







Go语言并发微服务分布式高可用
Go语言基础语法
目标是中高级岗位
2门语言
JavaScript,js ES,前端唯一语言
Vue
Python语言:并发举例用
基础重要吗?
重要(各种原理并发、数据库、网络、内存),面试经常问,再一个拼实力用,内功理论水平决定了你的未来知识的高度
项目重要吗?
重要,面试也要问,职场经验,减少单位筛选成本,增删改查
综合能力,职场经验,理论水平,团队能力,谈吐。
go发展和设计哲学
go开发环境安装
环境安装
命令行输入go,当前操作系统OS环境中依赖于PATH指定的目录们去找命令(可执行文件)
windows会优先搜索当前目录,当前目录没有才依赖PATH中指定的目录

环境变量: 操作系统运行环境中提前定义好的变量
PATH: 如果你在命令行中输入了一段字符,shell要解析它,被解释为可执行的文件(命令)
命令:某些程序员写好的可执行文件
GO运行环境
GOROOT: GO的安装路径 c:/go/1.20.4
GOPATH:
当前用户家目录/go ~/go $HOME/go,
目前第三方包安装目录
第三方包如果install就要编译可执行文件,就放在bin日录中
pkg目录: 缓存 第三方包文件
bin目录: 第三方包通过go install命令下载并编译好的可执行文件的存放处
dlv 调试go代码
gopls go的自动完成、编辑支持等
go install 命令:下载第三方包到$GOPATH/go/下面的缓存包文件们到该目录,编译好可执行文件放到$GOPATH/go/bin
go get命令:下载第三方包到$GOPATH/go/下面的缓存包文件们到该目录,以后编程用这些包
如何知道该go install还是 go get,官方文档会告诉你
PATH:增加了~/go/bin目录 等价于 GOPATH + bin
$GOROOT/bin 必须,go在这里
$GOPATH/go/bin 必须,bin? binary 二进制,为了编译好可执行文件放在这里
Linux环境变量 冒号间隔,windows用分号
GOPROXY: https://mirrors.aliyun.com/goproxy/
手动安装
解压tar xf xxx.tar.qz -C /usr/local/
配置以上4个环境变量
测试> go version
开发环境
收费Goland
免费 VSCode
Js ES TS第一工具插件
outline map 查阅代码
postfix .xxx! 自动补全常用代码
Go语言开发
命令行
菜单打开 view/Termina1开启命令行
ctrl + j
第一个程序
pkgm
如何调试代码
1 $ go run main.go
2 F5
go mod init xxxxx
产生一个go.mod
自动保存当前文件开始编译调试
go install -v github.com/go-delve/delve/cmd/dlv@latest
go install -v golang.org/x/tools/gopls@latest
go install -v honnef.co/go/tools/cmd/staticcheck@latest 代码检查
go命令
go install 命令:下载第三方包到$GOPATH/go/下面的缓存包文件们到该目录,编译好可执行文件放到$GOPATH/go/bin
go get命令:下载第三方包到$GOPATH/go/下南的缓存包文件们到该目录,以后编程用这些包。如果开启了go modales,包依赖记录在go.mod中
go get -u 包
go mod命令: 开启go mudules,启用模块化(包管理),标志go.mod文件
go mod init 名字
go mod tidy 扫描当前项目,从go.mod文件中把不依赖的第三方包移除,也可以把依赖的第三方包加进来
go version 打印版本
go env 打印go环境的环境变量
go build 编译
go run 直接进行go build
计算机基础知识
冯诺依曼体系
五大部件
CPU:
运算器 一般你给的一个任务,CPU要花几个滴答来完成
假设3个滴答完成一次计算,请问频率高、低哪个省时间?主频越高越好,但是频率有天花板,所以上多核
控制器
存储器Memory: 内存,掉电丢失,速度快
输入设备Input:数据输入
输出设备output:
主板: 类比为骨架和神经系统
芯片组:
显卡: 数宇信号输入给显卡,显卡输出到显示器
总线Bus: 数据总线、控制总线
内存
运行内存:掉电丢失的芯片
内部存储内存: 相当于掉电不丢失的便盘
输入输出设备不跟CPU直接打交道,CPU必须直接和内存进行数据交换。CPU当中没有地方放大量数据
CPU中
寄存器,寄存器是为了计算所需数据
缓存cache
时钟振荡器
按照一个频率跑,触发数字电路工作,滴答声越快频率越高,CPU就越快
所有的数字设备都要利用产生的脉冲信号工作
CPU运行频频率是最高的 3.xGhz
内存次之 DDR 双边沿触发 运行速度远低于 CPU TB。Redis
外设: IO设备,慢设备,慢的要死 PB,大量的数据放在外设存储

