






概念
量化:将FLOAT32(32位浮点数)的参数量化到更低精度,精度的变化并不是简单的强制类型转换,而是为不同精度数据之间建立一种数据映射关系,最常见的就是定点与浮点之间的映射关系,使得以较小的精度损失代价得到较好的收益。

效果:当从32-bit降低到8-bit,存储张量的内存开销减少了4倍,矩阵乘法的计算成本则减少了16倍。
线性量化(线性映射)
- 非对称量化数据的映射范围是:0 ~ 2^b -1

- 对称量化数据的映射范围是:-2^(b-1) ~ 2^(b-1) -1
对称量化公式:
![]()
s:放缩因子(scale factor)/量化步长(step size),是浮点数
z:零点(zero-point),是整数,保证真实的0不会有量化误差,对ReLU和zero-padding很重要
b:位宽(bit-width),是整数,比如2, 4, 6, 8
d:[]![]() 表示的是近似取整的数学函数,可以是四舍五入、向上取整、向下取整等;
表示的是近似取整的数学函数,可以是四舍五入、向上取整、向下取整等;

根据量化的公式不难推导出,反量化公式如下:
![]()
当Z=0时,
![]()
,、
![]()
。 量化区域[Xmin, Xmax]
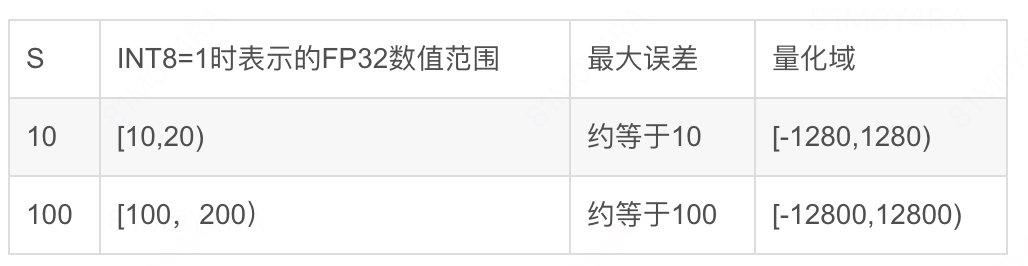
- 当S取大时,可以扩大量化域,但同时,单个INT8数值可表示的FP32范围也变广了,因此INT8数值与FP32数值的误差(量化误差)会增大;而当S取小时,量化误差虽然减小了,但是量化域也缩小了,被舍弃的参数会增多。
PTQ 和 QAT 简介
模型量化中,依据是否要对量化后的参数进行调整,我们可以将量化方法分为量化感知训练(QAT)和训练后量化(PTQ)。 这两种方法的操作区别如下图所示(图左为QAT,图右为PTQ):
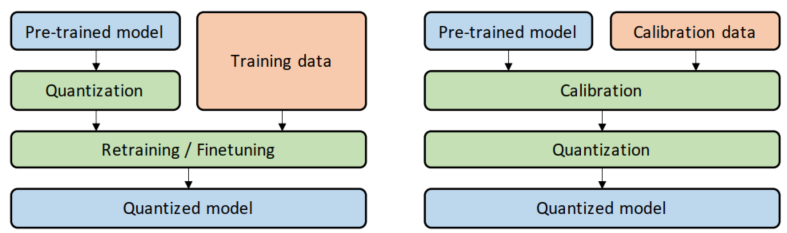
训练后量化 PTQ: 使用一批校准数据对训练好的模型进行校准, 将训练过的FP32网络直接转换为定点计算的网络,过程中无需对原始模型进行任何训练。只对几个超参数调整就可完成量化过程, 且过程简单快速, 无需训练。
量化感知训练 QAT: QAT的关键思想是在模型训练过程中引入量化的操作,让模型“意识”到量化过程,并通过反向传播优化模型参数,以适应量化带来的影响。具体来说,QAT遵循以下步骤:
- 模拟量化:在模型的前向传播过程中,将权重和激活值通过量化和反量化的过程,模拟量化在实际部署中的效果。这意味着,权重和激活值先被量化到低位宽的整数表示,然后再被反量化回浮点数,以供后续的计算使用。
- 优化参数:通过模拟量化的前向传播和梯度近似的反向传播,模型参数在训练过程中得到优化,使模型适应量化后的表示。
- 梯度近似:由于量化操作(如取整)是不可微分的,为了在反向传播过程中计算梯度,QAT采用了梯度近似的技术。常见的方法包括直接通过量化操作传递梯度(即假设量化操作的梯度为1)或使用“直通估计”(Straight Through Estimator, STE)。
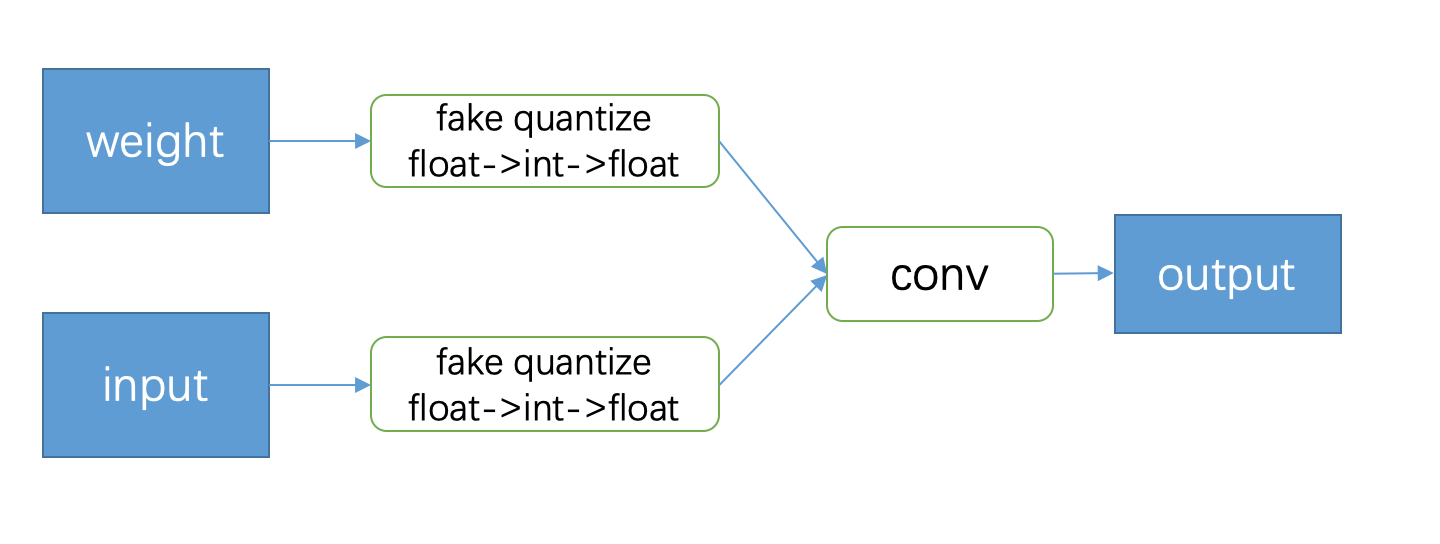
