







 博客介绍了多头注意力机制,指出V、K、Q是固定值,有3个Linear层和3个Scaled Dot - Product Attention构成多头,最后拼接转换输出。还说明其输入维度变化,由512维变为64维再拼接成512维。认为多头本质是多个独立attention计算,可防止过拟合。
博客介绍了多头注意力机制,指出V、K、Q是固定值,有3个Linear层和3个Scaled Dot - Product Attention构成多头,最后拼接转换输出。还说明其输入维度变化,由512维变为64维再拼接成512维。认为多头本质是多个独立attention计算,可防止过拟合。
先来看图:

从图片中可以看出V K Q 是固定的单个值,而Linear层有3个,Scaled Dot-Product Attention 有3个,即3个多头;最后cancat在一起,然后Linear层转换变成一个和单头一样的输出值;类似于集成;多头和单头的区别在于复制多个单头,但权重系数肯定是不一样的;类比于一个神经网络模型与多个一样的神经网络模型,但由于初始化不一样,会导致权重不一样,然后结果集成;(初步理解)
证明:attention函数来自于 attention is all you need,如下所示:

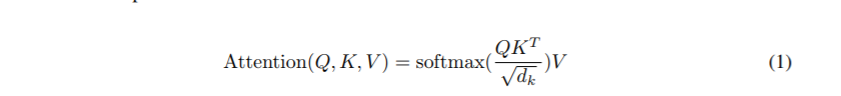
多头注意力机制函数:

从第二张图中可以多头函数看出:attention函数输入为由原来的Q,K,V变成了QW(上标为Q,下标为i),KW(上标为K,下标为i),VW(上标为V,下标为i);即3个W都不相同;将Q,K,V由原来的512维度变成了64维度(因为采取了8个多头);然后再拼接在一起变成512维,通过W(上标为O)进行线性转换;得到最终的多头注意力值;
个人最终认为:多头的本质是多个独立的attention计算,作为一个集成的作用,防止过拟合;从attention is all your need论文中输入序列是完全一样的;相同的Q,K,V,通过线性转换,每个注意力机制函数只负责最终输出序列中一个子空间,即1/8,而且互相独立;

















 7591
7591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