时钟振荡器
按照一个频率跑,触发数字电路工作,滴答声越快频率越高,CPU就越快
所有的数宁设备都要利用产生的脉冲信号工作
CPU运行频率是最高的 3.xGhz
内存次之 DDR 双边沿触发 运行速度远低于 CPU TB。Redis外设:IO设备,慢设备,慢的要死PB,大量的数据放在外设存储
计算机运行: CPU运行指令,只认机器指令指令
0001 加法
0001
0010
00000001 00000001 00000010
3个字节byte,24bit位,指令表示,第一个字节是单字节指令,查指令表发现是加法,需要2个操作数,提供2个字节,每个数占一个字节
1 + 2=3 => 内存保存3
计算机世界只有数字,把数字赋了不同的意义就有不同的作用
汇编语言
00000001 00000001 00000010
ADD 00000001 00000010
ADD会转换成对应的指令数字,靠汇编器
语法基础
语法基础及命名规范和标识符
布尔数值、字符串
字符类型
浮点型和进制
UserName 驼峰,首字母大写大驼峰
userName小驼峰
user_name snake 蛇形命名
a =100 a指代100,a就是指代100的一个名称,标识符
100 是数字,常量,不可变的值,字面常量
100 + 1 = 101,100还是那个100,1还是那个1, 101就是101
100 +2
100 +3
a + 1
a + 2
a + 3
a = 200 说明 a的指代可以变化,a变心了,可以变化指代值的标识符,称为 变量标识符
如果说a的指代一旦关联,不可变,a这个标识符指代的值不能改变了,称为 常量标识符
1.25
true
false iota
nil
"ab"+"c" = "abc"
var 变量名
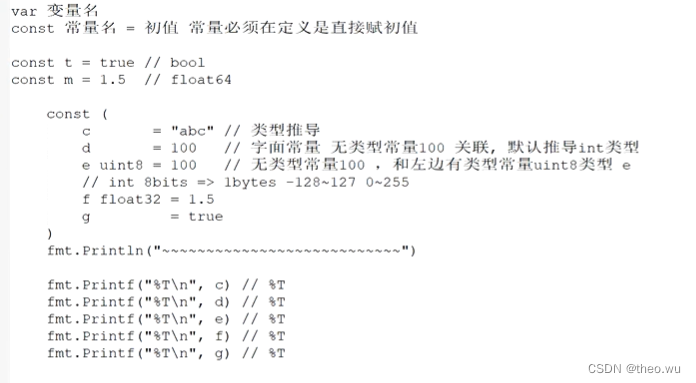

