







一:目的
用配置好的Windows版本Caffe(no GPU),使用caffe自带的ImageNet网络结构进行训练和测试。训练自己的数据;
用caffe团队采用imagenet图片进行训练的参数结果,进行迁移学习;
二:训练与测试
1. 数据集下载与处理
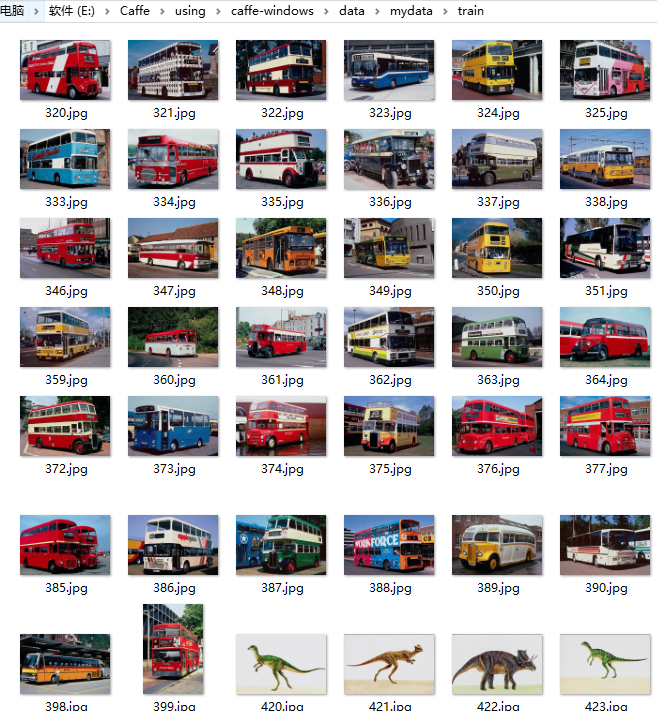
(1) 下载数据集。这里找了一份网上的数据集,共有500张图片,分为大巴车、恐龙、大象、鲜花和马五个类,每个类100张。编号分别以3,4,5,6,7开头,各为一类。我从其中每类选出20张作为测试,其余80张作为训练。因此最终训练图片400张,测试图片100张,共5类。
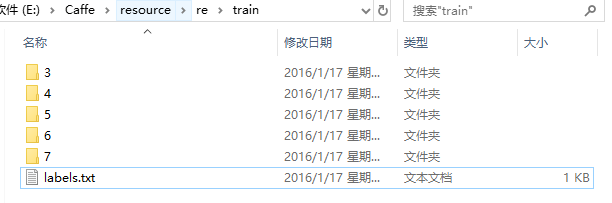
其中,训练和测试的输入是用train.txt和val.txt描述的,这些文档列出所有文件和他们的标签。下载完成后,文件的组织形式如下。
(2) 在caffe-windows\data文件夹下新建mydata文件夹,在该文件夹分别新建train和test两个目录,将下载文件夹中的数据拷贝其中。在这里,我将3,4,5,6,7文件夹中的数据全部取出放到了train和test文件夹,如图所示。
(3) 编写脚本文件,在caffe-windows\data\mydata文件夹下分别生成train.txt和test.txt
import os if __name__ == "__main__": data_dir = 'E:/Caffe/using/caffe-windows/data/mydata/train/' fid = open("E:/Caffe/using/caffe-windows/data/mydata/train2.txt","w") files = os.listdir(data_dir) index = 0 for ii, file in enumerate(files,1): fid.write("{0}{1}\t{2}\n".format("train/",file, int(file[0])-3)) index = index + 1 if index%100 == 0: print("{0} images processed!".format(index)) print("All images processed!") fid.close()
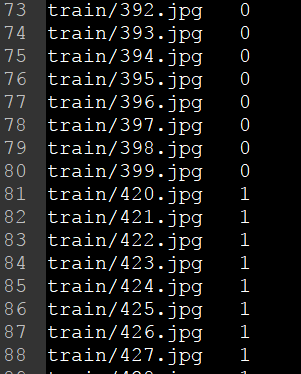
通过上述脚本可以生成对应的train.txt和test.txt(位于caffe-windows\data\mydata文件夹下),文件内容如下
值得注意的是,我在这里将3,4,5,6,7分类转成了0,1,2,3,4分类,这是为了后续train_val.prototxt的修改,这里也可以按照3,4,5,6,7进行分类,不过后续的内容需要进行相应的调整。(4) 新建caffe-windows\mybat\mydata文件夹,在该文件夹下新建mydata_convention.bat,对数据进行转换,内容如下
