







学习资料整理
分析糗百HTML
为了能够得到我们需要的信息,我们需要按下F12.去看看糗百的HTML的结构,从中提取我们想要的信息.
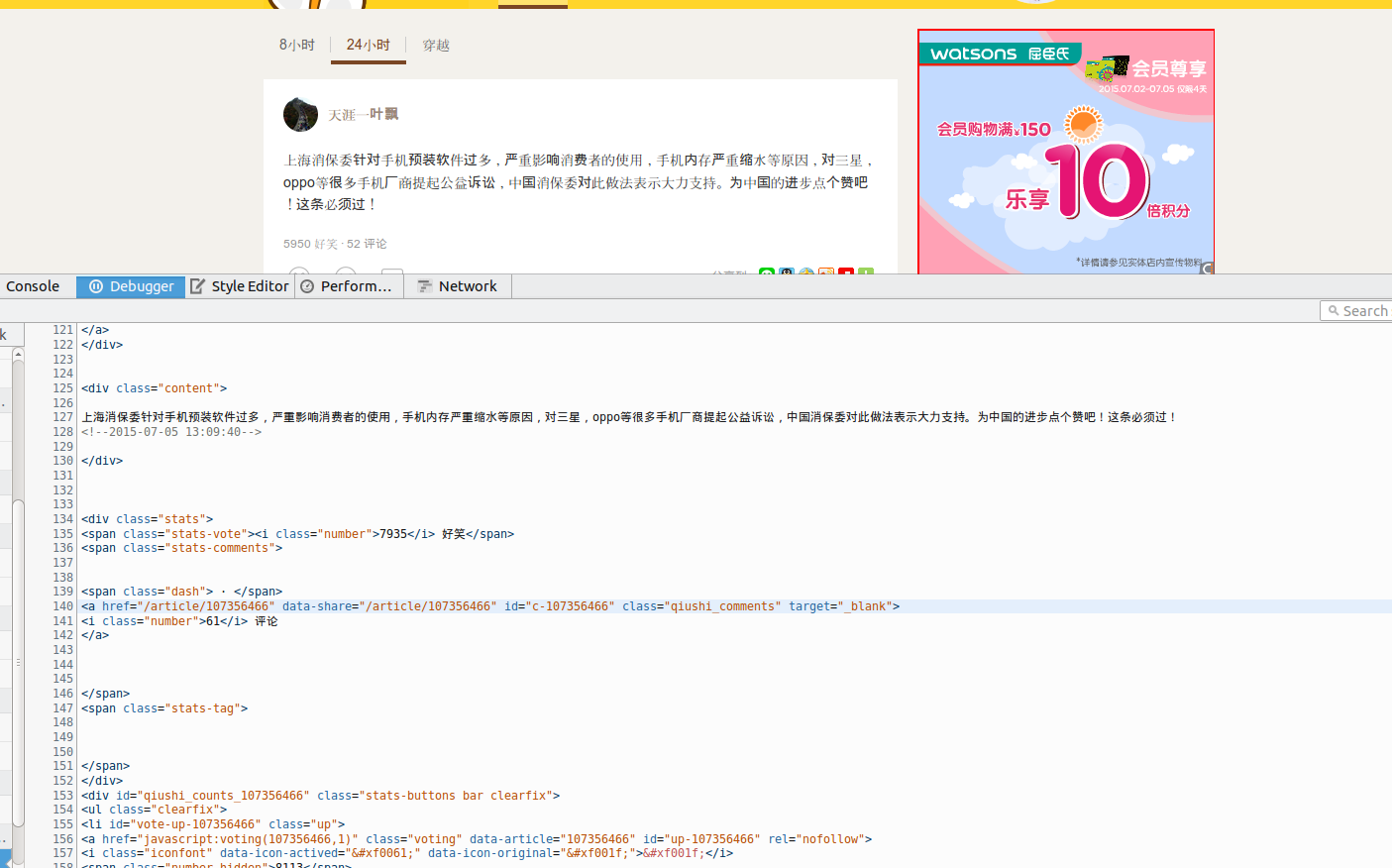
这里面我们只是把糗百文字提取出来显示,所以这里面我们就看看包裹糗百内容的HTML结构就可以了.
第一条糗百内容:
<div class="content">
上海消保委针对手机预装软件过多,严重影响消费者的使用,手机内存严重缩水等原因,对三星,oppo等很多手机厂商提起公益诉讼,中国消保委对此做法表示大力支持。为中国的进步点个赞吧!这条必须过!
<!--2015-07-05 13:09:40-->
</div>第二条糗百内容:
<div class="content">
哥哥二十九了还没结婚,回家来,爸妈看他各种不顺眼,就连他逗狗玩一下,爸爸都会说:我在你这个年纪已经在逗你玩了,而你现在只能逗狗!
<!--2015-07-05 15:10:28-->
</div>从中我们可以发现,所有糗百内容结构都是一样的.都是有一个html <div class="content">...</div> .
正则表达式
上面HTML的结构中,我们需要提取div中的内容,很容易就想到了用正则表示.
pattern = re.compile('<div class="content">(.*?)</div>', re.S)上面的正则表达式就是提取div里面的内容,(.*?)代表一个分组,re.S标志代表在匹配时为点任意匹配模式,点 . 也可以代表换行符.
Python爬虫
python爬虫一般需要用到两个模块.
import urllib
import urllib2那么怎样才能打开一个网址呢?
response = urllib2.urlopen(request)
#response = urllib2.urlopen('www.baidu.com') 返回的就是百度首页的HTML 但是有些网站(糗百)不喜欢被程序访问,或者发送不同版本的内容到不同的浏览.所有这个时候我们就要伪装成浏览器,浏览器确认自己身份是通过User-Agent头,下面为我们的请求加上一个伪装(没有异常处理,后面会给出完整的).
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
user_agent = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:38.0) Gecko/20100101 Firefox/38.0' #伪装成ubuntu下的火狐浏览器
headers = {'User-Agent': user_agent}
request = urllib2.Request(url, headers=headers) #为request添加User-Agent头
response = urllib2.urlopen(request) #打开网址下面开始读取网页里面的内容了,
content = response.read()读取的内容就是我们在糗百网页下按F12的结果一样,然后就是通过正则表达式将我需要的内容全部提取出来了.
完整Python糗百爬虫精简版代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib
import urllib2
import re
pattern = re.compile('<div class="content">(.*?)</div>', re.S) #正则表达式
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
user_agent = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:38.0) Gecko/20100101 Firefox/38.0' #伪装成ubuntu下的火狐浏览器
headers = {'User-Agent': user_agent}
try:
request = urllib2.Request(url, headers=headers) #Request
response = urllib2.urlopen(request) #打开网址
content = response.read() #读取网址内容
items = re.findall(pattern, content) #正则表达式提取内容
for item in items:
print item #打印出糗百内容
except urllib2.URLError, e: #异常处理
if hasattr(e, 'code'):
print e.code
if hasattr(e, 'reason'):
print e.reason














 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









