







- 鸢尾花数据集
# 导入鸢尾花数据集
from sklearn import datasets
iris = datasets.load_iris()
list(iris.keys()) # 查看属性
对于传统逻辑回归,需要对标签进行变换,也就是将正类置为1,其它置为0。
X = iris['data'][:,3:] # 取一个特征:petal width
y = (iris['target'] == 2).astype(np.int) # 转为二分类问题,目标值为0,1
概率结果随特征值的变化
# 导入逻辑回归模型
from sklearn.linear_model import LogisticRegression
log_res = LogisticRegression()
log_res.fit(X,y)
# 测试集
X_new = np.linspace(0,3,1000).reshape(-1,1) # 改变维度为d行、m列 (-1表示行数自动计算,d= a*b /m )
# 预测概率值
y_proba = log_res.predict_proba(X_new)
y_proba有两列数据,其和为1
# 画图
plt.figure(figsize=(12,5))
# 决策边界
decision_boundary = X_new[y_proba[:,1]>=0.5][0]
plt.plot([decision_boundary,decision_boundary],[-1,2],'r:',linewidth=2)
plt.plot(X_new,y_proba[:,1],'g-',label='Iris-Virginica') # 是当前类别
plt.plot(X_new,y_proba[:,0],'b-',label='Not Iris-Virginica') # 不是当前类别
plt.legend(loc = 'center left')
# 箭头
plt.arrow(decision_boundary,0.08,-0.3,0,head_width=0.05,head_length=0.1,fc = 'b',ec = 'b')
plt.arrow(decision_boundary,0.92,0.3,0,head_width=0.05,head_length=0.1,fc = 'g',ec = 'g')
plt.xlabel('Peta width(cm)',fontsize=16)
plt.ylabel('y_proba',fontsize=16)
# 备注
plt.text(decision_boundary+0.02,0.15,'Decision Boundary',fontsize=16,color='k',ha='center')
plt.axis([0,3,-0.02,1.02])
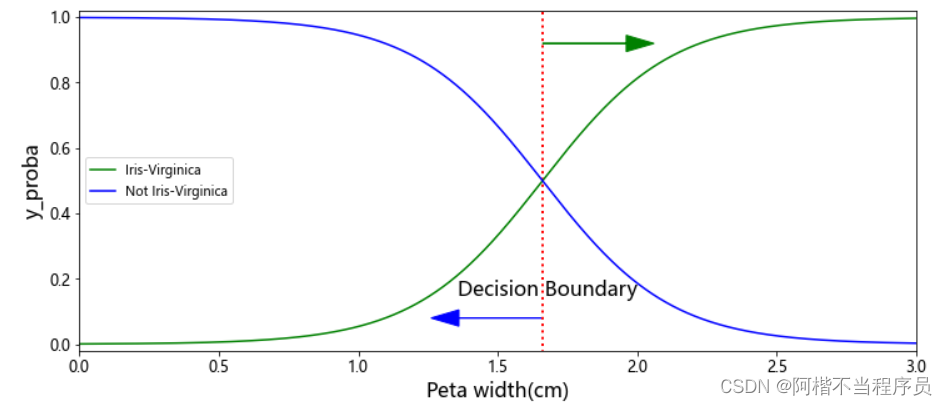
随着特征值的增加,判断是该类别的概率在增加;
特征值在曲线交叉部分的概率接近50%,是最难分辨的。
当特征值超过决策边界,倾向于是;反止,倾向于不是。
分类决策边界展示
-
构建坐标数据,在合理的范围中,根据数据来决定
-
整合坐标点,得到所有测试输入的数据坐标点
-
预测,得到所有点的概率值
-
绘制等高线,完成决策边界
# 构建坐标
x0,x1 = np.meshgrid(np.linspace(2.9,7,500).reshape(-1,1),np.linspace(0.8,2.7,200).reshape(-1,1))
# x0与x1组合,类似笛卡尔积
X_new = np.c_[x0.ravel(),x1.ravel()]
# 预测概率值
y_proba = log_res.predict_proba(X_new)
