






一、数据准备
1.下载数据:
- 维基百科(Wikipedia)词条数据用来做基础模型训练zhwiki dump progress on 20240401
- Belle_open_source_0.5M.json.https://huggingface.co/datasets/BelleGroup/train_0.5M_CN/tree/main
- Belle_open_source_1M.json 用来做SFT https://huggingface.co/datasets/BelleGroup/train_1M_CN
2.抽取wiki数据
运行以下命令生成wiki.txt
python WikiExtractor.py --infn /data/datasets/zhwiki/zhwiki-20240401-pages-articles-multistream.xml.bz2
3.将繁体转换为简体
由于wiki中文数据是繁体数据,需要转化为简体中文
opencc -i wiki.txt -c t2s.json> wiki-simple.txt
4.生成数据集
python dataset.py
二、训练Tokenizer
python tokenizer.py
三、训练模型
1.模型使用微软的Phimodel
- 基础模型训练
CUDA_VISIBLE_DEVICES=2,3 sh train.sh pre_train.py
- chat SFT指令微调训练
CUDA_VISIBLE_DEVICES=2,3 python sft.py
或使用accelerate加速训练
CUDA_VISIBLE_DEVICES=2,3 accelerate launch --multi_gpu --num_processes {gpu数量} sft.py
- rlhf微调
2.查看日志
cd /xxxx/日志目录
tensorboard --logdir ./runs --bind_all
浏览器访问:
http://ip:6006
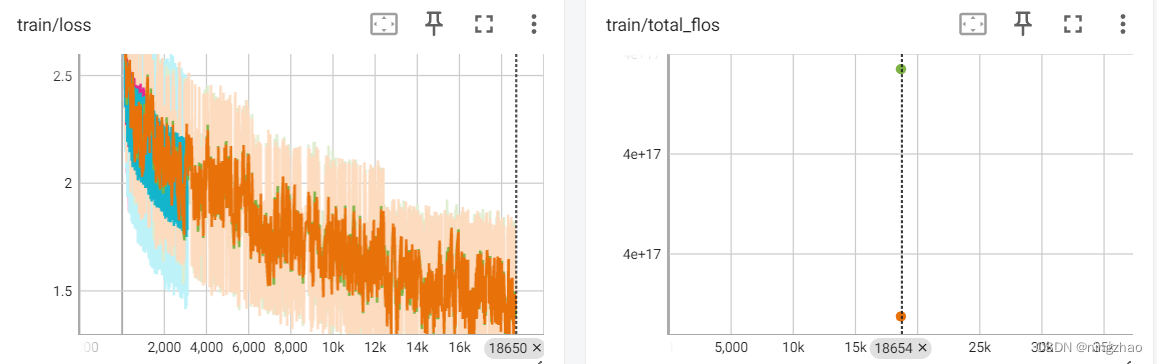
效果

注:本次测试没有使用RLHF优化训练,感兴趣的读者可以自己尝试,数据集要构造三列prompt、chosen和 rejected。
代码
测试代码使用了 项目Phi2-mini-Chinese,这里只列出作者做过修改的代码:
WikiExtractor.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#
# Incubator module added by Grzegorz Stark for Apertium, in December 2017.
#
# And changed even more by Ben Stobaugh for Apertium, in December 2013.
#
# Hacked up by Alex Rudnick for use in Guampa, October 2013.
#
# =============================================================================
# Version: 2.5 (May 9, 2013)
# Author: Giuseppe Attardi (attardi@di.unipi.it), University of Pisa
# Antonio Fuschetto (fuschett@di.unipi.it), University of Pisa
#
# Contributors:
# Leonardo Souza (lsouza@amtera.com.br)
# Juan Manuel Caicedo (juan@cavorite.com)
# Humberto Pereira (begini@gmail.com)
# Siegfried-A. Gevatter (siegfried@gevatter.com)
# Pedro Assis (pedroh2306@gmail.com)
#
# =============================================================================
# Copyright (c) 2009. Giuseppe Attardi (attardi@di.unipi.it).
# =============================================================================
# This file is part of Tanl.
#
# Tanl is free software; you can redistribute it and/or modify it
# under the terms of the GNU General Public License, version 3,
# as published by the Free Software Foundation.
#
# Tanl is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS f A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
# =============================================================================
"""Wikipedia Extractor:
Extracts and cleans text from Wikipedia database dump and stores output in a
number of files of similar size in a given directory.
Each file contains several documents in Tanl document format:
<doc id="" url="" title="">
...
</doc>
Usage:
WikiExtractor.py [options]
"""
import argparse
import gc
import sys
import urllib.request, urllib.parse, urllib.error
import re
import bz2
import os.path
from html.entities import name2codepoint
#import fnmatch
import shutil
import mimetypes
import gzip
#import nltk
## NOTE: This is customizable. Your source data may not be in English
#SEGMENTER = nltk.data.load("nltk:tokenizers/punkt/english.pickle")
### PARAMS ####################################################################
# This is obtained from the dump itself
prefix = None
##
# Whether to preseve links in output
#
keepLinks = False
##
# Whether to transform sections into HTML
#
keepSections = False
##
# Recognize only these namespaces
# w: Internal links to the Wikipedia
#
acceptedNamespaces = set(['w'])
##
# Drop these elements from article text
#
discardElements = set([
'gallery', 'timeline', 'noinclude', 'pre',
'table', 'tr', 'td', 'th', 'caption',
'form', 'input', 'select', 'option', 'textarea',
'ul', 'li', 'ol', 'dl', 'dt', 'dd', 'menu', 'dir',
'ref', 'references', 'img', 'imagemap', 'source'
])
#=========================================================================
#
# MediaWiki Markup Grammar
# Template = "{{" [ "msg:" | "msgnw:" ] PageName { "|" [ ParameterName "=" AnyText | AnyText ] } "}}" ;
# Extension = "<" ? extension ? ">" AnyText "</" ? extension ? ">" ;
# NoWiki = "<nowiki />" | "<nowiki>" ( InlineText | BlockText ) "</nowiki>" ;
# Parameter = "{{{" ParameterName { Parameter } [ "|" { AnyText | Parameter } ] "}}}" ;
# Comment = "<!--" InlineText "-->" | "<!--" BlockText "//-->" ;
#
# ParameterName = ? uppercase, lowercase, numbers, no spaces, some special chars ? ;
#
#===========================================================================
# Program version
version = '2.5'
##### Main function ###########################################################
##def WikiDocument(out, id, title, text):