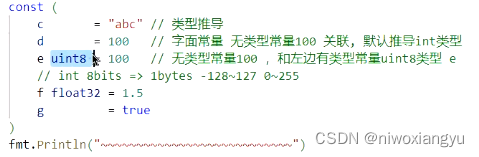

总结: iota是在成批定义和序列有关的常量定义
其他语言中
const a = [1, 2]
a = [1] // 不可以
go语言中,常量不可以用数组
a = "abc"赋值语句,名称是a,被赋值,a是一个指代,指向某个值
a = 100
如果可以,再次可以赋值,a称为变量,a的指代可以发生变化
如果不以
a有类型要求,不可以改变类型,同类型可以再次赋值,a是变量 (a=100不可以,a="aaa"可以)
a就是不可以再被赋值,a和第一个赋给它的值之间的联系不可改变,a称为常量标识符
常量:标识符的指向的值一旦建立,不可改变,要求定义是必须建立关联
变量:标识符的指向的值建立后,可以改变
1类型也可以变,往往动态语言JS、Python,举例 a = 100,a="abc",a=[1,2,3]
2同类型可以变
const a ="abc"
赋值语句,右边是无类型常量,它的缺省类型是string,左边a没有指定类型,a会进行类型推导,会依赖右边的类型,所以,a被推测为string类型
类型推导可以用在常量、变量定义,包括批量定义时
var a int,b string // 不支持,批量定义 var ()
var a int,b int // 不可以
var a,b int // 可以,如果要写在一行,必须同类型,只需要在最后指定类型就行。该例子用零值var c,d int = 100,200 // 如果要写在一行,必须同类型,只需要在最后指定类型就行。可以赋值,但要全部对应给出值
变量的短格式
b // 不是短格式,什么都不是,不是赋值语句,也没有const、var
a := 100 // 赋值语句,短格式变量定义语句,定义变量。定义了变量标识符a,右边可以用来推导a的类刑为int
var a int //零值0
// a := 200 // 重复定义
ab := 123,"abcd"// 竟然可以? 在这里a不能重新定义为新类型,a被检测到了,go语言上只能迁就你了,但是要求a同类型,b是新定义的
TODO
var a int32 = 123 // 正确,指定了类型,也赋值。不会不用类型推导 TODO,隐式类型转换
// const // 全局常量
var (// 全局变量,顶层代码
a=100
b = "abc"
)
标识符写源代码时候,用来指代某个值的。编译后还有变量、常量标识符吗?
没有了,因为数据在内存中,内存访间靠什么? 地址,标识符编详后就没有了就换成了地址了
源代们本质是文本文件
编译 ,源代码编程成一进制可执行文件
运行这个磁盘上的二进制可执行文件,运行在当前OS上,变成进程,进程要不要占内存空问,要的吗?变量、常量、值在这块内存中放者

bool在go中不是int类型,也不是其他整数类型。在go中,bool就是布尔型,和整型没有关系,就是完全不同的类型
GO是对类型近乎苛刻的语言
int、uint、int64、uint64,这四个都是完全不同的类型,不能互操作
计算机世界只有二进制数据,每一个位bit表示0或者1,最多表达2种可能性
有符号、无符号类型
u unsigned 无符号,以int8、uint8
8bits,总共能够表达256种状态
int8,1 byte,8 bits,表示正负数将最高位留出来不能表示数据状态,用0表示负,用1表示正,剩余7位表示数字
能够表示多少个不同的数字呢? 256种状态
uint8,1字节,8位,不能表示负数,所有的8位都用来表示数字
能够表示多少个不同的数字呢? 256种状态

强制类型转换:显式 指明 类型转换,有可能失败
fmt .Println(a + int (m)) // int (m)
string(整数值看做是ascii或unicode码) 去查编码表
var c rune = 300 // type rune = int32 类型 别名,type定义时使用了 = ,你等于我,你就是我
type myint int32 // 特别注意这里没有等号=,这不是别名
fmt.Println Print line 输出到控制台换行
fmt.Printf("%[2]T 号[1]d\n",rune(m),string(m)) 值从1开始编 %[index]? 下一个如果没有指定索引,索引默认是index+1
fmt.Printf("%T %T %T %T \n", a, b,c, a t b + c) // format
Printf 往控制台打印,f是format
%T 占位符,和后面的值依次对应
%T 表示type,取值的类型
%d digital 数值形式,往往用于整数
%s用string类型的值
%q带字符串类型引号的%s,quote引号



0o101 => 0b 001 000 001 => 0b0100 0001 => 0x41 => 65
内建数据结构
转义字符
字符串格式化及操作符
指针
分支循环
随机数及scan
单引号留给了表示字符,字面量表达,本质上是int32 (rune) 或byte (uint8)
双引号和反引号用来表示字符串字面量。
反引号
其中使用双引号、单引号
多行
主要用途: 结构体tag使用
字符串或字符中,占用的字节数(因为我们要关心内存占用和磁盘占用),显示中在不同的显示设备中展示的显示宽度
tab对应的显示宽度可以调整
12345678
x y
xyz y
xxxxxx y
xxxxxxxx y
"x\ty\n\" 'z'\""
x\ty\n\" 'z'\"


