






最简单的方法
直接把资源文件内容用转义的方式弄到字符串类型的变量里,要用的时候直接对这个变量操作即可。
附一个例子:
比如我一个html网页放到我的程序里:
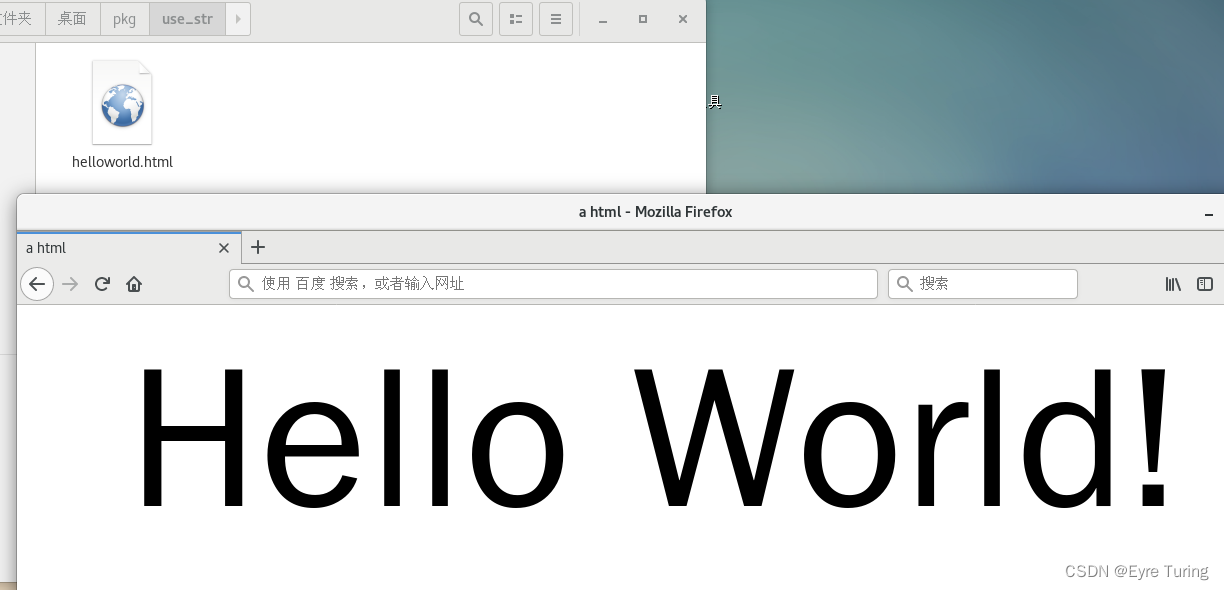
可以用下面的命令获取到任何文件的十六进制转义码(下面helloworld.html是文件名):
hexdump -C helloworld.html | sed -rn 's/[0-9a-f]+ ([^|]*) \|.*/\1/p' | sed -r 's/ ([0-9a-f]{2})/\\x\1/g' | tr -d ' ' | tr -d $'\n'; echo
最后一个echo只是为了换行,我没这么菜,不是不小心多写的echo
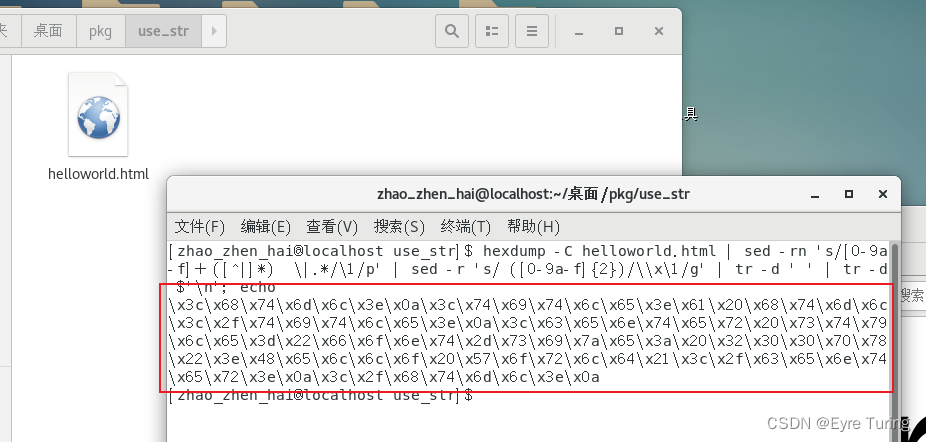
原理挺简单的,就是利用hexdump获取到十六进制编码,然后先这样再这样最后再这样把主要内容提取出来,再在前面加上\x,这样C里就能用了(如果你是用其他语言,对引入十六进制的方法自己简单用sed处理一下就可以了)
然后写一个demo玩玩:
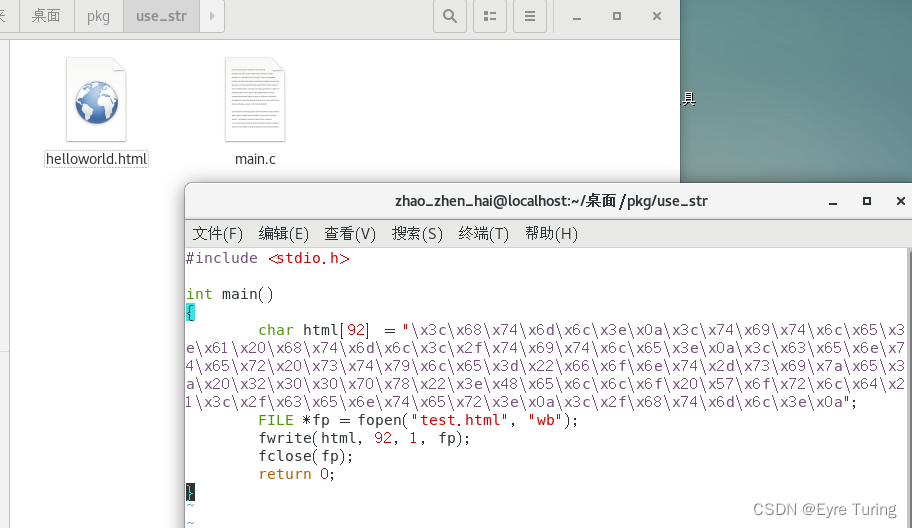
代码挺简单的,至于为什么大小是92,把刚刚输出的东西用wc -l统计字数然后除以4就是了。
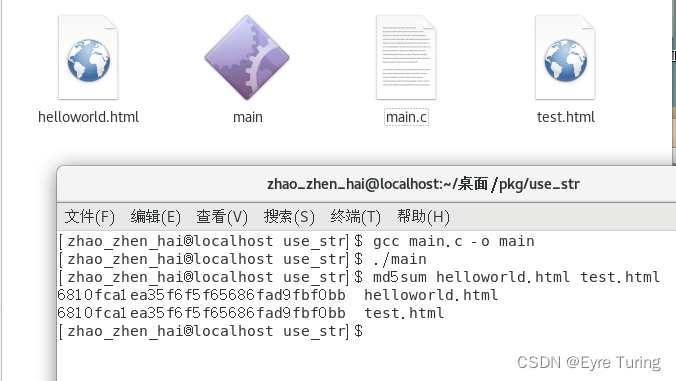
这样就把这个网页加到程序里了,随时可以提取出这个网页来。
这种方式看着是很可行,但是一旦文件大了,问题就暴露出来了,妥妥的是代码里嵌入的文件是真正文件大小的4倍。一张几百K的图片,放进去就好几M了,而且代码可读性还差。所以这种方式只能给小文件用,甚至小文件都不推荐这么插入程序。
动点脑子的方法
我是不是可以把资源文件弄成一个压缩包,然后追加到可执行文件底部呢?
肯定可以啊