## url = get_url(id, prefix)
## header = '<doc id="%s" url="%s" title="%s">\n' % (id, url, title)
## # Separate header from text with a newline.
## header += title + '\n'
## text = clean(text)
## footer = "\n</doc>"
## out.reserve(len(header) + len(text) + len(footer))
## print(header, file=out)
## for line in compact(text, structure=True):
## print(line, file=out)
## print(footer, file=out)
def WikiDocumentSentences(out, id, title, tags, text):
url = get_url(id, prefix)
header = '\n{0}:{1}'.format(title, "|||".join(tags))
# Separate header from text with a newline.
text = clean(text)
out.reserve(len(header) + len(text))
print(header, file=out)
for line in compact(text, structure=False):
print(line, file=out)
def get_url(id, prefix):
return "%s?curid=%s" % (prefix, id)
#------------------------------------------------------------------------------
selfClosingTags = [ 'br', 'hr', 'nobr', 'ref', 'references' ]
# handle 'a' separetely, depending on keepLinks
ignoredTags = [
'b', 'big', 'blockquote', 'center', 'cite', 'div', 'em',
'font', 'h1', 'h2', 'h3', 'h4', 'hiero', 'i', 'kbd', 'nowiki',
'p', 'plaintext', 's', 'small', 'span', 'strike', 'strong',
'sub', 'sup', 'tt', 'u', 'var',
]
placeholder_tags = {'math':'formula', 'code':'codice'}
### Normalize title
def normalizeTitle(title):
# remove leading whitespace and underscores
title = title.strip(' _')
# replace sequences of whitespace and underscore chars with a single space
title = re.compile(r'[\s_]+').sub(' ', title)
m = re.compile(r'([^:]*):(\s*)(\S(?:.*))').match(title)
if m:
prefix = m.group(1)
if m.group(2):
optionalWhitespace = ' '
else:
optionalWhitespace = ''
rest = m.group(3)
ns = prefix.capitalize()
if ns in acceptedNamespaces:
# If the prefix designates a known namespace, then it might be
# followed by optional whitespace that should be removed to get
# the canonical page name
# (e.g., "Category: Births" should become "Category:Births").
title = ns + ":" + rest.capitalize()
else:
# No namespace, just capitalize first letter.
# If the part before the colon is not a known namespace, then we must
# not remove the space after the colon (if any), e.g.,
# "3001: The_Final_Odyssey" != "3001:The_Final_Odyssey".
# However, to get the canonical page name we must contract multiple
# spaces into one, because
# "3001: The_Final_Odyssey" != "3001: The_Final_Odyssey".
title = prefix.capitalize() + ":" + optionalWhitespace + rest
else:
# no namespace, just capitalize first letter
title = title.capitalize();
return title
##
# Removes HTML or XML character references and entities from a text string.
#
# @param text The HTML (or XML) source text.
# @return The plain text, as a Unicode string, if necessary.
def unescape(text):
def fixup(m):
text = m.group(0)
code = m.group(1)
try:
if text[1] == "#": # character reference
if text[2] == "x":
return chr(int(code[1:], 16))
else:
return chr(int(code))
else: # named entity
return chr(name2codepoint[code])
except:
return text # leave as is
return re.sub("&#?(\w+);", fixup, text)
# Match HTML comments
comment = re.compile(r'<!--.*?-->', re.DOTALL)
# Match elements to ignore
discard_element_patterns = []
for tag in discardElements:
pattern = re.compile(r'<\s*%s\b[^>]*>.*?<\s*/\s*%s>' % (tag, tag), re.DOTALL | re.IGNORECASE)
discard_element_patterns.append(pattern)
# Match ignored tags
ignored_tag_patterns = []
def ignoreTag(tag):
left = re.compile(r'<\s*%s\b[^>]*>' % tag, re.IGNORECASE)
right = re.compile(r'<\s*/\s*%s>' % tag, re.IGNORECASE)
ignored_tag_patterns.append((left, right))
for tag in ignoredTags:
ignoreTag(tag)
# Match selfClosing HTML tags
selfClosing_tag_patterns = []
for tag in selfClosingTags:
pattern = re.compile(r'<\s*%s\b[^/]*/\s*>' % tag, re.DOTALL | re.IGNORECASE)
selfClosing_tag_patterns.append(pattern)
# Match HTML placeholder tags
placeholder_tag_patterns = []
for tag, repl in list(placeholder_tags.items()):
pattern = re.compile(r'<\s*%s(\s*| [^>]+?)>.*?<\s*/\s*%s\s*>' % (tag, tag), re.DOTALL | re.IGNORECASE)
placeholder_tag_patterns.append((pattern, repl))
# Match preformatted lines
preformatted = re.compile(r'^ .*?$', re.MULTILINE)
# Match external links (space separates second optional parameter)
externalLink = re.compile(r'\[\w+.*? (.*?)\]')
externalLinkNoAnchor = re.compile(r'\[\w+[&\]]*\]')
# Matches bold/italic
bold_italic = re.compile(r"'''''([^']*?)'''''")
bold = re.compile(r"'''(.*?)'''")
italic_quote = re.compile(r"''\"(.*?)\"''")
italic = re.compile(r"''([^']*)''")
quote_quote = re.compile(r'""(.*?)""')
