







前面已经介绍过原生的Django框架,那么为何又引进了DRF(DjangoRestFramework)模型了?主要有两点原因:1.加入了Restful设计风格,让API的设计更加规范;2.在前后端数据交流的时候有大量重复的操作,比如讲查询类型转化成json或者将json类型转化成字典等。引入DRF之后我们都不用重复这些操作,可以直接引用serializers,以及更加方便的GenericViewSet帮助我们做查询,简单讲引入DRF之后代码会更规范,开发效率更高级。
Restful设计风格
1.域名:应尽量将域名放在专有域名之下,如;
https://api.example.com
2.版本:应尽量将API版本号放入到URL当中,方便版本更新,如;
http://www.example.com/api/1.0/foo
http://www.example.com/api/1.1/foo
3.路径:路径作为资源的集合,最好不要出现动词,只能有名词,名词最好和数据库的表明相对应,且名词最好以复数的形式出现,如:
GET /products :将返回所有产品清单
POST /products :将产品新建到集合
GET /products/4 :将获取产品 4
PATCH(或)PUT /products/4 :将更新产品 4
获取单个产品:http://127.0.0.1:8080/AppName/rest/products/1
获取所有产品: http://127.0.0.1:8080/AppName/rest/products
4.Http动词:不同的动词代表不同的请求含义,post:新建资源,get:获取资源,put:更新资源,delete:删除资源,head:获取资源的元数据,options:获取信息,关于资源的哪些属性是客户端可以改变的
5.过滤信息:如果请求资源过多,服务器不可能一次性将所有的数据全部返回给客户端,API应该提供参数,过滤返回结果,例举一下常见的参数:
?limit=10:指定返回记录的数量
?offset=10:指定返回记录的开始位置。
?page=2&per_page=100:指定第几页,以及每页的记录数。
?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
?animal_type_id=1:指定筛选条件
6.状态码:参考doc:(https://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html)
7.错误信息处理:不同的状态码出错应该指明错误原因,如果状态码是4xx,服务器就应该向用户返回出错信息。一般来说,返回的信息中将error作为键名,出错信息作为键值即可。如;
{
error: "Invalid API key"
}
8.结果返回:针对不同的HTTP操作,服务器返回的结果集应该符合一下规范;
GET /collection:返回资源对象的列表(数组)
GET /collection/resource:返回单个资源对象
POST /collection:返回新生成的资源对象
PUT /collection/resource:返回完整的资源对象
PATCH /collection/resource:返回完整的资源对象
DELETE /collection/resource:返回一个空文档
9.超媒体链接:RESTful API最好做到Hypermedia(即返回结果中提供链接,连向其他API方法),使得用户不查文档,也知道下一步应该做什么,相当于路标一样,你请求什么资源就会提示你访问什么路径
序列化和反序列化
在前后端数据交流中做多的操作主要有一下三种:
1.将请求的数据(如JSON格式)转换为模型类对象 2.操作数据库 3.将模型类对象转换为响应的数据(如JSON格式)我们称上面的1和3分别为序列化和反序列化
序列化:将程序中的一个数据结构类型转换为其他格式(字典、JSON、XML等),例如将Django中的模型类对象装换为JSON字符串,这个转换过程我们称为序列化。如在前端请求数据的时候我们就得将查询数据转化成前端所需要的数据格式,这就是序列化
反序列化:直白将就是将json等其他非标准数据结构类型转换成标准的数据结构类型,如保存数据的时候我们将前端传来的json数据类型转换成dict然后再转换成queryset保存到数据库,就是反序列化。
DRF的特点:
提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化;
提供了丰富的类视图、Mixin扩展类,简化视图的编写;
丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要;
多种身份认证和权限认证方式的支持;内置了限流系统;
DRF工程搭建
1.安装DRF
pip install djangorestframework
2.我们利用在Django框架学习中创建的demo工程,在settings.py的INSTALLED_APPS中添加’rest_framework’。
3.创建一个最简单的序列化器
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = '__all__'
4.编写视图函数
from rest_framework.viewsets import ModelViewSet
from .serializers import BookInfoSerializer
from .models import BookInfo
class BookInfoViewSet(ModelViewSet):
queryset = BookInfo.objects.all() #queryset 指明该视图集在查询数据时使用的查询集
serializer_class = BookInfoSerializer #指明该视图在进行序列化或反序列化时使用的序列化器
5.定义路由
from . import views
from rest_framework.routers import DefaultRouter
urlpatterns = [
...