..\..\Build\x64\Release\convert_imageset.exe --resize_height=256 --resize_width=256 --shuffle --backend=leveldb ..\..\data\mydata\ ..\..\data\mydata\train.txt ..\..\data\mydata\trainldb ..\..\Build\x64\Release\convert_imageset.exe --resize_height=256 --resize_width=256 --shuffle --backend=leveldb ..\..\data\mydata\ ..\..\data\mydata\test.txt ..\..\data\mydata\valldb pause
其中,resize_height和resize_width表示将原图像resize为相应的大小,选择256是因为我们选取的网络(ImageNet)的要求,shuffle是将数据随机打乱的意思,backend表示将数据转换的格式,之前文章介绍过,这里不再介绍了。双击运行后,在caffe-windows\data\mydata下生成对应的trainldb和valldb
(5) 在caffe-windows\mybat\mydata文件夹下新建mydata_mean.bat,生成对应的均值文件。
..\..\Build\x64\Release\compute_image_mean ..\..\data\mydata\trainldb --backend=leveldb ..\..\data\mydata\train_mean.binaryproto ..\..\Build\x64\Release\compute_image_mean ..\..\data\mydata\valldb --backend=leveldb ..\..\data\mydata\val_mean.binaryproto pause
其中backend要与步骤(4)中保持一致,运行完成后,会在caffe-windows\data\mydata文件夹下生成train_mean.binaryproto和val_mean.binaryproto文件
2. 训练数据
首先将caffe-windows\models\bvlc_reference_caffenet文件夹下的deploy.prototxt、solver.prototxt和train_val.prototxt拷贝到caffe-windows\data\mydata下。
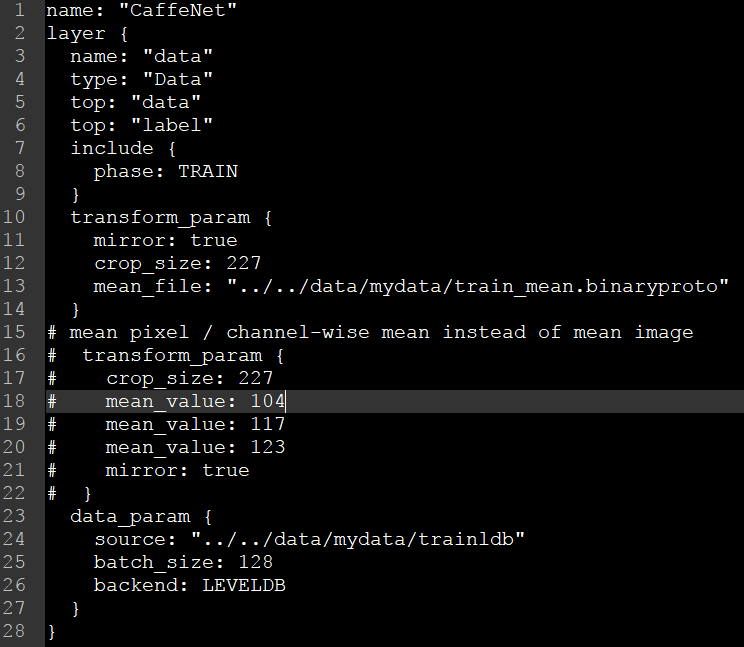
(1) 训练模型文件(train_val.prototxt)的配置
在这里对trian文件进行修改,主要有source,batch_size,backend和mean_file,其中batch_size这里我设置的较小,如果计算机配置较高,可以设大一点,训练结果会稍微好一些。
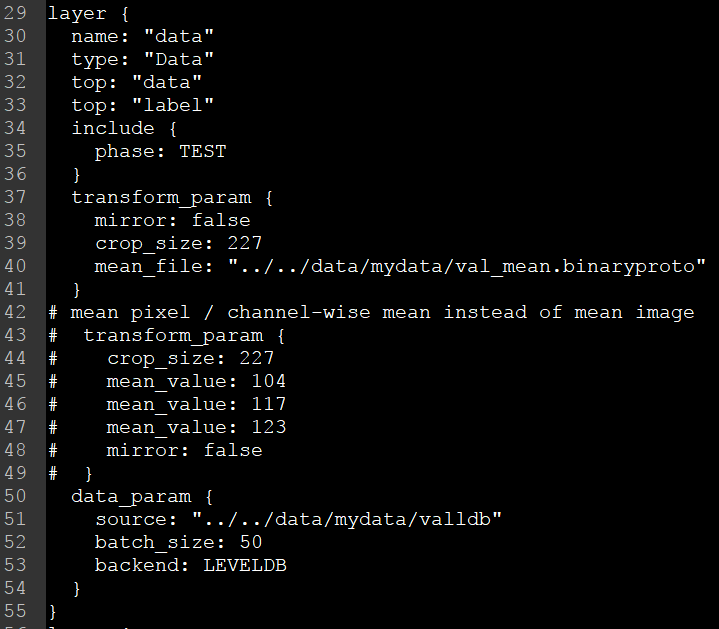
在这里对test文件进行修改,主要有source,batch_size,backend和mean_file。
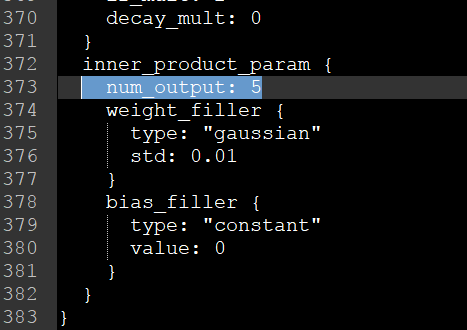
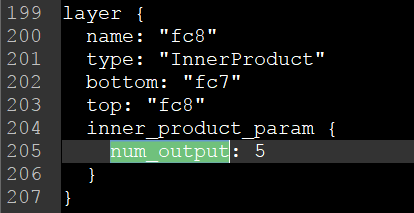
在文件的最后,对num_output进行修改,因为我前面将其改为了0,1,2,3,4分类,所以这里写5就可以,因为它是从0开始计算的,所以如果保留3,4,5,6,7分类,这里至少要为8,否则会出错。其实这里的1000分类也可以不进行改动,但对应需要调整的地方就是最后的label.txt。