# Matches space
spaces = re.compile(r' {2,}')
# Matches dots
dots = re.compile(r'\.{4,}')
# A matching function for nested expressions, e.g. namespaces and tables.
def dropNested(text, openDelim, closeDelim):
openRE = re.compile(openDelim)
closeRE = re.compile(closeDelim)
# partition text in separate blocks { } { }
matches = [] # pairs (s, e) for each partition
nest = 0 # nesting level
start = openRE.search(text, 0)
if not start:
return text
end = closeRE.search(text, start.end())
next = start
while end:
next = openRE.search(text, next.end())
if not next: # termination
while nest: # close all pending
nest -=1
end0 = closeRE.search(text, end.end())
if end0:
end = end0
else:
break
matches.append((start.start(), end.end()))
break
while end.end() < next.start():
# { } {
if nest:
nest -= 1
# try closing more
last = end.end()
end = closeRE.search(text, end.end())
if not end: # unbalanced
if matches:
span = (matches[0][0], last)
else:
span = (start.start(), last)
matches = [span]
break
else:
matches.append((start.start(), end.end()))
# advance start, find next close
start = next
end = closeRE.search(text, next.end())
break # { }
if next != start:
# { { }
nest += 1
# collect text outside partitions
res = ''
start = 0
for s, e in matches:
res += text[start:s]
start = e
res += text[start:]
return res
def dropSpans(matches, text):
"""Drop from text the blocks identified in matches"""
matches.sort()
res = ''
start = 0
for s, e in matches:
res += text[start:s]
start = e
res += text[start:]
return res
# Match interwiki links, | separates parameters.
# First parameter is displayed, also trailing concatenated text included
# in display, e.g. s for plural).
#
# Can be nested [[File:..|..[[..]]..|..]], [[Category:...]], etc.
# We first expand inner ones, than remove enclosing ones.
#
wikiLink = re.compile(r'\[\[([^[]*?)(?:\|([^[]*?))?\]\](\w*)')
parametrizedLink = re.compile(r'\[\[.*?\]\]')
# Function applied to wikiLinks
def make_anchor_tag(match):
global keepLinks
link = match.group(1)
colon = link.find(':')
if colon > 0 and link[:colon] not in acceptedNamespaces:
return ''
trail = match.group(3)
anchor = match.group(2)
if not anchor:
anchor = link
anchor += trail
if keepLinks:
return '<a href="%s">%s</a>' % (link, anchor)
else:
return anchor
def clean(text):
# FIXME: templates should be expanded
# Drop transclusions (template, parser functions)
# See: http://www.mediawiki.org/wiki/Help:Templates
text = dropNested(text, r'{{', r'}}')
# Drop tables
text = dropNested(text, r'{\|', r'\|}')
# Expand links
text = wikiLink.sub(make_anchor_tag, text)
# Drop all remaining ones
text = parametrizedLink.sub('', text)
# Handle external links
text = externalLink.sub(r'\1', text)
text = externalLinkNoAnchor.sub('', text)
# Handle bold/italic/quote
text = bold_italic.sub(r'\1', text)
text = bold.sub(r'\1', text)
text = italic_quote.sub(r'"\1"', text)
text = italic.sub(r'"\1"', text)
text = quote_quote.sub(r'\1', text)
text = text.replace("'''", '').replace("''", '"')
################ Process HTML ###############
# turn into HTML
text = unescape(text)
# do it again (&nbsp;)
text = unescape(text)
# Collect spans
matches = []
# Drop HTML comments
for m in comment.finditer(text):
matches.append((m.start(), m.end()))
# Drop self-closing tags
for pattern in selfClosing_tag_patterns:
for m in pattern.finditer(text):
matches.append((m.start(), m.end()))
# Drop ignored tags
for left, right in ignored_tag_patterns:
for m in left.finditer(text):
matches.append((m.start(), m.end()))
for m in right.finditer(text):
matches.append((m.start(), m.end()))
# Bulk remove all spans
text = dropSpans(matches, text)
# Cannot use dropSpan on these since they may be nested
# Drop discarded elements
for pattern in discard_element_patterns:
text = pattern.sub('', text)
# Expand placeholders
for pattern, placeholder in placeholder_tag_patterns:
index = 1
for match in pattern.finditer(text):
text = text.replace(match.group(), '%s_%d' % (placeholder, index))
index += 1
text = text.replace('<<', '«').replace('>>', '»')
#######################################
# Drop preformatted
# This can't be done before since it may remove tags
text = preformatted.sub('', text)
# Cleanup text
text = text.replace('\t', ' ')
text = spaces.sub(' ', text)
text = dots.sub('...', text)
text = re.sub(' (,:\.\)\]»)', r'\1', text)
text = re.sub('(\[\(«) ', r'\1', text)
text = re.sub(r'\n\W+?\n', '\n', text) # lines with only punctuations
text = text.replace(',,', ',').replace(',.', '.')
re2 = re.compile(r"__[A-Z]+__")
text = re2.sub("", text)
#Add other filters here
return text
section = re.compile(r'(==+)\s*(.*?)\s*\1')
def compact(text, structure=False):
"""Deal with headers, lists, empty sections, residuals of tables"""
page = [] # list of paragraph
headers = {} # Headers for unfilled sections
emptySection = False # empty sections are discarded
inList = False # whether opened <UL>
for line in text.split('\n'):
if not line:
continue
# Handle section titles
m = section.match(line)
if m:
title = m.group(2)
lev = len(m.group(1))
if structure:
page.append("<h%d>%s</h%d>" % (lev, title, lev))
if title and title[-1] not in '!?':
title += '.'
headers[lev] = title
# drop previous headers
for i in list(headers.keys()):
if i > lev:
del headers[i]
emptySection = True
continue
# Handle page title
if line.startswith('++'):
title = line[2:-2]
if title:
if title[-1] not in '!?':
title += '.'