shell的方法
先来举个简单的例子,用shell来:
比如我要把我的头像和说明文件放到程序里,到时候好展示个作者信息什么的
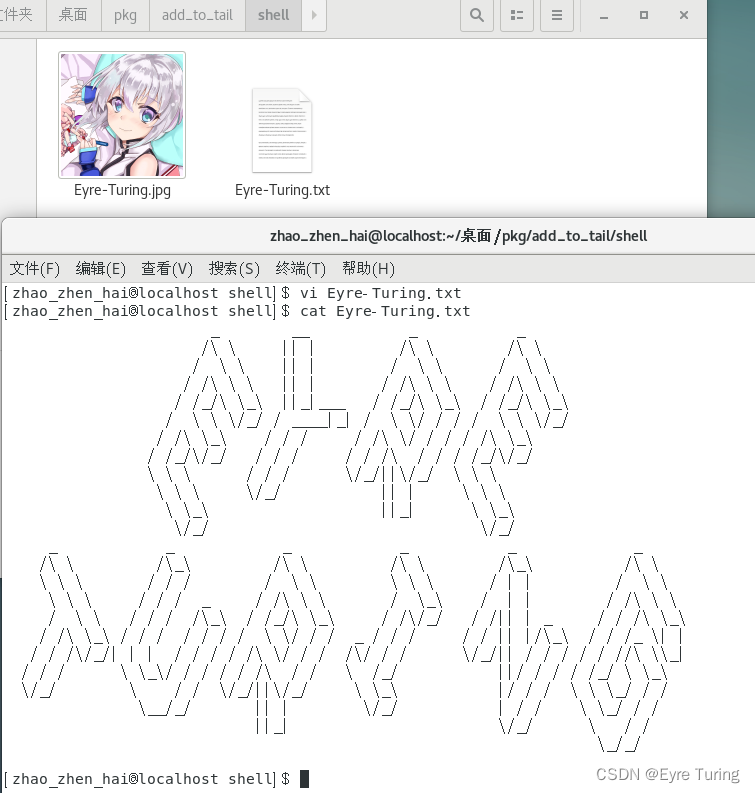
首先打成tar包(不是只能用tar,只是我比较喜欢用tar而已)
tar -cvf data.tar Eyre-Turing.*
然后写个shell脚本,脚本里先预留个结束标签:
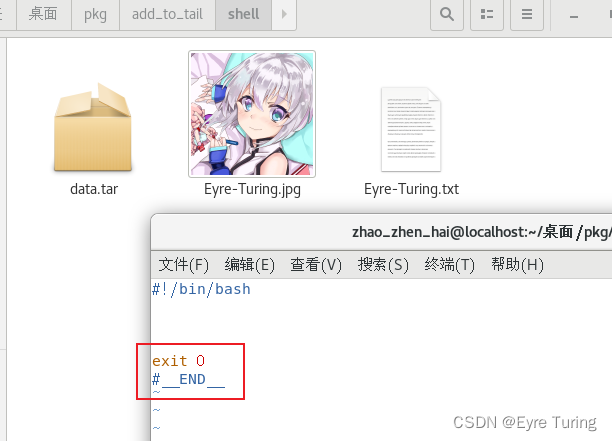
shell脚本最下面的#__END__是为了给你的脚本匹配的,脚本匹配到这个分隔符,把下面的资源文件切出来,然后再用tar的命令,解包就可以用了。
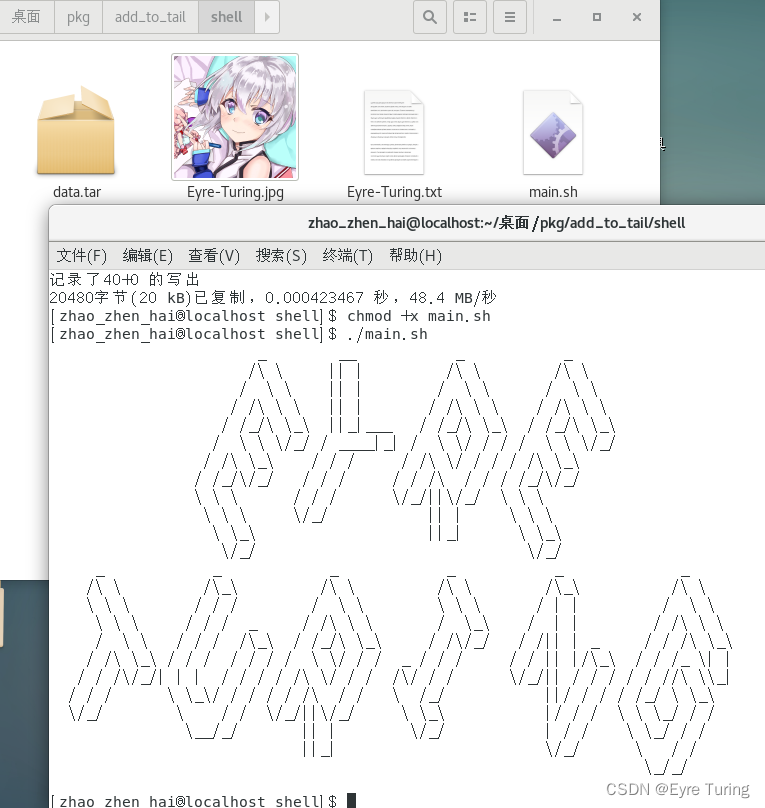
下面做个demo,假设我做个最简单的操作,就是把tar解包出来,然后显示一下我的作者信息:
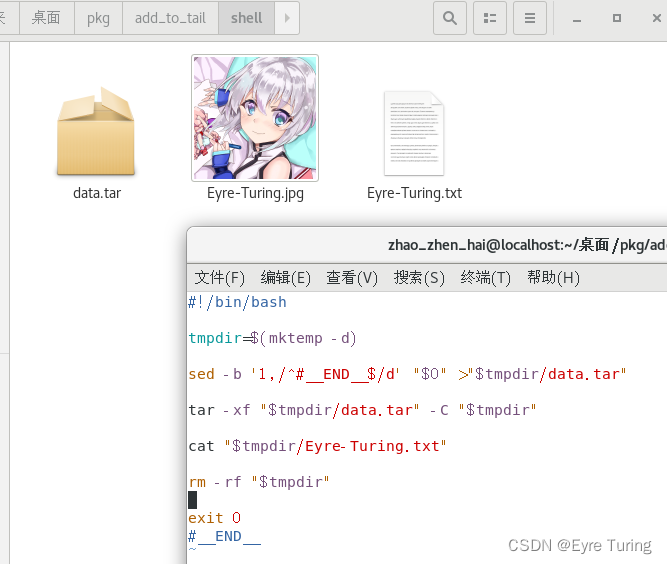
那个sed的作用就是把#__END__后面的内容写到临时文件夹的data.tar里,在假设#__END__后面就是data.tar的内容的情况下,这样写就能在终端输出Eyre-Turing.txt里的内容了(当然这里我没用到图片文件,想用的话也是可以当做资源文件用的)
接下来说一下怎么把data.tar放到#__END__后面,只需要用一个命令(这里的main.sh是我给这个shell脚本的命名):
dd if=data.tar >>main.sh
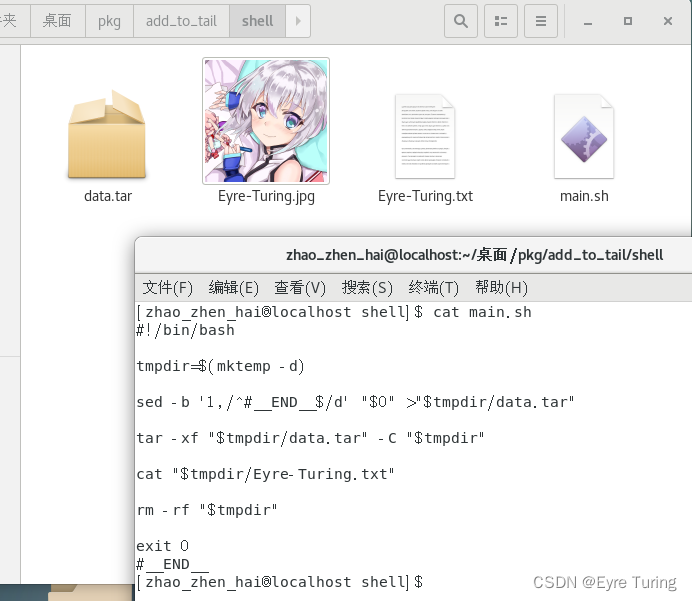
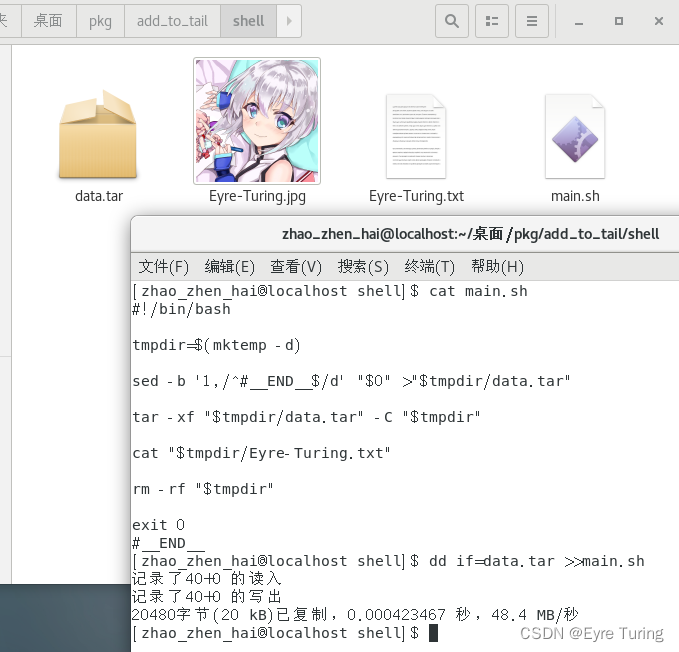
这里引申一个问题:我一不小心加东西前没备份原脚本,那我怎么获取原来的脚本呢?可能我还要换资源文件啥的。最简单的办法就是直接用文本编辑器打开,把前面的内容复制出来。但是直接复制太业余了,这里给个命令,可以直接获取原脚本:
sed -nb '1,/^#__END__$/p' main.sh
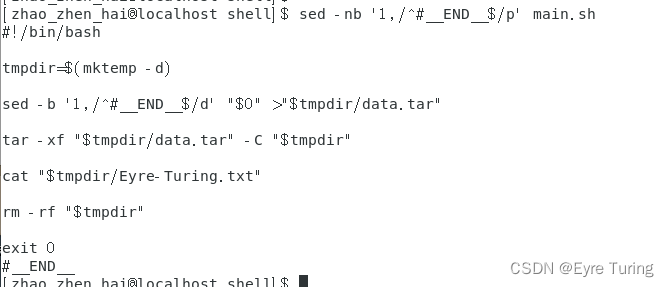
要是sed再加个-i选项的话,就是直接把文件写回去了。
C的方法
C稍微要麻烦一点,可以先把二进制可执行文件编译出来,然后再把文件资源加到后面去。
举个例子:
#include <stdio.h>
void getnextj(const char *magic, int *nextj, size_t len)
{
size_t i = 2, j = 0;
if (len > 0) nextj[0] = -1;
if (len > 1) nextj[1] = 0;
while (i < len) {
if (magic[i - 1] == magic[j]) {
++j;
} else if (j > 0) {
j = nextj[j];
continue;
}
nextj[i] = j;
++i;
}
}
// return index if succeed, return -1 if failed
int indexof(FILE *fp, const char *magic, size_t begin, size_t magiclen)
{
size_t i = begin, j = 0;
int eof = 0;
int nextj[magiclen];
int needread = 1;
if (begin < 0) {
return -1;
}
getnextj(magic, nextj, magiclen);
fseek(fp, 0, SEEK_END);
eof = ftell(fp);
printf("magiclen: %d, eof: %d\n", magiclen, eof);