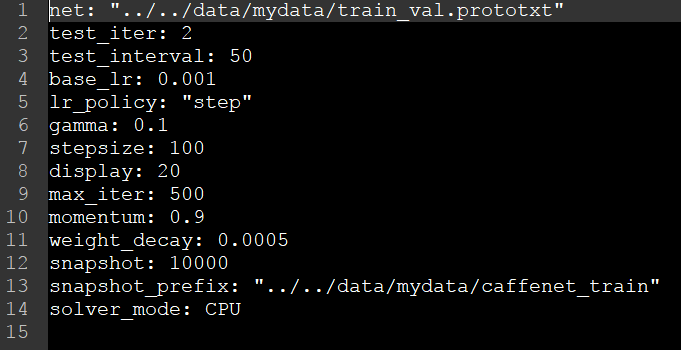
(2) 训练参数文件(solver.prototxt)的配置
主要修改net,snapshot_prefix和solver_mode三个参数,其余参数的修改可以参照之前的博客。
(3) 在 caffe-windows\mybat\mydata文件夹下新建mydata_train.bat,对数据进行训练,内容如下
..\..\Build\x64\Release\caffe.exe train --solver=..\..\data\mydata\solver.prototxt pause
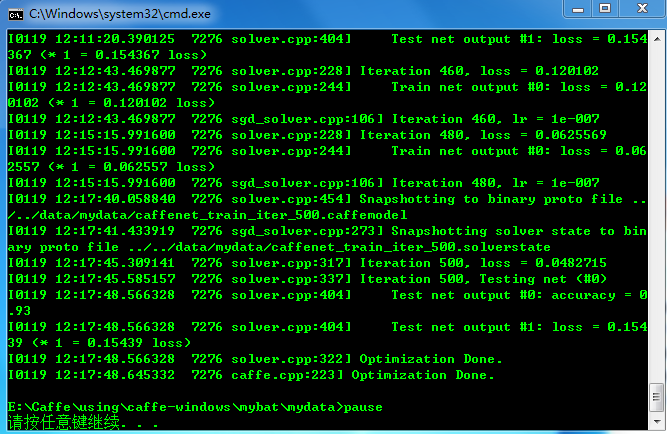
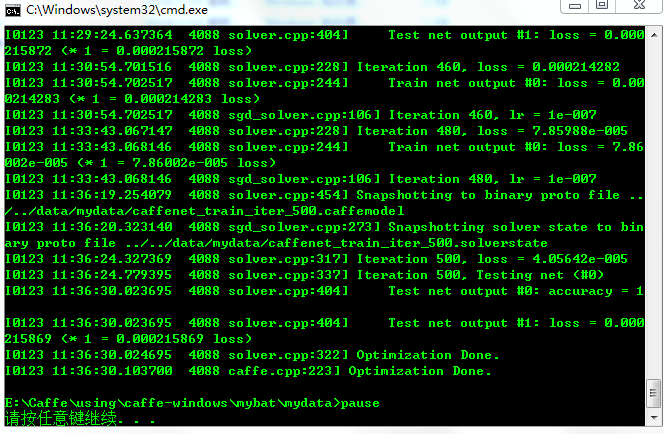
双击运行,运行结束后结果如下
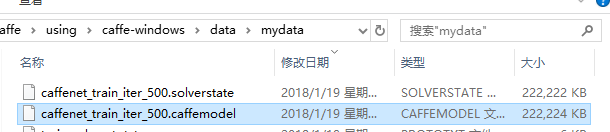
可以看到能达到93%的正确率,其实将train_val.prototxt文件中train部分的batch_size改为256可以达到95%左右的正确率。运行结束后,在caffe-windows\data\mydata文件夹下会生成caffenet_train_iter_500.solverstate和caffenet_train_iter_500.caffemodel文件,其中solvestate文件是状态恢复文件,如果因为一些原因我们中断了训练,下次想从中断的地方继续进行训练,可以通过--snapshot=xxx.solverstate命令进行继续训练。
3. 测试
(1) 修改E:\Caffe\using\caffe-windows\data\mydata\deploy.prototxt文件,因为我们之前的num_output为5,这里也将其改为5
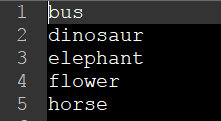
(2) 在caffe-windows\data\mydata文件夹下新建labels.txt文件,内容为以上五类目标的英文名。
(3) 在caffe-windows\mybat\mydata文件夹新建mydata_test.bat,对图像进行测试,内容如下
..\..\Build\x64\Release\classification ..\..\data\mydata\deploy.prototxt ..\..\data\mydata\caffenet_train_iter_500.caffemodel ..\..\data\mydata\val_mean.binaryproto ..\..\data\mydata\labels.txt ..\..\data\mydata\test\500.jpg pause
500.jpg如下
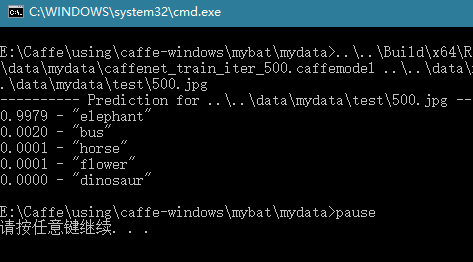
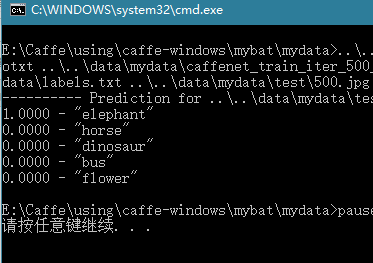
检测结果如下:
检测出来的也是大象,finished!


三:迁移学习
有时候我们进行训练的图像较少,收敛速度较慢,并且有时候还难以收敛,达不到我们想要的效果。此时,可以利用别的用户之前训练好的数据进行fine-tuning,借用训练好的参数,往往可以更快的收敛,达到较好的训练效果。在这里,我们对第二章节的训练进行迁移学习。
(1) 下载model参数
