






 文章探讨了在深度学习模型训练中,为何使用fp16进行前向和反向计算,以及为何在梯度累加时选择fp32。重点介绍了fp16与fp32的精度差异,以及Adam算法中的momentum和variances在优化过程中的作用。实例展示了如何在PyTorch中运用自动混合精度来优化内存使用。
文章探讨了在深度学习模型训练中,为何使用fp16进行前向和反向计算,以及为何在梯度累加时选择fp32。重点介绍了fp16与fp32的精度差异,以及Adam算法中的momentum和variances在优化过程中的作用。实例展示了如何在PyTorch中运用自动混合精度来优化内存使用。
结论:
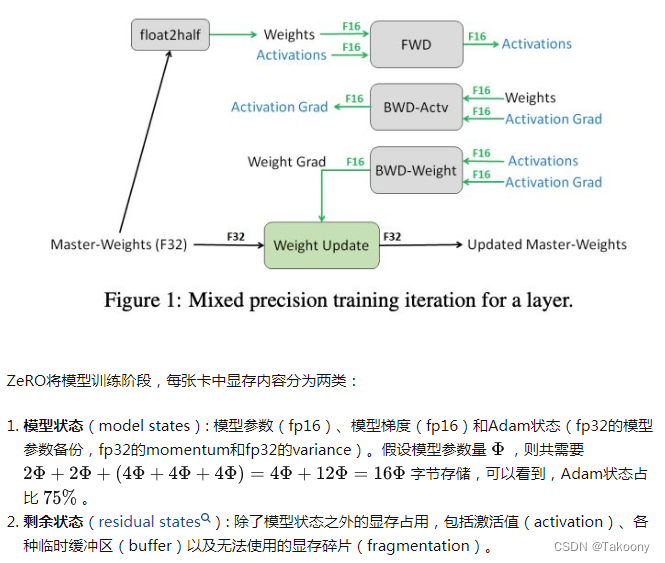
在模型训练中,fp16会比fp32快很多,因此,一般会使用fp16的参数进行模型的前向和后向计算。然而,在进行梯度累加的时候,fp16往往会精度不够,无法满足计算需求。因此,会在反向计算的时候,采用fp32。假设模型一共有 M 个参数,则fp16的参数和梯度,一共需要 4M bytes,而fp32需要存参数、adam中的momentum 和 variances,一共是 12M bytes。因此,模型参数、梯度和优化器状态,一共会需要 16M bytes的存储[3]。
来源:https://zhuanlan.zhihu.com/p/647133493
补充说明:这里用到5份参数,而且如果这里不采用混合精度而是采用双精度,那就需要20M bytes
比如说7B的模型,就会需要12 * 7G内存,即84G
问题一、为什么进行模型的前后和后向计算时要fp16,而反向计算的时候要fp32?
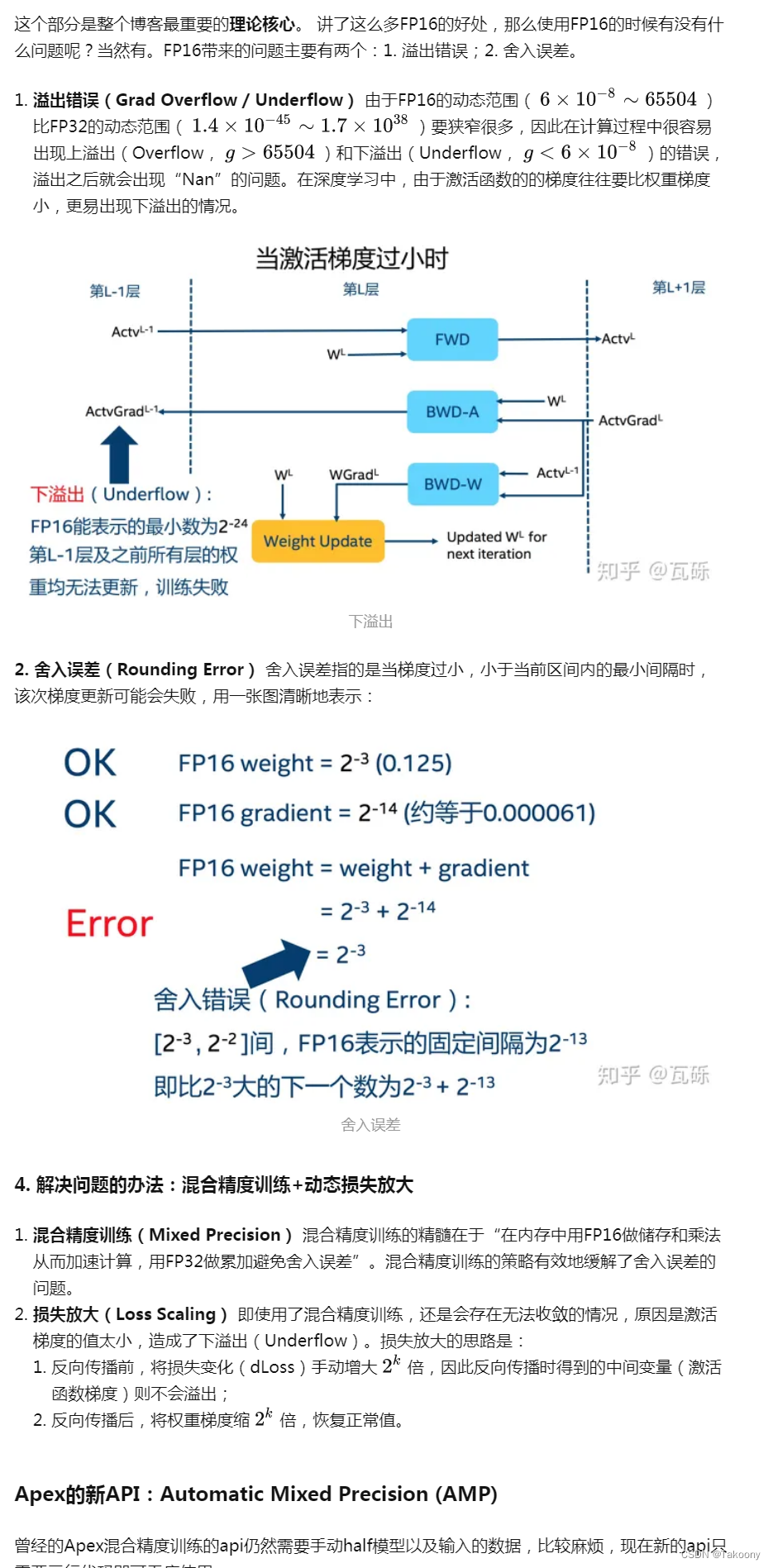
回归本质:fp16与fp32的主要区别是fp16的表示范围小很多,而且精度更低;所以一定是存在fp16无法胜任的地方,即溢出和舍入:
范围表示数的大小
精度则为浮点数的小数位所能表达的位数
范围存在溢出是否的问题
精度存在舍入与否的问题
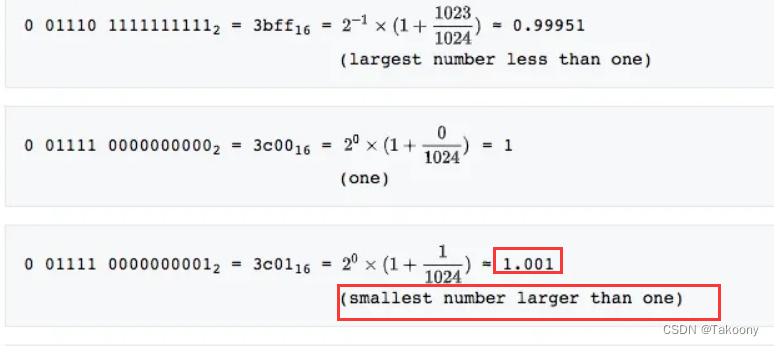
如果是1.0001就被会舍入