page.append(title)
# handle lists
elif line[0] in '*#:;':
if structure:
page.append("<li>%s</li>" % line[1:])
else:
continue
# Drop residuals of lists
elif line[0] in '{|' or line[-1] in '}':
continue
# Drop irrelevant lines
elif (line[0] == '(' and line[-1] == ')') or line.strip('.-') == '':
continue
elif len(headers):
items = list(headers.items())
items.sort()
for (i, v) in items:
page.append(v)
headers.clear()
page.append(line) # first line
emptySection = False
elif not emptySection:
page.append(line)
return page
def handle_unicode(entity):
numeric_code = int(entity[2:-1])
if numeric_code >= 0x10000: return ''
return chr(numeric_code)
#------------------------------------------------------------------------------
class OutputSplitter:
def __init__(self, compress, max_file_size, path_name, segment=False):
self.dir_index = 0
self.file_index = 0
self.compress = compress
self.max_file_size = max_file_size
self.path_name = path_name
self.segment = segment
if sys.version_info[:2] == (3, 3):
self.isoutdated = False
else:
self.isoutdated = True
self.out_file = self.open_next_file()
def reserve(self, size):
cur_file_size = self.out_file.tell()
def write(self, text):
if self.segment:
if self.compress:
self.out_file.write(text.encode('UTF-8'))
else:
self.out_file.write(text)
else:
return
def close(self):
self.out_file.close()
def open_next_file(self):
self.file_index = self.file_index
if self.file_index == 100:
self.dir_index += 1
self.file_index = 0
file_name = 'wiki.txt'
if self.compress:
if self.isoutdated:
return bz2.BZ2File('wiki.txt.bz2', 'wb')
else:
return bz2.BZ2File('wiki.txt.bz2', 'ab')
else:
return open(file_name, 'a',encoding="utf8")
def dir_name(self):
### split into two kinds of directories:
### sentences_AA and structure_AA
prefix = "sentences_" if self.segment else "structure_"
char1 = self.dir_index % 26
char2 = self.dir_index / 26 % 26
return os.path.join(self.path_name, prefix + '%c%c' % (ord('A') + char2, ord('A') + char1))
def file_name(self):
return 'wiki_%02d' % self.file_index
### READER #############################################################
tagRE = re.compile(r'(.*?)<(/?\w+)[^>]*>(?:([^<]*)(<.*?>)?)?')
def process_data(ftype, input, output_sentences, output_structure, incubator,
vital_titles=None, vital_tags=None):
global prefix
page = []
id = None
inText = False
redirect = False
for line in input:
if ftype != 'xml':
line = str(line.decode('utf-8'))
tag = ''
if '<' in line:
m = tagRE.search(line)
if m:
tag = m.group(2)
if tag == 'page':
page = []
redirect = False
elif tag == 'id' and not id:
id = m.group(3)
elif tag == 'title':
title = m.group(3)
if(incubator != ''):
lang = title.split('/')
elif tag == 'redirect':
redirect = True
elif tag == 'text':
inText = True
line = line[m.start(3):m.end(3)] + '\n'
page.append(line)
if m.lastindex == 4: # open-close
inText = False
elif tag == '/text':
if m.group(1):
page.append(m.group(1) + '\n')
inText = False
elif inText:
page.append(line)
elif tag == '/page':
colon = title.find(':')
if (colon < 0 or title[:colon] in acceptedNamespaces) and \
not redirect:
if (not vital_titles) or (title in vital_titles):
if((incubator != '') and (lang[1] == incubator) and len(lang) > 2):
print(id, lang[2])
sys.stdout.flush()
tags = vital_tags[title] if vital_tags else []
WikiDocumentSentences(output_sentences, id, lang[2], tags,
''.join(page))
#WikiDocument(output_structure, id, title, ''.join(page))
elif(incubator == ''):
print(id, title)
sys.stdout.flush()
tags = vital_tags[title] if vital_tags else []
WikiDocumentSentences(output_sentences, id, title, tags,
''.join(page))
#WikiDocument(output_structure, id, title, ''.join(page))
id = None
page = []
elif tag == 'base':
# discover prefix from the xml dump file
# /mediawiki/siteinfo/base
base = m.group(3)
prefix = base[:base.rfind("/")]
##def load_vital_titles(vitalfn):
## """Given the filename for the vital titles list (one title per line, with
## tags), return a set of Wikipedia titles and a map from those titles to lists
## of tags."""
## with open(vitalfn) as infile:
## titles = set()
## titles_to_tags = {}
## for line in infile:
## line = line.strip()
## splitted = line.split("|||")
## title = splitted[0]
## tags = splitted[1:]
## titles.add(title)
## titles_to_tags[title] = tags
## return titles, titles_to_tags
### CL INTERFACE #########################################################
def show_help():
print(__doc__, end=' ', file=sys.stdout)
def show_usage(script_name):
print('Usage: %s [options]' % script_name, file=sys.stderr)
##
# Minimum size of output files
minFileSize = 200 * 1024
def get_argparser():
"""Build the argument parser for main."""
parser = argparse.ArgumentParser(description='WikiExtractor')
parser.add_argument('--infn', type=str, required=False, help="The location/file of the Wiki Dump. Supports uncompressed, bz2, and gzip.")
parser.add_argument('--incubator', type=str, required=False, help="If this is included, WikiExtractor will scramble in Incubator Mode. You should specify language here (e.g enm - Middle English)")
#parser.add_argument('--vitalfn', type=str, required=False)
#parser.add_argument('--all-articles',dest='allArticles',action='store_true')
#parser.add_argument('--structure',dest='keepSections',action='store_true')
#parser.add_argument('--no-structure',dest='keepSections',action='store_false')
parser.add_argument('--compress',dest='compress',action='store_true', help="If this is included the output file will be compressed (bz2)")
#parser.set_defaults(keepSections=True)
#parser.set_defaults(allArticles=True)
parser.set_defaults(compress=False)
parser.set_defaults(incubator='')
parser.set_defaults(infn='')
return parser
def main():
global keepLinks, keepSections, prefix, acceptedNamespaces
script_name = os.path.basename(sys.argv[0])
parser = get_argparser()
args = parser.parse_args()
keepSections = True
compress = args.compress
file_size = 500 * 1024
output_dir = '.'
if not keepLinks:
ignoreTag('a')
vital_titles = None
vital_tags = None
## if args.vitalfn:
## vital_titles, vital_tags = load_vital_titles(args.vitalfn)
## print("Extracting {0} articles...".format(len(vital_titles)))
## elif args.allArticles:
## print("Extracting every article...")
## else:
## print("Need either --all-articles or --vitalfn")
## sys.exit(1)
output_sentences = OutputSplitter(compress, file_size, output_dir,
segment=True)
#output_structure = OutputSplitter(compress, file_size, output_dir)
incubator = args.incubator
fname = args.infn
if fname == "":
parser.print_help()
print('')
print("Please include --infn FIlENAME in your command.")
