = 0
Cold = Temperature_df_mid[Temperature_df_mid['温度'] == '冷']['是否施肥'].value_counts()
Temperature_df = pd.DataFrame([
pd.Series([Hot['是'], Hot['否']], index = ['是', '否']),
pd.Series([Cool['是'], Cool['否']], index = ['是', '否']),
pd.Series([Cold['是'], Cold['否']], index = ['是', '否'])
], index = ['炎热', '温', '冷'])
Temperature_df.head()
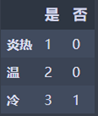
炎热:M1 = 0
温: M2 = 0
冷: M3 = 2 * 3/4 * (1 - 3/4) = 0.375
N2 = 3/7 * M3 = 0.214
风力:
Wind_strong = Temperature_df_mid[Temperature_df_mid['风力'] == '强风']['是否施肥'].value_counts()
Wind_weak = Temperature_df_mid[Temperature_df_mid['风力'] == '弱风']['是否施肥'].value_counts()
Wind_weak['否'] = 0
Wind_df = pd.DataFrame([
pd.Series([Wind_strong['是'], Wind_strong['否']], index = ['是', '否']),
pd.Series([Wind_weak['是'], Wind_weak['否']], index = ['是', '否'])
], index = ['强风', '弱风'])
Wind_df.head()
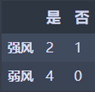
强风:M1 = 2 * 2/3 * (1 - 2/3) = 0.44444445
弱风:M2 = 0
N3 = 3/7 * M2 = 0.190
N1 = N3 > N2
这里可以有两种分类决策方法,这里选择使用天气属性对右边节点进行分类,结合对左边节点的分析,对第二层的分类如下:

经过第二次分类之后,出现了叶子节点,只剩下两个节点需要继续分类,且只剩下温度和风力两个属性,下面是第二次分类之后的左右两个节点数据:
Weather_df_Rainy1 = Base_file[Base_file['湿度'] == '高'][Base_file['天气'] == '雨天']
Weather_df_Rainy1.head()
Weather_df_Rainy2 = Base_file[Base_file['湿度'] == '中'][Base_file['天气'] == '雨天']
Weather_df_Rainy2.head()
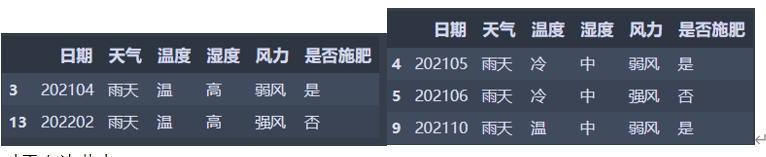
对于左边节点:
温度:
Hot = Weather_df_Rainy1[Weather_df_Rainy1['温度'] == '炎热']['是否施肥'].value_counts()
Hot['是'] = 0
Hot['否'] = 0
Cool = Weather_df_Rainy1[Weather_df_Rainy1['温度'] == '温']['是否施肥'].value_counts()
Cold = Weather_df_Rainy1[Weather_df_Rainy1['温度'] == '冷']['是否施肥'].value_counts()
Cold['是'] = 0
Cold['否'] = 0
Temperature_df = pd.DataFrame([
pd.Series([Hot['是'], Hot['否']], index = ['是', '否']),
pd.Series([Cool['是'], Cool['否']], index = ['是', '否']),
pd.Series([Cold['是'], Cold['否']], index = ['是', '否'])
], index = ['炎热', '温', '冷'])
Temperature_df.head()

炎热:M1 = 0
温: M2 = 2 * 1/2 * (1 – 1/2) = 0.5
冷: M3 = 0
N1 = M2 = 0.5
风力:
Hot = Weather_df_Rainy1[Weather_df_Rainy1['温度'] == '炎热']['是否施肥'].value_counts()
Hot['是'] = 0
Hot['否'] = 0
Cool = Weather_df_Rainy1[Weather_df_Rainy1['温度'] == '温']['是否施肥'].value_counts()
Cold = Weather_df_Rainy1[Weather_df_Rainy1['温度'] == '冷']['是否施肥'].value_counts()
Cold['是'] = 0
Cold['否'] = 0
Temperature_df = pd.DataFrame([
pd.Series([Hot['是'], Hot['否']], index = ['是', '否']),
pd.Series([Cool['是'], Cool['否']], index = ['是', '否']),
pd.Series([Cold['是'], Cold['否']], index = ['是', '否'])
], index = ['炎热', '温', '冷'])
Temperature_df.head()
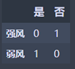
强风:M1 = 0
弱风:M2 = 0
N2 = 0
N1 > N2
所以左边的节点应用风力属性继续往后分类
对右边节点分析:
温度:
Hot = Weather_df_Rainy2[Weather_df_Rainy2['温度'] == '炎热']['是否施肥'].value_counts()
Hot['是'] = 0
Hot['否'] = 0
Cool = Weather_df_Rainy2[Weather_df_Rainy2['温度'] == '温']['是否施肥'].value_counts()
Cool['否'] = 0
Cold = Weather_df_Rainy2[Weather_df_Rainy2['温度'] == '冷']['是否施肥'].value_counts()
Temperature_df = pd.DataFrame([
pd.Series([Hot['是'], Hot['否']], index = ['是', '否']),
pd.Series([Cool['是'], Cool['否']], index = ['是', '否']),
pd.Series([Cold['是'], Cold['否']], index = ['是', '否'])
], index = ['炎热', '温', '冷'])
Temperature_df.head()
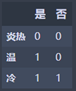
炎热:M1 = 0
温: M2 = 0
冷: M3 = 2 * 1/2 * (1 – 1/2) = 0.5
N1 = M3 = 0.5
风力:
Wind_strong = Weather_df_Rainy2[Weather_df_Rainy2['风力'] == '强风']['是否施肥'].value_counts()
Wind_strong['是'] = 0
Wind_weak = Weather_df_Rainy2[Weather_df_Rainy2['风力'] == '弱风']['是否施肥'].value_counts()
Wind_weak['否'] = 0
Wind_df = pd.DataFrame([
pd.Series([Wind_strong['是'], Wind_strong['否']], index = ['是', '否']),
pd.Series([Wind_weak['是'], Wind_weak['否']], index = ['是', '否'])
], index = ['强风', '弱风'])
Wind_df.head()
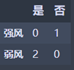
强风:M1 = 0
弱风:M2 = 0
N2 = 0
N1 > N2
所以右边边的节点应用风力属性继续往后分类,决策图如下:

