







初识hadoop
- 持续更新…………
Google的“三驾马车“
- GFS
- 即The Google File System,描述了一个分布式文件系统的设计思路。将分布式文件系统划分为两个部分:客户端(Client)和服务端(Server)。
- 实际生活中,把客户端的文件传送到服务端,会遇到两个问题:
- 一是服务器硬盘不够大怎么办?
- 二是如果增加数据存储的可靠性?即硬盘坏了怎么办?
- 上述问题中,一可增加硬盘,或多增加主机;二可采用数据冗余存储方式,即将文件多备份几次。但增加了硬盘或主机,如果有效运行?备份的文件是在每个主机上存储一份吗?
- GFS提出了,增加一个管理节点,去管理存放数据的主机。存放数据的主机称为数据节点(DataNode),而上传的文件会按固定的大小进行分块,数据节点上保存的是数据块,并不是独立的文件。

- MapReduce
- BigTable
HDFS
-
HDFS是什么?
- HDFS是基于流数据访问模式的分布式文件系统,支持海量数据的存储,允许用户将成百上千的计算机,组成存储集群。
- 优点:可以处理超大文件、支持流式数据访问(一次写入,多次读取)、低成本运行。
- 缺点:不适合处理低延迟的数据访问,主要处理高数据吞吐量的应用;不适合处理大量的小文件,这样会浪费NameNode内存;不适合多用户写入及任意修改文件。
-
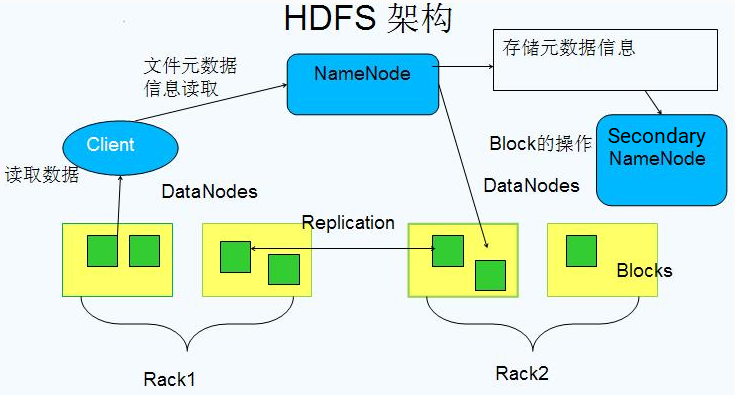
HDFS的组成架构
-
NameNode
- NameNode即名称节点,是HDFS的管理者。
-
主要功能(三个):
-
管理和维护 HDFS 的命名空间:命名空间镜像文件( fsimage ),操作日志文件( edits )
- fsimage:存储 hadoop 文件系统中的所有目录和文件的序列化信息
- edits:记录 HDFS 最新状态, HDFS 客户端执行的所有写操作记录在 editlog 中
-
管理 DataNode 上的数据块:在 HDFS 中,一个文件被分成一个或多个数据块,这些数据块存储在 DataNode 中, NameNode 通过“文件名–>数据块”映射或者“数据块–>DataNode”来确定
-
接收客户端的请求
-
DataNode
- 每个磁盘都有默认的数据块大小,它是磁盘进行读、写的最小单位,HDFS默认数据块大小为128MB。数据块如此大,目的是减少寻址开销,减少磁盘一次读取时间。
- 功能:
- 保存数据块:每个数据块对应一个元数据信息文件,用来描述该数据块属于哪个文件,是第几个数据块
- 运行 DataNode 线程,向 NameNode 定期汇报数据块信息
- 定期向 NameNode 发送心跳信息保持联系
-
SecondaryNameNode
- 即第二名称节点,主要职责是定期把 NameNode 的 fsimage 和 edits 下载到本地,并将它们加载到内存进行合并,最后将合并后的新的 fsimage 上传回 NameNode ,此过程称为检查点 ( CheckPoint )。
- 定期合并 fsimage 和 edits 文件,使 edits 大小保持在限制范围内,减少重新启动 NameNode 时合并 fsimage 和 edits 耗费的时间。
-
-
HDFS Shell
- HDFS Shell 命令是用类似于 Linux Shell 的命令,来操作文件系统。
- 如:
hdfs dfs -ls,列出文件或目录。
-
HDFS API
- 当然, Hadoop 提供了多种 HDFS 的访问接口,其中 Java API 是指可用代码的方式来操作文件系统。
-
HDFS Java API 的一般用法:
-
实例化 Configuraion 类
-
Configuration conf = new Configuration(); -
Configuration类封装了客户端或服务器的配置,Configuration 实例会自动加载HDFS的配置文件core-site.xml,从中获取 Hadoop 集群的配置信息。
-
-
实例化 FileSystem 类
FileSystem fs = FileSystem.get(uri,conf,"username"); //uri是URL类的实例,username表示用户名- FileSystem 类是客户端访问文件系统的入口,是一个抽象的文件系统类。
-
设置目标对象的路径
Path path = new Path("/test")- HDFS Java API 提供了 Path 类封装 HDFS 文件路径。Path 类位于
org.apache.hadoop.fs包中。
-
执行文件或目录操作
得到 FileSystem 实例后,就可以使用该实例提供的方法进行操作,如打开文件、创建文件、删除文件等。
FileSystem 类常用方法:
方法名称及参数 返回值 功能 create(Path f)FSDataOutputStream 创建文件 open(Path f)FSDataInputStream 打开指定文件 delete(Path f)boolean 删除指定文件 copyFromLocalFile(Path src,Path dst)void 从本地磁盘上传文件到HDFS copyToLocalFile(Path src,Path dst)void 从HDFS下载文件到本地磁盘 …… …… ……
- 高可用 HA
- HDFS HA 是指 HDFS High Available ,即 HDFS 高可用性。
- 一个集群通常只有一个 NameNode ,所有元数据由唯一的 NameNode 负责管理 。如果该主机或进程变得不可用,直到 NameNode 恢复前,整个集群将无法使用。
- HDFS 通过在同一集群中运行两个冗余 NameNode 的方法来解决上述问题,这就是HDFS的高可用性。
- 如此而来,当一个 NameNode 不能提供服务时,可以快速将服务转移到另一个备用的 NameNode。