存在下溢现象。
图片来源:https://arxiv.org/pdf/1710.03740.pdf
梯度更新算法涉及优化算法,一般使用adam算法,就会包含momentum 和 variances;具体含义如下:
Adam是一种常用的优化算法,它结合了动量法和自适应学习率的优点。在Adam中,momentum和variances是两个重要的参数,它们分别用于计算梯度的一阶矩估计和二阶矩估计。
具体来说,momentum用于计算梯度的一阶矩估计,它类似于动量法中的动量参数,用于加速梯度下降的过程。在Adam中,momentum是一个指数加权移动平均值,它对历史梯度进行平均,从而减少梯度的方差,使得梯度下降更加平稳。
variances用于计算梯度的二阶矩估计,它类似于自适应学习率算法中的学习率参数,用于自适应地调整学习率。在Adam中,variances也是一个指数加权移动平均值,它对历史梯度的平方进行平均,从而估计梯度的方差,使得学习率可以自适应地调整。
通过使用momentum和variances,Adam算法可以自适应地调整学习率,并且可以加速梯度下降的过程,从而更快地收敛到最优解。
更详细的解释:
https://zhuanlan.zhihu.com/p/79887894
import torch
from torch import nn, optim
from torch.cuda.amp import autocast, GradScaler
# 定义模型
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.fc2 = nn.Linear(20, 1)
def forward(self, x):
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
return x
# 定义数据和优化器
data = torch.randn(32, 10).cuda()
target = torch.randn(32, 1).cuda()
model = MyModel().cuda()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 定义自动混合精度
scaler = GradScaler()
# 训练模型
for epoch in range(10):
optimizer.zero_grad()
with autocast():
output = model(data)
loss = nn.functional.mse_loss(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, 10, loss.item()))
output:
Epoch [1/10], Loss: 1.0314
Epoch [2/10], Loss: 1.0246
Epoch [3/10], Loss: 1.0180
Epoch [4/10], Loss: 1.0116
Epoch [5/10], Loss: 1.0053
Epoch [6/10], Loss: 0.9991
Epoch [7/10], Loss: 0.9932
Epoch [8/10], Loss: 0.9874
Epoch [9/10], Loss: 0.9817
Epoch [10/10], Loss: 0.9762


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