伪量化:把输入的浮点数据量化到整数,再反量化回 浮点数,以此来模拟量化误差,同时在反向传播的时候,采用Straight-Through-Estimator (STE)把导数回传到前面的层。
![]()
校准
模型量化需要校准,因为量化过程中会将浮点数值转换为有限位数的整数,这可能导致精度损失。校准通过分析激活值的实际分布,来确定最佳的缩放因子和偏移量,从而最小化量化误差。这可以确保量化后的模型在性能上尽可能接近原始模型,同时保持计算效率。
Max方法:在对称量化中直接取输入数据中的绝对值的最大值作为量化的最大值。这种方法简单易用,但容易受到噪声等异常数据的影响,导致动态范围不准确。
Histogram方法:统计输入数据的直方图,根据先验知识获取某个范围内的数据,从而获得对称量化的最大值。这种方法可以减少噪声对动态范围的影响,但需要对直方图进行统计,计算复杂度较高。
Entropy方法:将输入数据的概率密度函数近似为一个高斯分布,以最小化熵作为选择动态范围的准则。这种方法也可以在一定程度上减少噪声对动态范围的影响,但需要对概率密度函数进行拟合和计算熵,计算复杂度较高。
对称量化和非对称量化的选择与动态范围的计算方法有一定的关系。对称量化要求量化的最大值和最小值的绝对值相等,可以采用Max方法或Histogram方法进行计算。非对称量化则可以采用Entropy方法进行计算,以最小化量化后的误差。
LSQ原理
LSQ算法是一种经典的QAT算法,LSQ全称为learning Step Size Quantization;
主要的算法思想:通过插入伪量化节点,通过量化训练来学习量化参数scale并不断更新scale, 以达到量化的目的。与其他的量化训练不同的是,网络学习不仅是调整weight来适应量化误差,还加入了scale(lsq+加入了偏移offset的学习),通过对scale的学习来适应量化误差。
scale 也放到网络的训练当中,而不是通过权重来计算。也就是说,每次反向传播的时候,需要对 s 求导进行更新。
则伪量化公式,对 s 进行求导就可以得出:
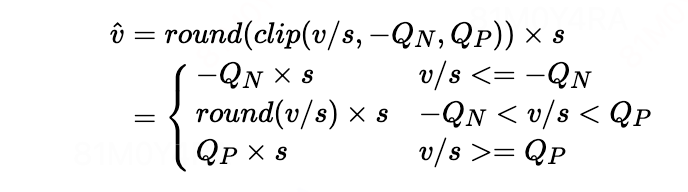
求导公式:
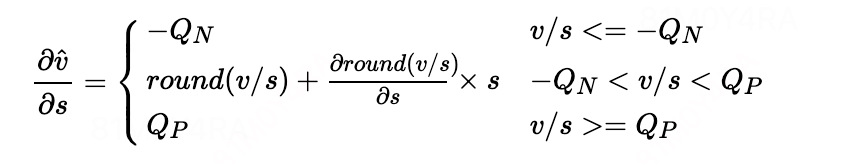
其中round(v/s) 的导数可以通过STE的到:
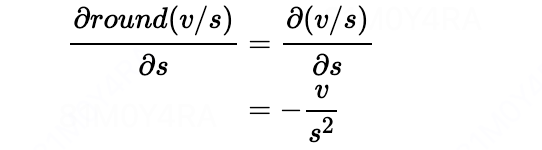
的到最终求导公式:

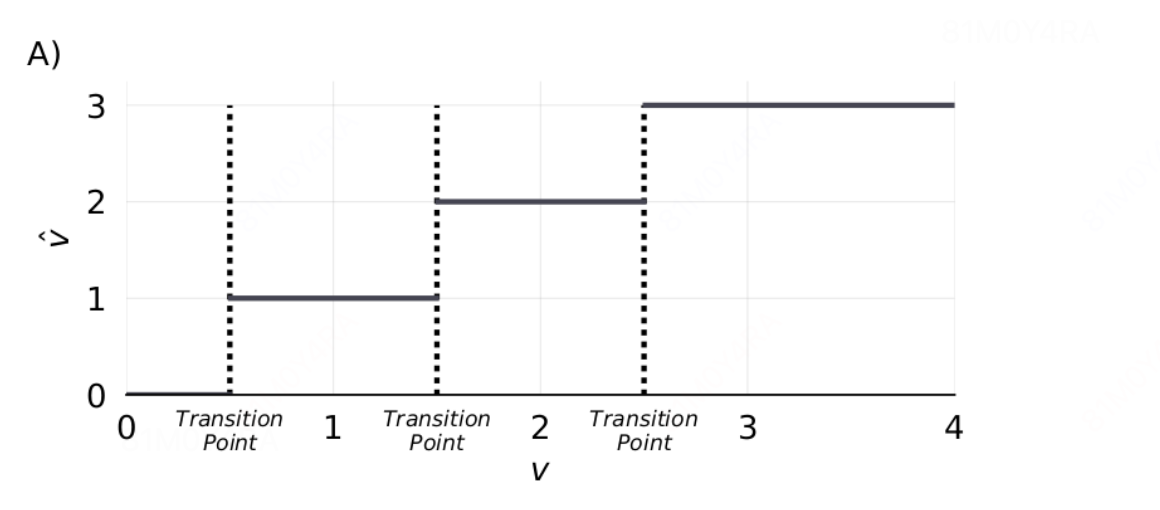
假设 量化数据v -> v^【0,3】下图表示量化前的 v 和反量化后的 v^之间的映射关系,(假设 s = 1,这里面 round 采用四舍五入的原则,则在 0.5 这个地方 (图中第一道虚线)是会从 0 突变到 1 的,从而带来巨大的量化误差。因此,从 0.5 的左侧走到右侧,梯度应该是要陡然增大的。
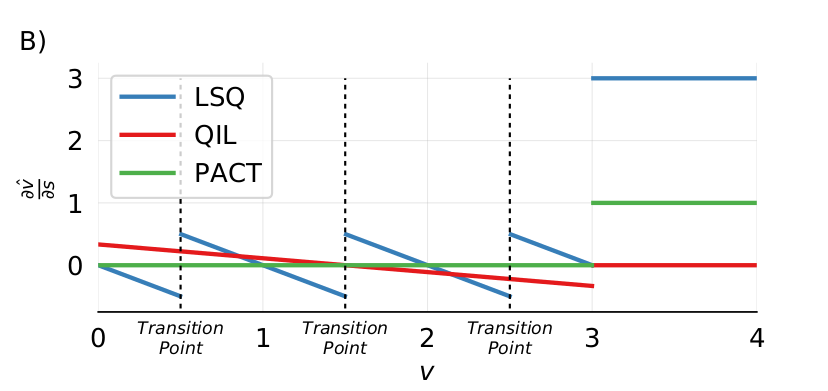
由于上述原因,期望 ∂vˆ/∂s(量化值 vˆ 对步长 s 的梯度)会随着 v 到过渡点距离的减少而增加。这意味着,当 v 更接近量化过渡点时,对步长 s 的小变化会引起 vˆ 更大的变化,从而使得 ∂vˆ/∂s 的值增大。LSQ实际的梯度变化,刚好符合这一效果。
