






一、神经网络的前向与反向传播过程详解
我们这里以最简单的神经网络为例说明。有三层网络,一个输入层,一个隐藏层,一个输出层,每层有2个神经元。
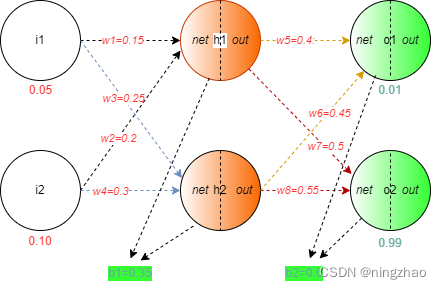
如图中所示:i1,i2为两个输入神经元,h1,h2为隐藏层两个神经元,o1,o2为两个输出神经元。
其中i1,i2两个输入值分别为0.05,0.10,真实输出值为0.01与0.99,w1-w8为权重值,是网络要学习的参数。b1,b2是偏置值。
1.前向传播(从输入层--->隐藏层-->输出层)
-
从输入层到隐藏层
在这里激活函数使用逻辑函数
同理,计算隐藏层的第二个神经元:
-
从隐藏层到输出层
2.计算损失(损失函数使用MSE)
这里的targt是真实值,output为计算值.这里的1/2是为了简化计算。
3.反向传播(从输出层-->隐藏层-->输入层)
反向传播的目的是更新所有权重值,使得每个输出神经元与整个网络的损失最小(即真实值与预测值最接近)
输出层
-
计算梯度
首先让我们来看w5的改变对网络损失的影响,即求偏导:
, 也可以叫做求关于
的梯度。
使用链式法则可得:
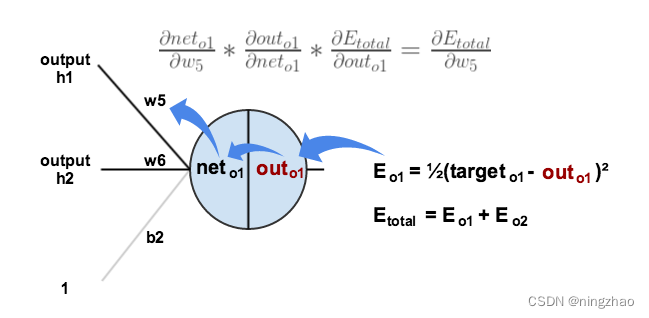
我们需要计算出这个方程中每一部分。
逻辑函数的导数是
汇总
至此我们求得了关于的梯度。
-
更新权重
使用梯度下降法更新权重值
同理我们可以计算出的值,这里不再一一列举。
表示学习率是超参数,这里设置为0.5。
隐藏层
在这里我们继续计算该层的权重参数的新值。
计算梯度
首先我们看W1的改变对整个损失的影响。
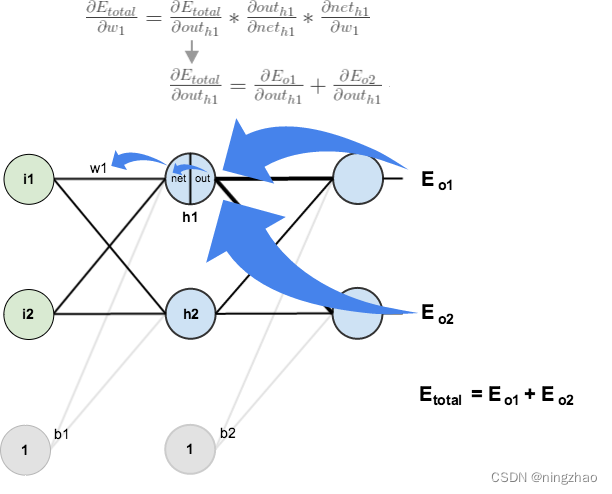
我们先求等式右边的第一项,依据链式法则:
接下来求:
更新权重
使用梯度下降法更新权重值
同理我们可以计算出的值,这里不再一一列举。
表示学习率是超参数,这里设置为0.5。
最终我们使用同样的方法更新所有权重参数值。
参考:















 1377
1377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