 *int 指向int类型数据的指针
*int 指向int类型数据的指针
0xc000018088 表示门牌号码
门里面房间里面住着数据
赋值在Go中,往往是建立副本
if 后必须是bool
switch 后面是什么类型? 写什么类就是什么类型。 如果switch后面不写,默认为bool
循环
for i:=0;i,5;i++ {
fmt.Println(i)
}
1、i:=0 init 初始化,在循环开始之前,只能执行一次
2、i< 5 bool,中间部分只能是bool值,bool值是true才能执行后面花括号里面的语句一趟,如果是是false终止循环
如果要执行第二趟,需要再次test检验这个表达式的值是否是true,如果是是true,继续,是false终止循环
3、i++,循环体如果执行过一次的结尾时执行
continue
break
for range 容器类型,容器内所有元素遍历
遍历
按照某种顺序输出(线性化) ,不重复的把所有元素输出出来
对容器里面元素是否有序没有要求
xyz测试 字符串utf-8编码
0123 6
fmt
Print*
Scan*
双层循环
数组、切片
线性数据结构
线性表原理
数组
切片原理及使用
抽象概念
线性表,表,有序序列,放元素,是一种有序的放元素的容器,抽象概念数学概念
物理实现:内存中怎么表达该序列。内存是线性编址的,内部把存储单元小格子编了号
顺序表:使用连续的内存单元存储该序列的所有元系,内存的顺序就是数据顺序
排好的队伍,数组Array
C
U
D
R
链接表:每一个元素存储在内存中,但是元素并不是连续的存储在内存中,散落内存的不同位置,前一个元素指向下一个元素(链接)
简称链表
手拉手
单向:前一个元素指向下一个元素
双向: 前一个元素指向下一个元素,下一个元素指向上一个元素
列表List往往都是链表实现。Python例外
个元素
C
U
D
R
可变
元素可变
容器可变
CRUD 遍历,create增,Read 读取,Update 改,Delete删

顺序sequence不是排序sort
C
容器元素个数 + 1
append如同排队,在队尾后增加即可
insert插队
最尾巴后插队,就是append中间插队,占用当前位置,把当前位置与其后所有数据后移
队首插队,所有元素统统后移
挪动数据是要耗时间的,挪动的元素越多(规模越大),代价越大
D
容器元素个数 - 1
pop队尾元素移除,影响最小
remove
如果是队尾,就是pop
中间离队,后面数据统统前移
队首离队,后面数据统统前移
挪动数据是要耗时间的
U
元素个数len 不变
定位问题
更新内容
R
定位问题:
使用索引,首地址 + 该类型的字节数 * 偏移,所以,定位要用索引计算得到元素的内存地址,不用遍历,效率极高。
顺序表不管有多少个元素,都是一个四则元素公式直接推出来如果
使用内容定位,内容比较,遍历的方式挨个比较内容,效率低下。最不幸,遍历完了,才知道没有
获取内容:使用索引直接定位该位置,拿走内容
遍历:容器中的元素,不管有没有顺序,我们都要不重复的将所有元素挨个揽一遍。首地址开始始,挨个偏移取内容
前提: 要数据规模,如果数据规模小,随便你玩。数据规模大,都是事
顺序表适合仅仅在尾部增删扩容问题
链接表:每一个元素存储在内存中,但是元泰并不是连续的存储在内存中,散落内存的不同位置,前一个元素指向下一个元素(链接)
简称链表