]
router = DefaultRouter() # 可以处理视图的路由器
router.register('books', views.BookInfoViewSet, name='books') # 向路由器中注册视图集
urlpatterns += router.urls # 将路由器中的所以路由信息追到到django的路由列表中
6.运行,会发现短短的一个视图函数居然会支持增删查改四个方法,且查的时候支持单资源和复资源
Serializer序列化器
定义序列化器:
serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。serializer是独立于数据库之外的存在,因此存在两张序列化器的定义方法
首先是最原始的定义法:
#假设我们已经存在一个数据库模型
class BookInfo(models.Model):
btitle = models.CharField(max_length=20, verbose_name='名称')
bpub_date = models.DateField(verbose_name='发布日期', null=True)
bread = models.IntegerField(default=0, verbose_name='阅读量')
bcomment = models.IntegerField(default=0, verbose_name='评论量')
image = models.ImageField(upload_to='booktest', verbose_name='图片', null=True)
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label='ID', read_only=True)
btitle = serializers.CharField(label='名称', max_length=20)
bpub_date = serializers.DateField(label='发布日期', required=False)
bread = serializers.IntegerField(label='阅读量', required=False)
bcomment = serializers.IntegerField(label='评论量', required=False)
image = serializers.ImageField(label='图片', required=False)
定义序列化器和建立数据库模型类似,都有自己的字段,通用参数以及选项参数
常用的选项参数:

常用的通用参数:

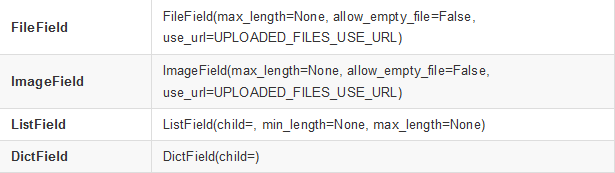
常用的字段名;

在上述模型和序列化器之间其实并无直接的关联,只是对应的字段名相同!这种其实工作中用的比较少,最常用的还是模型类序列化器:
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = '__all__'
model就是指明需要序列化的模型名称,fields就是指明需要序列化模型中的哪些字段,比如我们详细指明需要序列化的字段:
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date')
也可以用exclude来直接排除不需要序列化得字段
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
exclude = ('image',)
可以通过read_only_fields指明只读字段,即仅用于序列化输出的字段
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date', 'bread', 'bcomment')
read_only_fields = ('id', 'bread', 'bcomment') #仅用于序列化输出
如果在定义序列化器的时候发现原有模型的数据或者数据类型不对,我们可以直接在序列化得时候增加参数extra_kwargs 来修改
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date', 'bread', 'bcomment')
extra_kwargs = {
'bread': {'min_value': 0, 'required': True},
'bcomment': {'min_value': 0, 'required': True},
}
创建序列化器对象
定义好序列化器之后就可以创建序列化对象,序列化对象的构造方法如下:
Serializer(instance=None, data=empty, **kwarg)
1)用于序列化时,将模型类对象传入instance参数
2)用于反序列化时,将要被反序列化的数据传入data参数
3.序列化的基本使用:
先查图书对象
from booktest.models import BookInfo
book = BookInfo.objects.get(id=2)
再构造序列化器对象:
from booktest.serializers import BookInfoSerializer
serializer = BookInfoSerializer(book)
最后获取序列化数据
erializer.data
如果被序列的对象包含多个数据,那么我们需要额外增加一个many参数
book_qs = BookInfo.objects.all()
serializer = BookInfoSerializer(book_qs, many=True)
serializer.data
关联对象嵌套序列化
如果需要序列化的数据中包含有其他关联对象,则对关联对象数据的序列化需要指明。
例如,在定义英雄数据的序列化器时,外键hbook(即所属的图书)字段如何序列化?