char buff;
fseek(fp, i, SEEK_SET);
while (i < eof) {
if (needread) {
fread(&buff, 1, 1, fp);
needread = 0;
}
if (buff == magic[j]) {
++i, ++j;
needread = 1;
} else if (nextj[j] < 0) {
++i, j = 0;
needread = 1;
} else {
j = nextj[j];
}
if (j == magiclen) {
return i - magiclen;
}
}
return -1;
}
// return 0 if succeed, return 1 if failed
int unpack(FILE *selffp, FILE *outfp, const char *magic, size_t magiclen)
{
int position = -1;
int eof = -1;
char buff[102400];
size_t n = 0;
size_t size = 0;
printf("magic is: %s\n", magic);
// find magic position
position = indexof(selffp, magic, 0, magiclen);
if (position == -1) {
fprintf(stderr, "magic not found in self file\n");
return 1;
}
position = indexof(selffp, magic, position + magiclen, magiclen);
printf("magic position is: %d\n", position);
if (position == -1) {
fprintf(stderr, "magic not found in self file\n");
return 1;
}
// copy selffp (from magic position to eof) to outfp
fseek(selffp, 0, SEEK_END);
eof = ftell(selffp);
if (eof == -1) {
fprintf(stderr, "can not get self file size\n");
return 1;
}
fseek(selffp, position, SEEK_SET);
position = ftell(selffp);
if (position == -1) {
fprintf(stderr, "can not seek to magic position\n");
return 1;
}
size = eof - position;
while (size) {
fread(buff, sizeof(buff), 1, selffp);
if (size > sizeof(buff)) {
n = fwrite(buff, sizeof(buff), 1, outfp);
size -= sizeof(buff);
} else {
n = fwrite(buff, size, 1, outfp);
size = 0;
}
if (n != 1) {
fprintf(stderr, "write data failed\n");
return 1;
}
}
return 0;
}
int main(int argc, char *argv[])
{
FILE *selffp = NULL;
FILE *outfp = NULL;
if (argc < 2) {
printf("param need output filename\n");