sys.exit()
ftypes = mimetypes.guess_type(fname)
if 'bzip2' in ftypes:
print('File detected as being bzip2.')
f = bz2.BZ2File(fname, mode='r')
process_data('bzip2',f, output_sentences, vital_titles, incubator, vital_tags)
output_sentences.close()
elif 'gzip' in ftypes:
print('File detected as being a gzip.')
f = gzip.GzipFile(fname, mode='r')
process_data('gzip',f, output_sentences, vital_titles, incubator, vital_tags)
output_sentences.close()
else:
with open(args.infn,encoding="utf8") as infile:
process_data('xml',infile, output_sentences, vital_titles, incubator, vital_tags)
output_sentences.close()
#output_structure.close()
if __name__ == '__main__':
main()
dataset.py
import pyarrow.parquet as pq
import pyarrow as pa
import ujson
import numpy as np
from tqdm import tqdm
from transformers import AutoTokenizer
from datasets import Dataset
from utils import DropDatasetDuplicate
origin_wiki_file = '/data/datasets/zhwiki/wiki-simple.txt'
tokenizer_dir = './model_save/fast_tokenizer/'
liness = []
with open(origin_wiki_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
tokenizer = AutoTokenizer.from_pretrained(tokenizer_dir)
# 如果词表大小小于 65535 用uint16存储,节省磁盘空间,否则用uint32存储
ids_dtype = np.uint16 if (len(tokenizer) // 64 + 1) * 64 < 65535 else np.uint32
print(lines[0:5])
items, content = [], []
key_word, kw_line_idx = '', 0
content_start = False # 词条内容开始标记
for i, line in enumerate(lines):
line_strip = line.strip()
# 词条以冒号`:`结尾
if len(line_strip) > 0 and line_strip[-1] in (':', ':'):
key_word = ''.join(line_strip[: -1])
kw_line_idx = i
continue
# 词条key_word在下一行,则合并上个词条并保存
if i == kw_line_idx + 1 and key_word in line_strip or i == len(lines) - 1:
txt = ''.join(content)
if len(txt) > 0:
items.append(txt)
content = []
content.append(f"{key_word}:")
content.append(line)
print(len(items))
print(items[0:5])
def gen():
for txt in items:
yield {'text': txt}
dataset = Dataset.from_generator(gen, cache_dir='.cache', keep_in_memory=True)
eos_token_id = tokenizer.eos_token_id
def txt_to_id_map(samples: dict, max_len: int, stride: int, tokenizer: int, ids_dtype: np.dtype, np) -> dict:
batch_txt = samples['text']
eos_token_id = tokenizer.eos_token_id
encoded = tokenizer(
batch_txt,
max_length=max_len,
truncation=True,
stride=stride, # 相邻两行保持stride个重复的token
return_overflowing_tokens=True, #返回被截断的数据
return_token_type_ids=False,
return_offsets_mapping=False,
return_attention_mask=False,
)
input_ids = encoded['input_ids']
overflow_map = encoded['overflow_to_sample_mapping']
# 获取每个doc的最后一行
last_line_indexs = []
for idx in range(len(overflow_map) - 1):
# 在分割处的id不一样
if overflow_map[idx] != overflow_map[idx + 1]:
last_line_indexs.append(idx)
# 添加最后一个doc的最后一行
last_line_indexs.append(len(overflow_map) - 1)
# 仅在doc的最后添加eos id,如果最后一行长度为max_length,eos id直接覆盖最后一个token id
for last_idx in last_line_indexs:
if len(input_ids[last_idx]) == max_len:
input_ids[last_idx][-1] = eos_token_id
else:
input_ids[last_idx] += [eos_token_id]
outputs = [np.array(item, dtype=ids_dtype) for item in input_ids]
return {
"input_ids": outputs
}
max_len, stride = 320, 0
ds = dataset.map(txt_to_id_map, fn_kwargs={'max_len': max_len, 'stride': stride, 'tokenizer': tokenizer, 'ids_dtype': ids_dtype, 'np': np}, batched=True, batch_size=1024, remove_columns=dataset.column_names, num_proc=6)
ds.save_to_disk('./data/wiki')
def cut_with_end_pun(txt: str, max_len: int) -> str:
'''
截断文本,超过最大长度的,从最后一个结束标点符号截断
'''
if len(txt) <= max_len:
return txt
# 从 max_len 开始找最后一个句号,叹号
i = max_len
while i >= 0 and txt[i] not in ('。', '!'):
i -= 1
end = max_len if i <= 0 else i + 1
txt = ''.join(txt[0: end])
return txt
def split_txt_cropus_to_chunk_data(texts: list[str], batch_size: int=512 ** 2, max_len: int=320, window_size: int = 2) -> list[str]:
buffer, buffer_len = [], 0
chunk_data = []
for i, line in enumerate(texts):
buffer_len += len(line)
buffer.append(line)
if buffer_len >= batch_size or i == len(texts) - 1:
buffer_txt = ''.join(buffer)
# - window_size为滑动窗口,这样每个窗口都包含有window_size个上文
for i in range(0, len(buffer_txt), max_len - window_size):
chunk_data.append(''.join(buffer_txt[i: i + max_len]))
buffer, buffer_len = [], 0
return chunk_data
chunk_data = split_txt_cropus_to_chunk_data(items)
print(len(chunk_data))
tb = pa.Table.from_arrays([chunk_data], names=['text'])
# compression='GZIP'
pq.write_table(table=tb, where='./data/wiki_chunk_320_2.2M.parquet', row_group_size=50000, data_page_size=50000, )
#bell
train_data = []
eval_data = []
eval_size = 1_0000
max_len = 400
root = '/data/datasets/'
for file in [root + '/Belle_open_source_0.5M.json']:
with open(file, 'r', encoding='utf-8') as f:
for line in f:
item = ujson.loads(line)
if item['input'].strip() != '':
txt = f"{item['instruction']}\n{item['input']}\n{item['output']}"
else:
txt = f"{item['instruction']}\n{item['output']}"
# 收集测试数据
if len(txt) >= max_len and len(txt) < max_len + 8 and len(eval_data) < eval_size and np.random.rand() > 0.75:
eval_data.append(txt)
continue
if len(txt) == 0 or len(txt) >= max_len: continue
train_data.append(
txt
)
tb = pa.Table.from_arrays([train_data], names=['text'])
# compression='GZIP'
pq.write_table(table=tb, where=f'./data/bell_pretrain_{max_len}_0.5M.parquet', row_group_size=20480, data_page_size=20480, )
tb = pa.Table.from_arrays([eval_data], names=['text'])
# compression='GZIP'
pq.write_table(table=tb, where=f'./data/pretrain_eval_{max_len}_0.5w.parquet', row_group_size=20480, data_page_size=20480, )
#处理sft data
lines = []
with open('/data/datasets/Belle_open_source_1M.json', 'r', encoding='utf-8') as f:
for line in f:
item = ujson.loads(line)
txt = f"{item['instruction']}{item['output']}"
if len(txt) == 0 or len(txt) >= 320: continue
lines.append(item)
print(len(lines))
tb = pa.Table.from_pylist(lines)
# compression='GZIP'
pq.write_table(table=tb, where='./data/sft_train_data.parquet', row_group_size=20480, data_page_size=20480, )tokenizer.py
from transformers import PreTrainedTokenizerFast
import tokenizers
from tokenizers import Tokenizer, decoders
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
from tokenizers.pre_tokenizers import Punctuation, Digits, Metaspace, ByteLevel
from tokenizers.normalizers import NFKC
from rich import progress
cropus_file = '/data/datasets/zhwiki/wiki-simple.txt'
tokenizer_save_path = './hf_bpe_tokenizer.josn'
def train_my_huggingface_wiki_tokenizer(max_train_line: int=None, token_type: str='char') -> None:
'''
训练tokenizer with huggingface,至少需要32G内存,运行大概需要半个小时。
'''
# if not exists(tokenizer_save_path): mkdir(tokenizer_save_path)
def get_training_corpus(buffer_size: int=1000, chunk_len: int=2048) -> list:
'''
一个文本块大小2048
'''
line_cnt = 0
buffer = []
with open(cropus_file, 'r', encoding='utf-8') as f_read:
cur_chunk_txt, txt_len = [], 0
for line in f_read:
cur_chunk_txt.append(line)
txt_len += len(line)
line_cnt += 1
if txt_len >= chunk_len:
buffer.append(
''.join(cur_chunk_txt)
)
cur_chunk_txt, txt_len = [], 0
if len(buffer) >= buffer_size:
yield buffer
buffer = []
if isinstance(max_train_line, int) and line_cnt > max_train_line: break
# yield last
if len(buffer) > 0: yield buffer
special_tokens = ["[PAD]","[EOS]","[SEP]","[BOS]", "[CLS]", "[MASK]", "[UNK]"]
if token_type =='char':
model = BPE(unk_token="[UNK]")
tokenizer = Tokenizer(model)
# 用兼容等价分解合并对utf编码进行等价组合,比如全角A转换为半角A
tokenizer.normalizer = tokenizers.normalizers.Sequence([NFKC()])
# 标点符号,数字,及Metaspace预分割(否则decode出来没有空格)
tokenizer.pre_tokenizer = tokenizers.pre_tokenizers.Sequence(
[Punctuation(), Digits(individual_digits=True), Metaspace()]
)
tokenizer.add_special_tokens(special_tokens)
tokenizer.decoder = decoders.Metaspace()
elif token_type =='byte':
# byte BPE n不需要unk_token
model = BPE()
tokenizer = Tokenizer(model)
tokenizer.pre_tokenizer = tokenizers.pre_tokenizers.ByteLevel(add_prefix_space=False, use_regex=True)
tokenizer.add_special_tokens(special_tokens)
tokenizer.decoder = decoders.ByteLevel(add_prefix_space=False, use_regex=True)
tokenizer.post_processor = tokenizers.processors.ByteLevel(trim_offsets=False)
else:
raise Exception('token type must be `char` or `byte`')
trainer = BpeTrainer(vocab_size=40960, min_frequency=100, show_progress=True, special_tokens=special_tokens)
tokenizer.train_from_iterator(get_training_corpus(), trainer=trainer)
# add \t \n
if '\t' not in tokenizer.get_vocab():
tokenizer.add_tokens(['\t'])
if '\n' not in tokenizer.get_vocab():
tokenizer.add_tokens(['\n'])
tokenizer.save(tokenizer_save_path)
train_my_huggingface_wiki_tokenizer(token_type='byte')
slow_tokenizer = Tokenizer.from_file(tokenizer_save_path)
tokenizer = PreTrainedTokenizerFast(
tokenizer_object=slow_tokenizer,
unk_token="[UNK]",
pad_token="[PAD]",
cls_token="[CLS]",
sep_token="[SEP]",
mask_token="[MASK]",
bos_token='[BOS]',
eos_token='[EOS]',
)
tokenizer.save_pretrained('./model_save/fast_tokenizer/')
pre_train.py
# %%
import os, platform, time
from typing import Optional
from transformers import PreTrainedTokenizerFast, DataCollatorForLanguageModeling, PhiConfig, PhiForCausalLM, Trainer, TrainingArguments, TrainerCallback
from datasets import load_dataset, Dataset
import pandas as pd
from transformers.trainer_callback import TrainerControl, TrainerState
import numpy as np
from dataclasses import dataclass,field
import torch
# %%
os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'
attn_implementation = 'flash_attention_2'
try:
from flash_attn import flash_attn_func
except Exception as e:
attn_implementation = 'eager'
# %% [markdown]
# # 1. 训练数据来源
TRAIN_FILES = [
'./data/wiki_chunk_320_2.2M.parquet',
'./data/bell_pretrain_400_0.5M.parquet',
]
EVAL_FILE = './data/pretrain_eval_400_0.5w.parquet'
# %%
@dataclass
class PretrainArguments:
tokenizer_dir: str = './model_save/fast_tokenizer/'
model_save_dir: str = './model_save/pre/'