我们先定义HeroInfoSerialzier除外键字段外的其他部分
class HeroInfoSerializer(serializers.Serializer):
"""英雄数据序列化器"""
GENDER_CHOICES = (
(0, 'male'),
(1, 'female')
)
id = serializers.IntegerField(label='ID', read_only=True)
hname = serializers.CharField(label='名字', max_length=20)
hgender = serializers.ChoiceField(choices=GENDER_CHOICES, label='性别', required=False)
hcomment = serializers.CharField(label='描述信息', max_length=200, required=False, allow_null=True)
hbook = ....#需要序列化的关联字段
对于关联字段,可以采用以下几种方式:
1.PrimaryKeyRelatedField
hbook = serializers.PrimaryKeyRelatedField(label='图书', queryset=BookInfo.objects.all())
2.使用关联对象的序列化器
比如hero关联对象是book,我们就可以直接使用book的序列化器
hbook = BookInfoSerializer()
3.使用StringRelatedField。此字段将被序列化为关联对象的字符串表示方式(即__str__方法的返回值)
hbook = serializers.StringRelatedField(label='图书')
如果关联对象包含的数据有多个怎么办?和上面的解决方法一样,我们在使用的序列化方法后面加一个many = True即可
视图
Request与Response
1. Request
REST framework 传入视图的request对象不再是Django默认的HttpRequest对象,而是REST framework提供的扩展了HttpRequest类的Request类的对象。
REST framework 提供了Parser解析器,在接收到请求后会自动根据Content-Type指明的请求数据类型(如JSON、表单等)将请求数据进行parse解析,解析为类字典对象保存到Request对象中。
Request对象的数据是自动根据前端发送数据的格式进行解析之后的结果。
无论前端发送的哪种格式的数据,我们都可以以统一的方式读取数据
1).data
request.data 返回解析之后的请求体数据。类似于Django中标准的request.POST和 request.FILES属性,但提供如下特性:
包含了解析之后的文件和非文件数据
包含了对POST、PUT、PATCH请求方式解析后的数据
利用了REST framework的parsers解析器,不仅支持表单类型数据,也支持JSON数据
.query_params
request.query_params与Django标准的request.GET相同,只是更换了更正确的名称而已。
2. Response
rest_framework.response.Response
REST framework提供了一个响应类Response,使用该类构造响应对象时,响应的具体数据内容会被转换(render渲染)成符合前端需求的类型。
REST framework提供了Renderer 渲染器,用来根据请求头中的Accept(接收数据类型声明)来自动转换响应数据到对应格式。如果前端请求中未进行Accept声明,则会采用默认方式处理响应数据,我们可以通过配置来修改默认响应格式。
REST_FRAMEWORK = {
‘DEFAULT_RENDERER_CLASSES’: ( # 默认响应渲染类
‘rest_framework.renderers.JSONRenderer’, # json渲染器
‘rest_framework.renderers.BrowsableAPIRenderer’, # 浏览API渲染器
)
}
构造方式
Response(data, status=None, template_name=None, headers=None, content_type=None)
data数据不要是render处理之后的数据,只需传递python的内建类型数据即可,REST framework会使用renderer渲染器处理data。
data不能是复杂结构的数据,如Django的模型类对象,对于这样的数据我们可以使用Serializer序列化器序列化处理后(转为了Python字典类型)再传递给data参数
视图说明
1.APIView
rest_framework.views.APIView
APIView是REST framework提供的所有视图的基类,继承自Django的View父类。
支持定义的属性:
authentication_classes 列表或元祖,身份认证类
permissoin_classes 列表或元祖,权限检查类
throttle_classes 列表或元祖,流量控制类
在APIView中仍以常规的类视图定义方法来实现get() 、post() 或者其他请求方式的方法:
from rest_framework.views import APIView
from rest_framework.response import Response
# url(r'^books/$', views.BookListView.as_view()),
class BookListView(APIView):
def get(self, request):
books = BookInfo.objects.all()
serializer = BookInfoSerializer(books, many=True)
return Response(serializer.data)
2.GenericAPIView
rest_framework.generics.GenericAPIView
继承自APIVIew,主要增加了操作序列化器和数据库查询的方法,作用是为下面Mixin扩展类的执行提供方法支持。通常在使用时,可搭配一个或多个Mixin扩展类。
提供的关于序列化器使用的属性与方法:
属性:
serializer_class 指明视图使用的序列化器