return 1;
}
selffp = fopen(argv[0], "rb");
outfp = fopen(argv[1], "wb");
printf("selffp: %p, outfp: %p\n", selffp, outfp);
unpack(selffp, outfp, "\xfd\x37\x7a\x58\x5a", 5);
fclose(selffp);
fclose(outfp);
return 0;
}
这个是一个简单的例子,因为C不是解释型语言,不能像shell那样用分隔符把资源文件隔开,所以我是用压缩包魔数的方式获取资源文件的起始位置的。
我这个例子的情况是这样的:
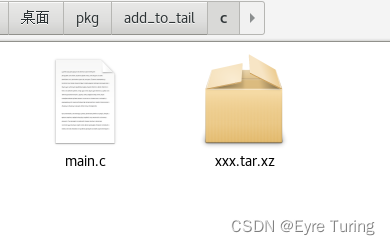
把xxx.tar.xz当资源文件,main.c的内容在上面贴出来了,就是根据xz文件的魔数来获取压缩包在可执行文件里的起始位置的。
gcc main.c -o main
dd if=xxx.tar.xz >>main
这样就可以完成打包了:
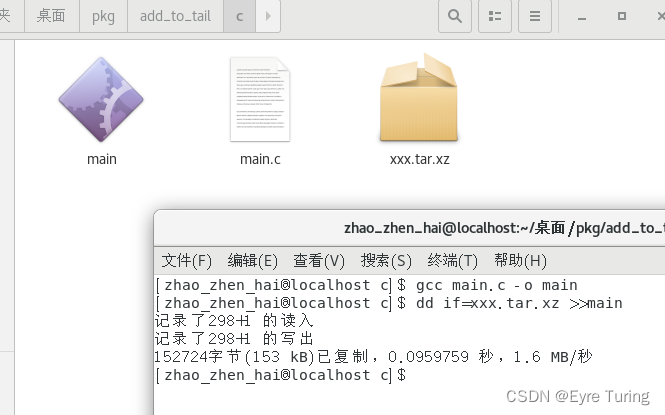
执行main就可以把资源文件放出来了,这里我给放出来的文件命名是out.tar.xz
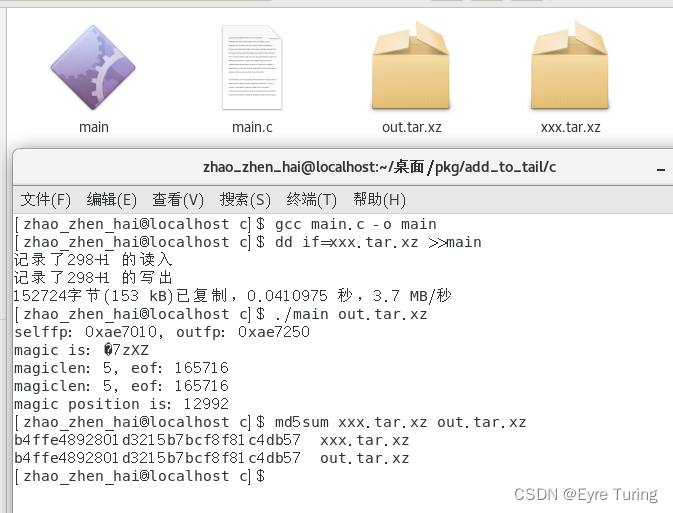
至于压缩文件的魔数,可以用hexdump获取到:
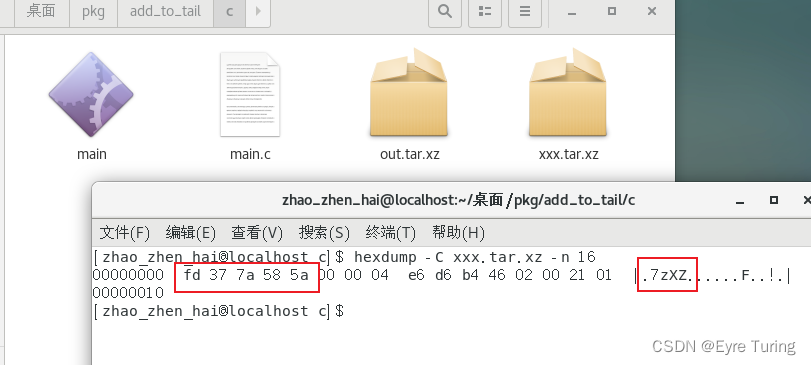
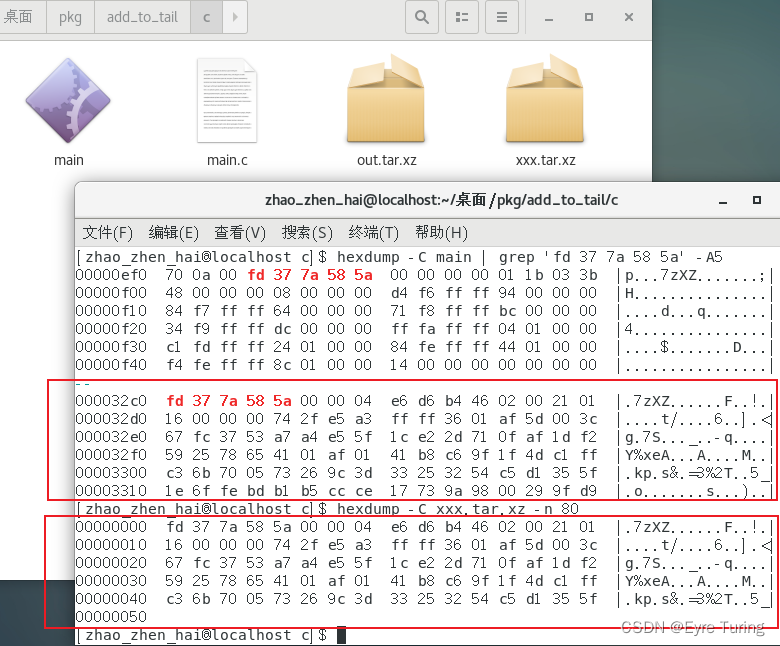
取前几个就行了,但是代码里要注意,因为把资源文件写出来需要指定魔数,所以是要获取第二次出现的魔数才是真正的压缩包起始位置:
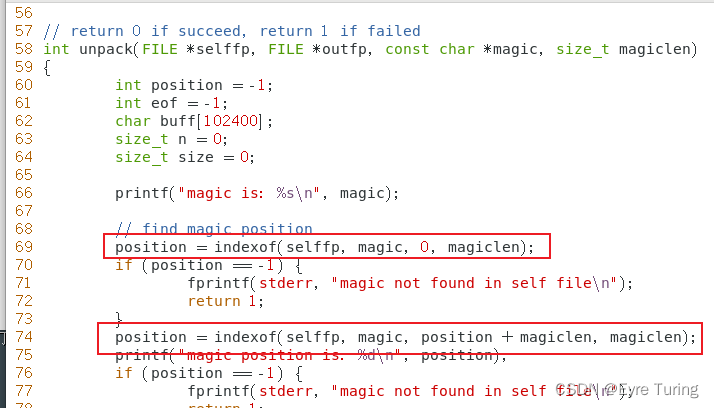
用hexdump也看得出来,很明显从第二次出现的魔数位置开始才是压缩包里的内容:
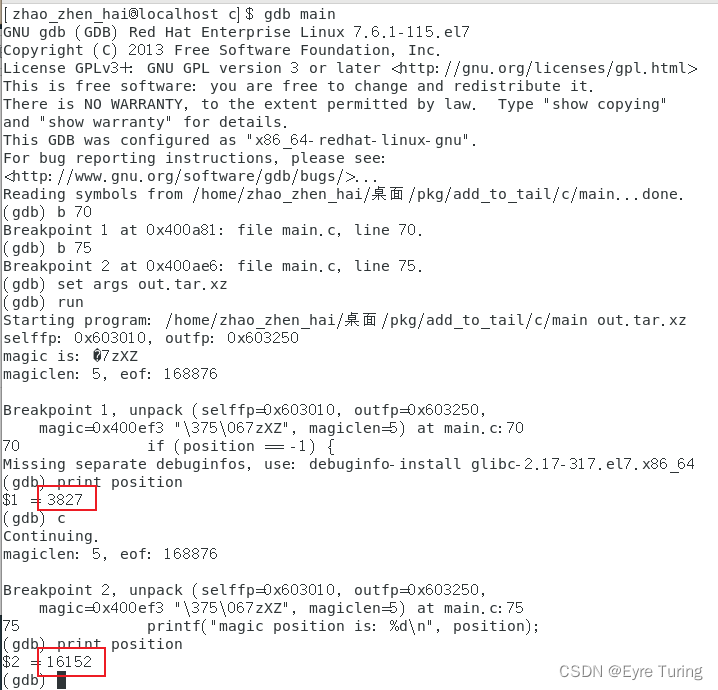
开调试模式以理服人:
gcc -g main.c -o main
dd if=xxx.tar.xz >>main
gdb main
> b 70
> b 75
> set args out.tar.xz
> run
> print position
> c
> print position
这样我们得到了两次position的值,那再看看hexdump是怎么说的(因为开了调试模式,重新编译了一遍,所以不能用之前的文件hexdump出来的东西说事):
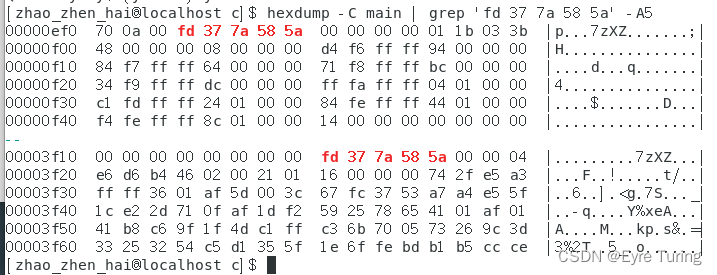
第一个position的位置应该是0xef0+3(十进制就是3824+3=3827),这和程序里获取到的是一样的。
第二个position的位置是0x3f10+8(十进制就是16144+8=16152),这和程序里获取到的也是一样的。而且对比后面的数据会发现就是xxx.tar.xz里的内容。
高手的玩法
文件挪来挪去的,成何体统,高手肯定是用官方的方法:
先介绍一个命令:ld
ld -r -b binary 你的文件(可多个) -o 输出的obj文件
举个简单的例子:
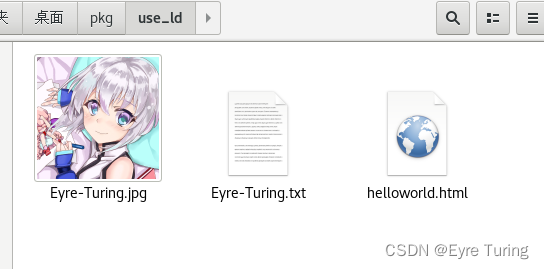
我想把这三个文件放到资源文件里:
ld -r -b binary * -o res.o
然后用命令查看这几个文件加到res.o里是用什么变量保存的:
objdump -t res.o
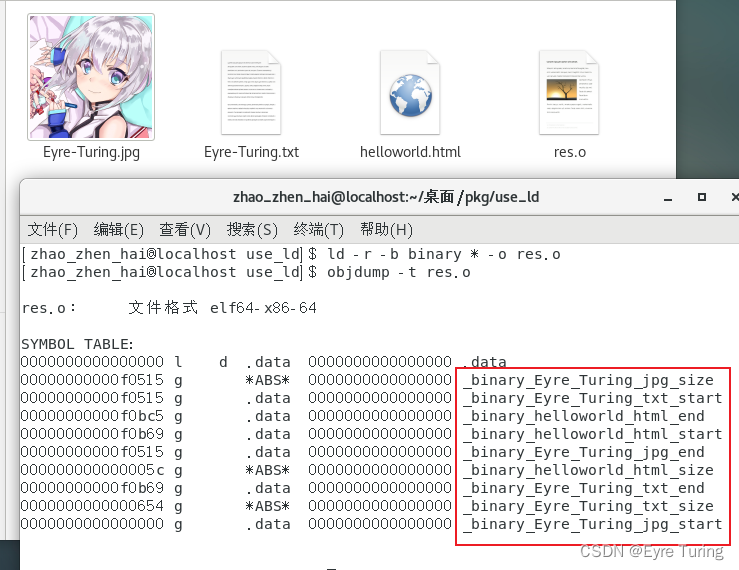
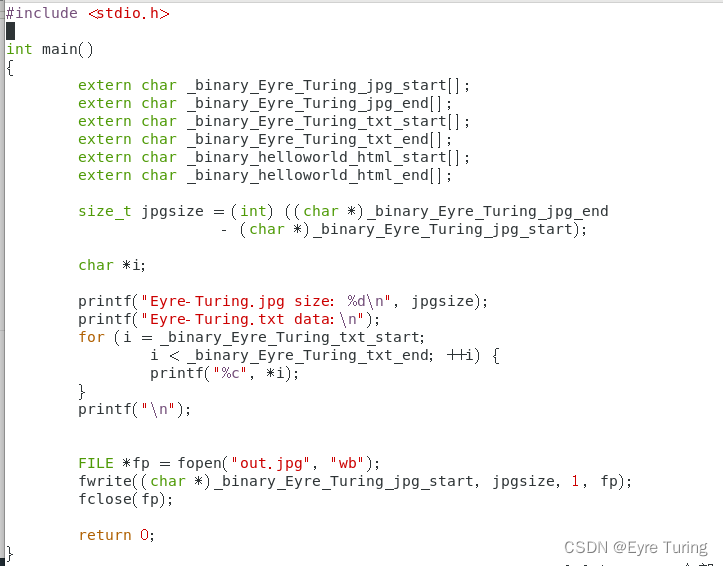
所以只需要在C里用extern把这几个char []都声明一下就可以用了,是不是很简单呢?