logs_dir: str = './logs/'
train_files: list[str] = field(default_factory=lambda: TRAIN_FILES)
eval_file: str = EVAL_FILE
max_seq_len: int = 512
# Windows 使用默认的attention实现,
attn_implementation: str = 'eager' if platform.system() == 'Windows' else attn_implementation
pretrain_args = PretrainArguments()
# %% [markdown]
# # 2. 加载训练好的tokenizer
# 如果你使用的`add_tokens`方法添加了自己的token,必须要用`len(tokenizer)`获取长度,`tokenizer.vocab_size`统计不包含你添加的字符。
# %%
tokenizer = PreTrainedTokenizerFast.from_pretrained(pretrain_args.tokenizer_dir)
# %% [markdown]
# # 5. 定义模型
# 从`config`定义,不是`from_pretrained`。
# 为了方便cuda计算,词表的大小注意一下,如果不是64的整数倍,可以手动向上取整为64的整数倍,也可以是其他 $2^x$ 数值的整数倍,如32、128、256都行。
# %%
vocab_size = len(tokenizer)
if vocab_size % 64 != 0:
vocab_size = (vocab_size // 64 + 1) * 64
print(f"source vocab size: {len(tokenizer)}, final vocab sieze: {vocab_size}")
# %% [markdown]
# ## token to id缓存到文件,使用的时候不用再次tokenize
# 如果词表大小小于 65535 用uint16存储,节省磁盘空间,否则用uint32存储
# %%
map_dtype = np.uint16 if vocab_size < 65535 else np.uint32
def token_to_id(samples: dict[str, list]) -> dict:
batch_txt = samples['text']
outputs = tokenizer(
batch_txt,
truncation=False,
padding=False,
return_attention_mask=False,
)
input_ids = [np.array(item, dtype=map_dtype) for item in outputs["input_ids"]]
return {
"input_ids": input_ids
}
# step 3 加载数据集
# %%
def get_maped_dataset(files: str|list[str]) -> Dataset:
dataset = load_dataset(path='parquet', data_files=files, split='train', cache_dir='.cache')
maped_dataset = dataset.map(token_to_id, batched=True, batch_size=1_0000, remove_columns=dataset.column_names)
return maped_dataset
train_dataset = get_maped_dataset(pretrain_args.train_files)
eval_dataset = get_maped_dataset(pretrain_args.eval_file)
print(train_dataset, eval_dataset)
# %% [markdown]
# # 4. 定义data_collator
# `mlm=False`表示要训练CLM模型,`mlm=True`表示要训练MLM模型
# %%
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)
# %%
# 如果配置了flash_attention_2,请手动设置set_default_dtype为float16
# Flash Attention 2.0 only supports torch.float16 and torch.bfloat16 dtypes.
if pretrain_args.attn_implementation == 'flash_attention_2':
torch.set_default_dtype(torch.bfloat16)
# %%
phi_config = PhiConfig(
vocab_size=vocab_size,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
hidden_size=960,
num_attention_heads=16,
num_hidden_layers=24,
max_position_embeddings=512,
intermediate_size=4096,
attn_implementation=pretrain_args.attn_implementation,
)
model = PhiForCausalLM(phi_config)
# model = model.to_bettertransformer()
# 另外一个使用flash_attention_2的方法
# model = PhiForCausalLM.from_pretrained('./model_save/300m', torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2")
# model = model.to('cuda')
model_size = sum(t.numel() for t in model.parameters())
print(f"Phi-2 size: {model_size / 1000**2:.1f}M parameters")
# %% [markdown]
# # 6. cuda cache回调函数
# %%
class MyTrainerCallback(TrainerCallback):
log_cnt = 0
def on_log(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):
'''
在打印 n 次日志后清除cuda缓存,适合低显存设备,能防止OOM
'''
self.log_cnt += 1
if self.log_cnt % 2 == 0:
torch.cuda.empty_cache()
def on_epoch_end(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):
'''
在on_epoch_end时保存一次模型。
TrainingArguments的 save_strategy 中 epoch 和 steps 不兼容。要实现每隔 save_steps 步保存一次检查点,考虑到磁盘空间大小,最多只保存最近3个检查点。
'''
# 设置should_save=True并返回即可
control.should_save = True
return control
my_trainer_callback = MyTrainerCallback()
# %% [markdown]
# # 6. 定义训练参数
# %%
args = TrainingArguments(
output_dir=pretrain_args.model_save_dir,
per_device_train_batch_size=4,
gradient_accumulation_steps=32,
num_train_epochs=1,
weight_decay=0.1,
warmup_steps=1000,
learning_rate=5e-4,
evaluation_strategy='steps',
eval_steps=2000,
save_steps=100,
save_strategy='steps',
save_total_limit=2,
report_to='tensorboard',
optim="adafactor",
bf16=True,
logging_steps=5,
log_level='info',
logging_first_step=True,
# group_by_length=True,
# deepspeed='./ds_config_one_gpu.json',
)
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
callbacks=[my_trainer_callback],
)
# %% [markdown]
# # 7. 开始训练
# `resume_from_checkpoint=True`参数可以从上次保存的检查点继续训练
# %%
trainer.train(
# resume_from_checkpoint=True
)
# %% [markdown]
# 计算困惑度Perplexity
# %%
eval_results = trainer.evaluate()
print(f"Perplexity: {np.exp(eval_results['eval_loss']):.2f}")
# %% [markdown]
# # 8. 最后保存训练的loss日志和模型
# %%
loss_log = pd.DataFrame(trainer.state.log_history)
loss_log.to_csv(f"./logs/pre_train_log_{time.strftime('%Y%m%d-%H%M')}.csv")
trainer.save_model(pretrain_args.model_save_dir)
sft.py
# %%
from datasets import load_dataset
from transformers import PreTrainedTokenizerFast, PhiForCausalLM, TrainingArguments, Trainer, TrainerCallback
from datasets import load_dataset
import pandas as pd
import numpy as np
import time
import torch
from trl import DataCollatorForCompletionOnlyLM
# %% [markdown]
# # 1. 定义训练数据,tokenizer,预训练模型的路径及最大长度
# %%
sft_file = './data/sft_train_data.parquet'