方法:
get_serializer_class(self)
get_serializer(self, args, *kwargs)
返回序列化器对象,主要用来提供给Mixin扩展类使用,如果我们在视图中想要获取序列化器对象,也可以直接调用此方法。
提供的关于数据库查询的属性与方法
属性:
queryset 指明使用的数据查询集
方法:
get_queryset(self)
get_object(self)
返回详情视图所需的模型类数据对象,主要用来提供给Mixin扩展类使用。
在试图中可以调用该方法获取详情信息的模型类对象。
若详情访问的模型类对象不存在,会返回404。
举例:
# url(r'^books/(?P<pk>\d+)/$', views.BookDetailView.as_view()),
class BookDetailView(GenericAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
def get(self, request, pk):
book = self.get_object() # get_object()方法根据pk参数查找queryset中的数据对象
serializer = self.get_serializer(book)
return Response(serializer.data)
3.五个扩展类
提供了几种后端视图(对数据资源进行增删改查)处理流程的实现,如果需要编写的视图属于这五种,则视图可以通过继承相应的扩展类来复用代码,减少自己编写的代码量。
这五个扩展类需要搭配GenericAPIView父类,因为五个扩展类的实现需要调用GenericAPIView提供的序列化器与数据库查询的方法。
1)ListModelMixin
列表视图扩展类,提供list(request, *args, kwargs)方法快速实现列表视图,返回200状态码。
该Mixin的list方法会对数据进行过滤和分页。(返回数据集)
2)CreateModelMixin
创建视图扩展类,提供create(request, *args, **kwargs) 方法快速实现创建资源的视图,成功返回201状态码。
如果序列化器对前端发送的数据验证失败,返回400错误(新建数据)
3) RetrieveModelMixin
详情视图扩展类,提供retrieve(request, *args, **kwargs)方法,可以快速实现返回一个存在的数据对象。
如果存在,返回200, 否则返回404。(返回单个数据)
4)UpdateModelMixin
更新视图扩展类,提供update(request, *args, **kwargs)方法,可以快速实现更新一个存在的数据对象。
同时也提供partial_update(request, *args, **kwargs)方法,可以实现局部更新。
成功返回200,序列化器校验数据失败时,返回400错误(更新数据)
5)DestroyModelMixin
删除视图扩展类,提供destroy(request, *args, **kwargs)方法,可以快速实现删除一个存在的数据对象。
成功返回204,不存在返回404(删除数据)
视图集
使用视图集ViewSet,可以将一系列逻辑相关的动作放到一个类中:
list() 提供一组数据
retrieve() 提供单个数据
create() 创建数据
update() 保存数据
destory() 删除数据
ViewSet视图集类不再实现get()、post()等方法,而是实现动作 action 如 list() 、create() 等。
视图集只在使用as_view()方法的时候,才会将action动作与具体请求方式对应上。如:
class BookInfoViewSet(viewsets.ViewSet):
def list(self, request):
books = BookInfo.objects.all()
serializer = BookInfoSerializer(books, many=True)
return Response(serializer.data)
def retrieve(self, request, pk=None):
try:
books = BookInfo.objects.get(id=pk)
except BookInfo.DoesNotExist:
return Response(status=status.HTTP_404_NOT_FOUND)
serializer = BookInfoSerializer(books)
return Response(serializer.data)
设置路由:
urlpatterns = [
url(r'^books/$', BookInfoViewSet.as_view({'get':'list'}),
url(r'^books/(?P<pk>\d+)/$', BookInfoViewSet.as_view({'get': 'retrieve'})
]
1. 常用视图集父类
1) ViewSet
继承自APIView与ViewSetMixin,作用也与APIView基本类似,提供了身份认证、权限校验、流量管理等。
ViewSet主要通过继承ViewSetMixin来实现在调用as_view()时传入字典(如{‘get’:‘list’})的映射处理工作。
在ViewSet中,没有提供任何动作action方法,需要我们自己实现action方法。
2)GenericViewSet
使用ViewSet通常并不方便,因为list、retrieve、create、update、destory等方法都需要自己编写,而这些方法与前面讲过的Mixin扩展类提供的方法同名,所以我们可以通过继承Mixin扩展类来复用这些方法而无需自己编写。但是Mixin扩展类依赖与GenericAPIView,所以还需要继承GenericAPIView。
GenericViewSet就帮助我们完成了这样的继承工作,继承自GenericAPIView与ViewSetMixin,在实现了调用as_view()时传入字典(如{‘get’:‘list’})的映射处理工作的同时,还提供了GenericAPIView提供的基础方法,可以直接搭配Mixin扩展类使用。
例如一个视图实现增删查改;
from rest_framework import mixins
from rest_framework.viewsets import GenericViewSet