可以看出第二次分类再经过风力的分类之后,此时决策树最后一排的节点全部变为了叶子节点,说明至此,分类完成。
算法实现:
#encoding = utf-8
import numpy as np
import pandas as pd
import operator
def CalcGiNiIndex(DataSet) :
Num_length = len(DataSet)
labelcounts = {}
for feature in DataSet :
currentlabel = feature[-1]
#用字典统计类别及其数目
if currentlabel not in labelcounts.keys() :
labelcounts[currentlabel] = 1
else :
labelcounts[currentlabel] += 1
GiNi_index = 0
for key in labelcounts.keys() :
#二分类求基尼指数:GiNi = 2 * p * (1 - p)
GiNi_index = 2 * (float(labelcounts[key]) / Num_length) * (1 - float(labelcounts[key]) / Num_length)
return GiNi_index
def createDataSet() :
DataSet = [['晴天', '炎热', '高', '弱风', '否'],
['晴天', '炎热', '高', '强风', '否'],
['阴天', '炎热', '高', '弱风', '是'],
['雨天', '温', '高', '弱风', '是'],
['雨天', '冷', '中', '弱风', '是'],
['雨天', '冷', '中', '强风', '否'],
['阴天', '冷', '中', '强风', '是'],
['晴天', '温', '高', '弱风', '否'],
['晴天', '冷', '中', '弱风', '是'],
['雨天', '温', '中', '弱风', '是'],
['晴天', '温', '中', '强风', '是'],
['阴天', '温', '高', '强风', '是'],
['阴天', '炎热', '中', '弱风', '是'],
['雨天', '温', '高', '强风', '否']]
# file = pd.read_excel('Data.xlsx')
# DataSet = file.iloc[ : , 1 : ]
# DataSet = np.array(DataSet)
labels = ['天气', '温度', '湿度', '风力']
return DataSet, labels
def splitDataSet(DataSet, axis, value):
#计算以某个特征分类后剩下的数据量。
#axis表示第i个特征,value表示在改特征的情况下的具体表现,如天气特征有雨天。阴天等。
retDataSet = []
#创建一个新列表,准备提取数据
for featVec in DataSet :
#剔除在数据集中需要被分类的特征的列行
if featVec[axis] == value :
reducedFeatVec = featVec[ : axis]
reducedFeatVec.extend(featVec[axis + 1 : ])
retDataSet.append(reducedFeatVec)
return retDataSet
def ChooseBestFeatureToSplit(DataSet) :
#计算父亲节点的GiNi指数
FatherGiNi = CalcGiNiIndex(DataSet)
BestIoFoGain = 0
BestFeature = -1
numFeature = len(DataSet[0]) - 1
#去掉最后一列
for i in range(numFeature) :
#每个特征下的具体表现形式
featList = [example[i] for example in DataSet]
uniqueVals = set(featList)#去重复
newGiNi = 0
for value in uniqueVals :
#计算每一种表现形式GiNi指数的权重和
subData = splitDataSet(DataSet, i, value)
prob = len(subData) / float(len(DataSet))
newGiNi += prob * CalcGiNiIndex(subData)
infogain = FatherGiNi - newGiNi#计算信息增益
if infogain > BestIoFoGain :
#比较信息增益的大小,更新最佳分类的特征
BestIoFoGain = infogain
BestFeature = i
return BestFeature
def majorityCnt(classList): #按分类后类别数量排序,比如:最后分类为2yes1no,则判定为yes;
classCount={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCount[vote]+=1
#字典逆序排序
sortedClassCount = sorted(classCount.items(), key = lambda x : x[1], reverse=True)
return sortedClassCount[0][0]
def createTree(DataSet, labels) :
ConditionList = [example[-1] for example in DataSet]
#list.count(element) 方法用于统计某个元素在列表中出现的次数。
if ConditionList.count(ConditionList[0]) == len(ConditionList) :#yes or no
return ConditionList[0]
#dataSet[0]取矩阵第一行,dataSet[0][0]取矩阵第一行第一列元素
#递归终止条件2:使用完所有特征,则返回最后出现次数最多的那个标签
if len( DataSet[0] ) == 1:
return majorityCnt(classList)
#以上两个终止条件都不满足,开始选择最优特征划分,已经有了一个方框,准备往方框中写入判断问题
BestFeature = ChooseBestFeatureToSplit(DataSet)
BestFeatLabel = labels[BestFeature]
mytree = {BestFeatLabel : {}}
#用过了该特征,将该特征从所有特征列表中删除
del (labels[BestFeature])
featValues = [example[BestFeature] for example in DataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[ : ]
splitdata = splitDataSet(DataSet, BestFeature, value)
#递归
mytree[BestFeatLabel][value] = createTree(splitdata, subLabels)
return mytree
DataSet, labels = createDataSet()# 创造示列数据
print(createTree(DataSet, labels))# 输出决策树模型结果


















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