tokenizer_dir = './model_save/fast_tokenizer/'
sft_from_checkpoint_file = './model_save/pre/checkpoint-2806' #这里指定基础模型训练最后的checkpoint
model_save_dir = './model_save/sft/'
max_seq_len = 320
# %% [markdown]
# # 2. 加载训练数据集
# %%
dataset = load_dataset(path='parquet', data_files=sft_file, split='train', cache_dir='.cache')
# %%
dataset
# %%
# samples = dataset[0:2]
# print(samples)
# %%
tokenizer = PreTrainedTokenizerFast.from_pretrained(tokenizer_dir)
print(f"vicab size: {len(tokenizer)}")
# %% [markdown]
# ## 2.1 定义sft data_collator的指令字符
# 也可以手动将`instruction_template_ids`和`response_template_ids`添加到input_ids中的,因为如果是byte level tokenizer可能将`:`和后面的字符合并,导致找不到`instruction_template_ids`和`response_template_ids`。
# 也可以像下文一样通过在`'#'`和`':'`前后手动加`'\n'`解决
# %%
instruction_template = "##提问:"
response_template = "##回答:"
# %%
map_dtype = np.uint16 if len(tokenizer) < 65535 else np.uint32
def batched_formatting_prompts_func(example: list[dict]) -> list[str]:
batch_txt = []
for i in range(len(example['instruction'])):
text = f"{instruction_template}\n{example['instruction'][i]}\n{response_template}\n{example['output'][i]}[EOS]"
batch_txt.append(text)
# token to id
outputs = tokenizer(batch_txt, return_attention_mask=False)
input_ids = [np.array(item, dtype=map_dtype) for item in outputs["input_ids"]]
return {
"input_ids": input_ids
}
# print(batched_formatting_prompts_func(samples))
# %%
dataset = dataset.map(batched_formatting_prompts_func, batched=True, remove_columns=dataset.column_names).shuffle(23333)
# %% [markdown]
# ## 2.2 定义data_collator
# %%
# mlm=False表示训练的是CLM模型
data_collator = DataCollatorForCompletionOnlyLM(instruction_template=instruction_template, response_template=response_template, tokenizer=tokenizer, mlm=False)
# %% [markdown]
# # 4. 加载预训练模型
# %%
model = PhiForCausalLM.from_pretrained(sft_from_checkpoint_file)
model_size = sum(t.numel() for t in model.parameters())
print(f"Phi2 size: {model_size / 1000**2:.2f}M parameters")
# %% [markdown]
# ## 定义训练过程中的回调函数
# N次log之后情况cuda缓存,能有效缓解低显存机器显存缓慢增长的问题
# %%
class EmptyCudaCacheCallback(TrainerCallback):
log_cnt = 0
def on_log(self, args, state, control, logs=None, **kwargs):
self.log_cnt += 1
if self.log_cnt % 5 == 0:
torch.cuda.empty_cache()
empty_cuda_cahce = EmptyCudaCacheCallback()
# %%
my_datasets = dataset.train_test_split(test_size=4096)
# %% [markdown]
# # 5. 定义训练参数
# %%
args = TrainingArguments(
output_dir=model_save_dir,
per_device_train_batch_size=32,
gradient_accumulation_steps=2,
num_train_epochs=3,
weight_decay=0.1,
warmup_steps=1000,#预热1000 step,在这个阶段学习率由warmup_ratio值(缺省是0)上升到learning_rate,然后再逐渐变小,在训练完成时变为0
learning_rate=5e-5,
evaluation_strategy='steps',
eval_steps=500,
save_steps=500,
save_total_limit=2,
report_to='tensorboard',
optim="adafactor",
bf16=True,
logging_steps=10,
log_level='info',
logging_first_step=True,
group_by_length=True,
load_best_model_at_end = True # this will let the model save the best checkpoint
#use_multiprocessing=True, # 是否使用多处理
#fp16=True, # 使用半精度浮点数
#gpus=2 # 使用2个GPU
)
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=args,
data_collator=data_collator,
train_dataset=my_datasets['train'],
eval_dataset=my_datasets['test'],
callbacks=[empty_cuda_cahce],
)
# %% [markdown]
# # 6. 开始训练
# %%
trainer.train(
# resume_from_checkpoint=True
)
# %% [markdown]
# 计算困惑度Perplexity
# %%
eval_results = trainer.evaluate()
print(f"Perplexity: {np.exp(eval_results['eval_loss']):.2f}")
# %% [markdown]
# # 7. 保存日志和模型
# %%
loss_log = pd.DataFrame(trainer.state.log_history)
loss_log.to_csv(f"./logs/sft_train_log_{time.strftime('%Y%m%d-%H%M')}.csv")
trainer.save_model(model_save_dir)
# %%
test_chat.py
from transformers import PreTrainedTokenizerFast
from tokenizers import Tokenizer
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
import torch
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
tokenizer = PreTrainedTokenizerFast.from_pretrained("Phi2-mini-Chinese-main/model_save/sft/checkpoint-18000")
model = AutoModelForCausalLM.from_pretrained('Phi2-mini-Chinese-main/model_save/sft/checkpoint-18000').to(device)
txt = '请介绍下上海?'
prompt = f"##提问:\n{txt}\n##回答:\n"
# greedy search
gen_conf = GenerationConfig(
num_beams=3,
do_sample=True,
max_length=320,
temperature=0.3,
repetition_penalty=1,
max_new_tokens=256,
no_repeat_ngram_size=4,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
)
tokend = tokenizer.encode_plus(text=prompt)
input_ids, attention_mask = torch.LongTensor([tokend.input_ids]).to(device), \
torch.LongTensor([tokend.attention_mask]).to(device)
outputs = model.generate(
inputs=input_ids,
attention_mask=attention_mask,
generation_config=gen_conf,
)
outs = tokenizer.decode(outputs[0].cpu().numpy(), clean_up_tokenization_spaces=True, skip_special_tokens=True,)
print(outs)















 69
69











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