from rest_framework.decorators import action
class BookInfoViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
设置路由:
urlpatterns = [
url(r'^books/$', views.BookInfoViewSet.as_view({'get': 'list'})),
url(r'^books/(?P<pk>\d+)/$', views.BookInfoViewSet.as_view({'get': 'retrieve'})),
]
除了最基本的增删改查之外我们可以定义自己的方法,然后在路由的时候映射出来
from rest_framework import mixins
from rest_framework.viewsets import GenericViewSet
from rest_framework.decorators import action
class BookInfoViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
def latest(self, request):
"""
返回最新的图书信息
"""
book = BookInfo.objects.latest('id')
serializer = self.get_serializer(book)
return Response(serializer.data)
def read(self, request, pk):
"""
修改图书的阅读量数据
"""
book = self.get_object()
book.bread = request.data.get('read')
book.save()
serializer = self.get_serializer(book)
return Response(serializer.data)
定义路由:
urlpatterns = [
url(r'^books/$', views.BookInfoViewSet.as_view({'get': 'list'})),
url(r'^books/latest/$', views.BookInfoViewSet.as_view({'get': 'latest'})),
url(r'^books/(?P<pk>\d+)/$', views.BookInfoViewSet.as_view({'get': 'retrieve'})),
url(r'^books/(?P<pk>\d+)/read/$', views.BookInfoViewSet.as_view({'put': 'read'})),
]
在视图集中,我们可以通过action对象属性来获取当前请求视图集时的action动作是哪个:
def get_serializer_class(self):
if self.action == 'create':
return OrderCommitSerializer
else:
return OrderDataSerializer
路由
对于视图集ViewSet,我们除了可以自己手动指明请求方式与动作action之间的对应关系外,还可以使用Routers来帮助我们快速实现路由信息。
REST framework提供了两个router
SimpleRouter
DefaultRouter
1) 创建router对象,并注册视图集,例如
from rest_framework import routers
router = routers.SimpleRouter()
router.register(r'books', BookInfoViewSet, base_name='book')
register(prefix, viewset, base_name)#路由前缀,视图集,路由名称的前缀
上述代码会形成如下路由:
^books/$ name: book-list
^books/{pk}/$ name: book-detail
2)添加路由数据
urlpatterns = [
...
url(r'^', include(router.urls))
]
认证,权限,限流,分页,过滤
认证 authentication_classess
可以在配置文件中配置全局默认的认证方案
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': (
'rest_framework.authentication.BasicAuthentication', # 基本认证
'rest_framework.authentication.SessionAuthentication', # session认证
)
}
也可以在每个视图中通过设置authentication_classess属性来设置
from rest_framework.authentication import SessionAuthentication, BasicAuthentication
from rest_framework.views import APIView
class ExampleView(APIView):
authentication_classes = (SessionAuthentication, BasicAuthentication)
...
权限 permission_classes
可以在配置文件中设置默认的权限管理类,如
REST_FRAMEWORK = {
'DEFAULT_PERMISSION_CLASSES': (
'rest_framework.permissions.IsAuthenticated',
)
}
如果未指明,则采用如下默认配置
'DEFAULT_PERMISSION_CLASSES': (
'rest_framework.permissions.AllowAny',
)
也可以在具体的视图中通过permission_classes属性来设置,如
from rest_framework.permissions import IsAuthenticated
from rest_framework.views import APIView
class ExampleView(APIView):
permission_classes = (IsAuthenticated,)
...