scale的初始化方法:
![]()
研究显示,每一层参数的更新幅度与参数本身的幅度之比越接近,模型训练时收敛的越快,因此,我们考虑step size的更新幅度与step size本身的幅度之比应该也要尽可能接近权重,如下图所示
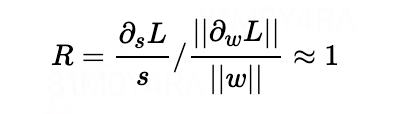
其中 ∥z∥ 表示 z 的 l2-范数。然而,我们预期随着精度的提高(因为数据被更细致地量化),步长参数会变得更小;而随着量化项数量的增加(因为在计算其梯度时需要汇总更多的项),步长更新会变得更大。为了纠正这一点,我们将步长损失乘以一个梯度缩放因子
为了保持训练稳定,作者在 s的梯度上还乘了一个缩放系数 g,
对于 weight 来说
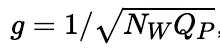
, 对于激活来说
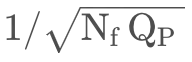
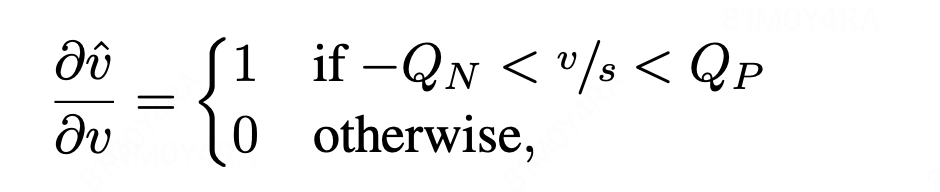
LSQ代码
class FunLSQ(Function):
@staticmethod
def forward(ctx, weight, alpha, g, Qn, Qp, per_channel=False):
#根据论文里LEARNED STEP SIZE QUANTIZATION第2节的公式
# assert alpha > 0, "alpha={}".format(alpha)
ctx.save_for_backward(weight, alpha)
ctx.other = g, Qn, Qp, per_channel
w_q = Round.apply(torch.div(weight, alpha).clamp(Qn, Qp)) #量化公式
w_q = w_q * alpha
return w_q
@staticmethod
def backward(ctx, grad_weight):
#根据论文里LEARNED STEP SIZE QUANTIZATION第2.1节
#分为三部分:位于量化区间的、小于下界的、大于上界的
weight, alpha = ctx.saved_tensors
g, Qn, Qp, per_channel = ctx.other
q_w = weight / alpha
smaller = (q_w < Qn).float() #bool值转浮点值,1.0或者0.0
bigger = (q_w > Qp).float() #bool值转浮点值,1.0或者0.0
between = 1.0 - smaller -bigger #得到位于量化区间的index
grad_alpha = ((smaller * Qn + bigger * Qp +
between * Round.apply(q_w) - between * q_w)*grad_weight * g).sum().unsqueeze(dim=0) #?
#在量化区间之外的值都是常数,故导数也是0
grad_weight = between * grad_weight