plt.figure(figsize=(10,4))
plt.plot(X[y==0,0],X[y==0,1],'bs')
plt.plot(X[y==1,0],X[y==1,1],'g^')
# 等高线
zz = y_proba[:,1].reshape(x0.shape) # 取一个特征作为正类
contour = plt.contour(x0,x1,zz,cmap=plt.cm.brg)
plt.clabel(contour)
plt.axis([2.9,7,0.8,2.7])
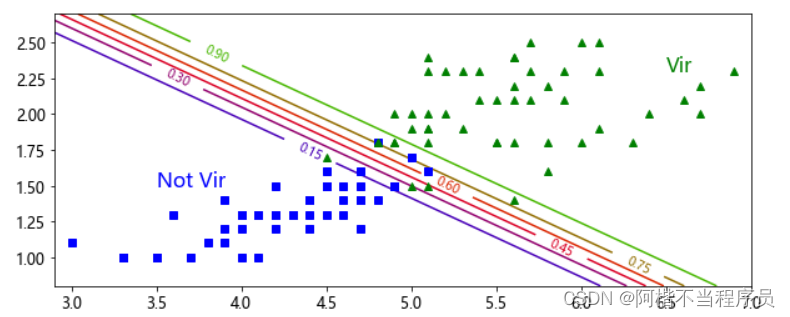
等高线越接近绿色三角分类,概率值越大。
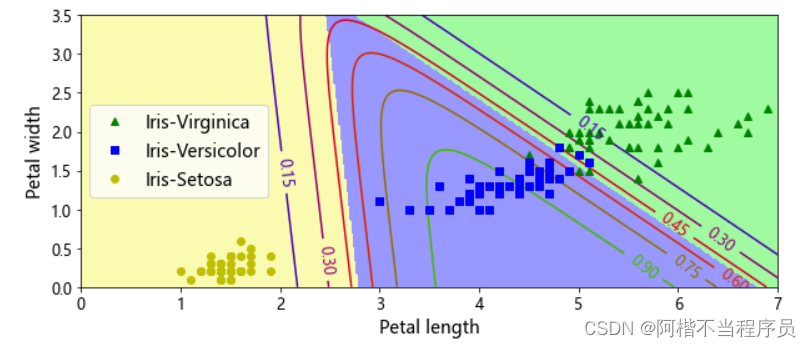
多分类Softmax
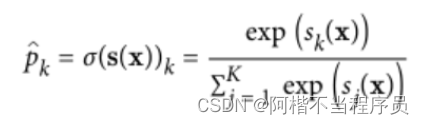
对数据都取以e为底的操作,放大各数据之间的差距,然后进行归一化,得到概率值。
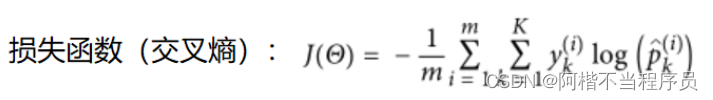
通过log函数进行映射。
X = iris['data'][:,(2,3)] # 取两个特征
y = iris['target']
# 建立模型
softmax_reg = LogisticRegression(multi_class='multinomial',solver='lbfgs') # 指定多分类
softmax_reg.fit(X,y)
# 打印出三个类别的概率值
softmax_reg.predict_proba([[5,2]])
# array([[2.43559894e-04, 2.14859516e-01, 7.84896924e-01]])
# 画图:决策边界
x0, x1 = np.meshgrid(
np.linspace(0, 8, 500).reshape(-1, 1),
np.linspace(0, 3.5, 200).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_proba = softmax_reg.predict_proba(X_new)
y_predict = softmax_reg.predict(X_new)
zz1 = y_proba[:, 1].reshape(x0.shape)
zz = y_predict.reshape(x0.shape)
plt.figure(figsize=(10, 4))
plt.plot(X[y==2, 0], X[y==2, 1], "g^", label="Iris-Virginica")
plt.plot(X[y==1, 0], X[y==1, 1], "bs", label="Iris-Versicolor")
plt.plot(X[y==0, 0], X[y==0, 1], "yo", label="Iris-Setosa")
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
contour = plt.contour(x0, x1, zz1, cmap=plt.cm.brg)
plt.clabel(contour, inline=1, fontsize=12)
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
plt.legend(loc="center left", fontsize=14)
plt.axis([0, 7, 0, 3.5])
plt.show()















 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