在这里,我们选用了一组caffe团队用imagenet图片进行训练,迭代30多万次,训练出来的一个model。这个model将图片分为1000类,应该是目前为止最好的图片分类model了。
下载地址为:http://dl.caffe.berkeleyvision.org/bvlc_reference_caffenet.caffemodel
文件名称为:bvlc_reference_caffenet.caffemodel,文件大小为230M左右,将这个caffemodel文件下载到caffe-windows\data\mydata文件夹下。
(2) 在caffe-windows\data\mydata文件夹下,将第二章节中用到的train_val.prototxt和solver.prototxt备份一下,分别重命名为train_val_transform.prototxt和solver_transform.prototxt。
在train_val_transform.prototxt中,修改其fc8层为fc8_re,在solver_transform.prototxt,修改对应的train_val_transform.prototxt路径
(3) 在caffe-windows\mybat\mydata文件夹下新建mydata_train_with_weights.bat,内容如下
..\..\Build\x64\Release\caffe.exe train --solver=..\..\data\mydata\solver_transform.prototxt --weights=..\..\data\mydata\bvlc_reference_caffenet.caffemodel pause
双击运行即可,可以看出来,收敛速度较快
运行结束后同样在caffe-windows\data\mydata文件夹下生成caffenet_train_iter_500.solverstate和caffenet_train_iter_500.caffemodel文件
准确率达到了1,也可能跟我们的测试数据不多有关系,不过准确率的确提高了不少。
(4) 测试
备份caffe-windows\data\mydata\deploy.prototxt,将备份文件重命名为caffe-windows\data\mydata\deploy_transform.prototxt,修改其对应的name为fc8_re
在caffe-windows\mybat\mydata文件夹下新建mydata_test_transform.bat,内容如下
..\..\Build\x64\Release\classification ..\..\data\mydata\deploy_transform.prototxt ..\..\data\mydata\caffenet_train_iter_500.caffemodel ..\..\data\mydata\val_mean.binaryproto ..\..\data\mydata\labels.txt ..\..\data\mydata\test\500.jpg pause
测试准确率更高!
finished! enjoy!
参考:

















 120
120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