return grad_weight, grad_alpha, None, None, None, None
A(特征)量化
class LSQActivationQuantizer(nn.Module):
def __init__(self, a_bits, all_positive=False, batch_init = 20):
#activations 没有per-channel这个选项的
super(LSQActivationQuantizer, self).__init__()
self.a_bits = a_bits
self.batch_init = batch_init
self.Qn = - 2 ** (self.a_bits - 1)
self.Qp = 2 ** (self.a_bits - 1) - 1
self.s = torch.nn.Parameter(torch.ones(1), requires_grad=True)
self.init_state = 0
# batch_init控制初始化阶段的批次数量,以便在训练的早期阶段逐步调整量化参数
# 量化/反量化
def forward(self, activation):
if self.init_state==0:
self.g = 1.0/math.sqrt(activation.numel() * self.Qp) # 梯度缩放因子
self.s.data = torch.mean(torch.abs(activation.detach()))*2/(math.sqrt(self.Qp)) # scale初始化
self.init_state += 1
elif self.init_state<self.batch_init:
self.s.data = 0.9*self.s.data + 0.1*torch.mean(torch.abs(activation.detach()))*2/(math.sqrt(self.Qp))
self.init_state += 1
elif self.init_state==self.batch_init:
self.init_state += 1
if self.a_bits == 32:
output = activation
elif self.a_bits == 1:
print('!Binary quantization is not supported !')
assert self.a_bits != 1
else:
# print(self.s, self.g)
q_a = FunLSQ.apply(activation, self.s, self.g, self.Qn, self.Qp)
# alpha = grad_scale(self.s, g)
# q_a = Round.apply((activation/alpha).clamp(Qn, Qp)) * alpha
return q_a

















 6643
6643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