火速实操:
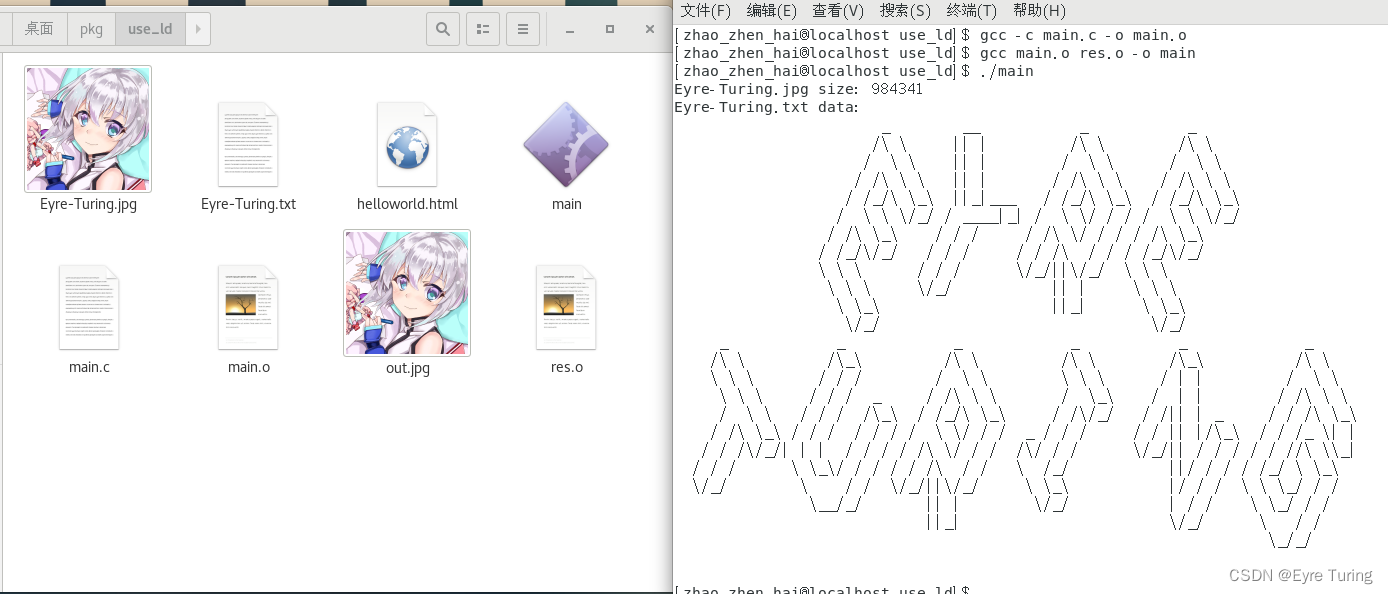
写完代码不说怎么编译的都是耍流氓(下面的文件名都是对于我这个例子的):
gcc -c main.c -o main.o
gcc main.o res.o -o main
为什么不能多种方法结合起来呢
内嵌适合小文件,并且快速;尾部追加适合大文件,只是稍微比较慢且不够灵活。
如果,我是说如果,一个程序需要加载大文件,但是,大文件可能需要某种小工具才能解开,这样就可以内嵌小工具,大文件追加到尾部。
又或者,一个安装包,很大,几十G;其中有一些作者信息、使用说明等文档。作者信息和使用文档可以内嵌,内嵌在运行时是会加载到内存里的,读取出来是很快速的。实际安装的内容,追加到尾部,因为这些内容内存吃不起。追加的内容一般是一次性全部解包放在临时文件夹里,如果把使用说明也放里面那就。。打开一个使用说明得把整个包解出来。。用户体验。。只能说能用吧。。















 1551
1551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