提供的权限
AllowAny 允许所有用户
IsAuthenticated 仅通过认证的用户
IsAdminUser 仅管理员用户
IsAuthenticatedOrReadOnly 认证的用户可以完全操作,否则只能get读取
限流 throttle_classess
可以在配置文件中,使用DEFAULT_THROTTLE_CLASSES 和 DEFAULT_THROTTLE_RATES进行全局配置,
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES': (
'rest_framework.throttling.AnonRateThrottle',
'rest_framework.throttling.UserRateThrottle'
),
'DEFAULT_THROTTLE_RATES': {
'anon': '100/day',
'user': '1000/day'
}
}
DEFAULT_THROTTLE_RATES 可以使用 second, minute, hour 或day来指明周期。
也可以在具体视图中通过throttle_classess属性来配置,如
from rest_framework.throttling import UserRateThrottle
from rest_framework.views import APIView
class ExampleView(APIView):
throttle_classes = (UserRateThrottle,)
...
可选限流类
1) AnonRateThrottle
限制所有匿名未认证用户,使用IP区分用户。
使用DEFAULT_THROTTLE_RATES[‘anon’] 来设置频次
2)UserRateThrottle
限制认证用户,使用User id 来区分。
使用DEFAULT_THROTTLE_RATES[‘user’] 来设置频次
3)ScopedRateThrottle
限制用户对于每个视图的访问频次,使用ip或user id。
例如:
class ContactListView(APIView):
throttle_scope = 'contacts'
...
class ContactDetailView(APIView):
throttle_scope = 'contacts'
...
class UploadView(APIView):
throttle_scope = 'uploads'
...
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES': (
'rest_framework.throttling.ScopedRateThrottle',
),
'DEFAULT_THROTTLE_RATES': {
'contacts': '1000/day',
'uploads': '20/day'
}
}
分页 Pagination
我们可以在配置文件中设置全局的分页方式,如:
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 100 # 每页数目
}
也可通过自定义Pagination类,来为视图添加不同分页行为。在视图中通过pagination_clas属性来指明。
class LargeResultsSetPagination(PageNumberPagination):
page_size = 1000
page_size_query_param = 'page_size'
max_page_size = 10000
class BookDetailView(RetrieveAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
pagination_class = LargeResultsSetPagination
可选分页器
1) PageNumberPagination
可以在子类中定义的属性:
page_size 每页数目
page_query_param 前端发送的页数关键字名,默认为"page"
page_size_query_param 前端发送的每页数目关键字名,默认为None
max_page_size 前端最多能设置的每页数量
2)LimitOffsetPagination
可以在子类中定义的属性:
default_limit 默认限制,默认值与PAGE_SIZE设置一直
limit_query_param limit参数名,默认'limit'
offset_query_param offset参数名,默认'offset'
max_limit 最大limit限制,默认None
过滤 filter_fields
对于列表数据可能需要根据字段进行过滤,我们可以通过添加django-fitlter扩展来增强支持。
pip install django-filter
在配置文件中增加过滤后端的设置:
INSTALLED_APPS = [
…
‘django_filters’, # 需要注册应用,
]
REST_FRAMEWORK = {
‘DEFAULT_FILTER_BACKENDS’: (‘django_filters.rest_framework.DjangoFilterBackend’,)
}
在视图中添加filter_fields属性,指定可以过滤的字段
class BookListView(ListAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
filter_fields = ('btitle', 'bread')
自动生成接口文档
- 安装依赖
REST framewrok生成接口文档需要coreapi库的支持。
pip install coreapi
- 设置接口文档访问路径
在总路由中添加接口文档路径。
文档路由对应的视图配置为rest_framework.documentation.include_docs_urls,
参数title为接口文档网站的标题。
from rest_framework.documentation import include_docs_urls
urlpatterns = [
...
url(r'^docs/', include_docs_urls(title='My API title'))
]
文档的描述说明
2)包含多个方法的视图,在类视图的文档字符串中,分开方法定义,如
class BookListCreateView(generics.ListCreateAPIView):
"""
get:
返回所有图书信息.
post:
新建图书.
"""
3)对于视图集ViewSet,仍在类视图的文档字符串中封开定义,但是应使用action名称区分,如
class BookInfoViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet):
"""
list:
返回图书列表数据
retrieve:
返回图书详情数据
latest:
返回最新的图书数据
read:
修改图书的阅读量
"""















 66
66











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