- 联邦 Fedeeration
- HDFS 的 Federation ,即 HDFS 联邦,是指在 HDFS 中有多个 NameNode 或 NameSpace ,这些 NameNode 和 NameSpace(NS)是联合的,它们相互独立且不需要互相协调,各自分工,管理自己的区域。
- 每个 NameNode 都有自己的数据块池(Block Pool),池与池之间也是独立的,且一个 NameNode 挂掉了,不会影响其他的 NameNode, 但所有数据块池都共享一个 HDFS 的存储空间。

YARN
- Hadoop YARN:Yet Anther Resource Negotiator,另一种资源协调器。
- YARN 是 Hadoop 的资源管理器,它是一个通用的资源管理系统,为上层应用提供统一的资源管理和调度。
- 背景
一个小型电子加工厂,在刚开始时规模比较小,只有1个老板和3个员工 ;
随着业务增多,客户数量增多,订单增多,工人也会增多,则会遇到一下问题:
- 有订单时,老板要对任务进行分配,并且要对任务进度进行把控,但是人多事多,老板如何合理调控?
- 太多的订单,规模不同,需要员工的数量也不同,且订单交付时间有先后,哪些先做,哪些后做,这也成了一个问题。

- 在 MapReduce 架构由 Client ,JobTracker,TaskTracker组成。
- JobTracker 负责资源管理和所有作业的控制, TaskTracker 负责接收来自 JobTracker 的命令并执行。
- 其中,JobTracker 需要负责作业调度,又要负责任务的进度监控,所以若 JobTracker 访问压力过大,集群就会出现性能瓶颈,就会影响系统扩展性。

- 初识 YARN
- YARN 最初的目的是改善 MapReduce 的实现,后来演变为一种资源调度框架,具有通用性,可为上层应用提供统一的资源管理和调度,可以支持其他的分布式计算模式。
- 在启动 Hadoop 后,若出现
ResourceManager和NodeManager即为 YARN 的主要进程。
- YARN 的架构
- YARN 由 Container 、 ResourceManager 、 NodeManager 、ApplicationMaster 组成。

- Container 容器
YARN 中的资源包括内存、CPU、磁盘输入/输出等。Container 是 YARN 中的资源抽象,它封装了某个节点行的多维度资源,YARN 会为每个任务分配 Container。
- ResourceManager 资源管理器
RM 负责整个系统的资源分配和管理,是一个全局的资源管理器,由















 2067
2067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