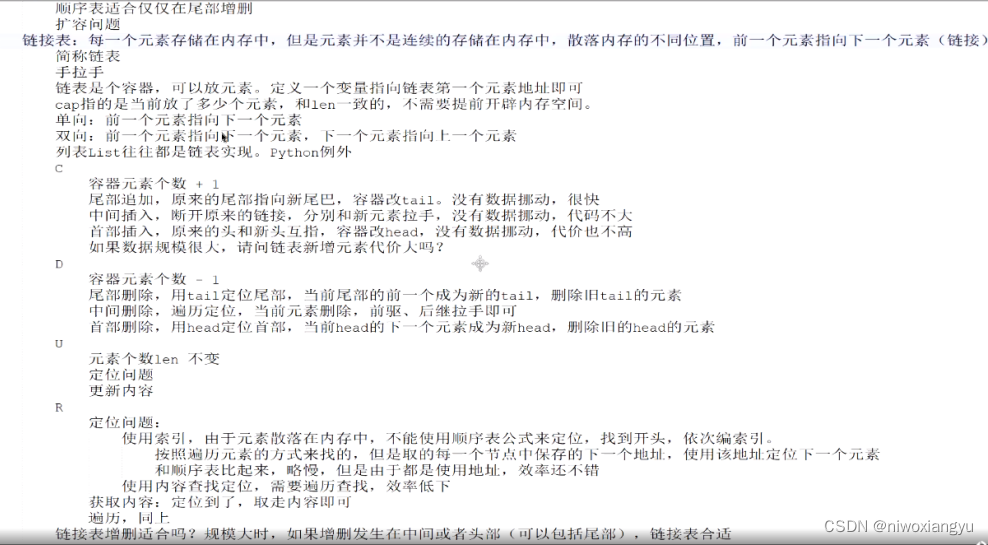
我手里有一个内容,我想问该线性表中有没有? 请向用什么物理存储合适? 就不该使用线性表,都不好,因为是遍历。如果只有5个元素,随使你。如果规模很人呢? 索引规模大就不要用线性表。我手里知道索引,请问用什么线性表存储? 顺序表更快定位
我手里有索引,我要使用索引插入数据或删除数据,用什么? 链接表更合适。如果删除或增加都集中在尾部,更适合用顺序表,但是数据增加较多的话,顺序表开始扩容较为频繁,不如使用链接表。
操作是增删随意且需要经常使用索引定位数据,用什么 如果数据规模小,且增删较少,使用索引定位多,可以考虑使用顺序表。但是规模大增删操作随意且多,就只能使用链接表。

可变
元素可变
容器可变。Go中数组是容器不可变的
CRUD 遍历,Create增,Read 读取,Update 改,Delete删
二分法查找有一个前提,就是已经为元素排过顺序了,而排序非常非常耗时,非必要不要做排序sort
数组
容器不可变,容器的元素个数不能变了。数组必须给出长度,以后数组这个容器不能增删元素了,不能扩容了。长度是死的,必须定义时给出
[...]int{} [常量]int
里面有元素,元素的内容可变
顺序表实现
可以索引
值类型?
索引: 0到len(array)-1, 使用索引是最快定位方式了
内存结构
数组地址就是数组第一个元素的地址 (c语言 )
每个元素占用空间看元素类型,int动态类型,当前机器上是8完节
一个元素占用几个字节和类型有关,第一个元素的存储单元后面一定是第二个元素的存储单元,顺序表
字符串字面常量,一旦定义不可改变,不同的字符串长度不一,数组采用string为元素,间隔怎么办?测试后发现元素存储空间间隔一样,都是16宁节,说明字符串比你想象的复杂一些。16个字节里面放了一个指针,指向字符串的内存位置

切片
子切片原理、常见线性数据结构
ASCII讲解、Strings库
切片
容量可变,所以长度不能定死
长度可变,元素个数可变
底层必须使用数组引用类型,和值类型有区别
切片一定要关注len和cap
内存模型
组合结构
1 底层数组,数组容量不可变,元素内容能变
2 slice header标头值或slice descriptor描述符
type slice struct f
array unsafe.Pointer // 指针,指向底层数组的首地址
len int // 表示当前切片的元素个数
cap int // 表示当前切片可以最多放几个元素
注意上面三个结构体的属性都是小写,所以包外不可见。len函数取就是len属性,cap函数取cap属性。指针可以通过取底层数组的第一个元素的地址,即切片第一个元素的地址
组合结构
1 底层数组,数组容量不可变,元素内容能变
2 slice header标头值或slice descriptor描述符
type slice struct {
array unsafe.Pointer // 指针,指向底层数组的首地址
len int // 表示当前切片的元素个数
cap int // 表示当前切片可以最多放几个元素
注意上面三个结构体的属性都是小写,所以包外不可见。len函数取就是len属性,cap函数取cap属性。指针可以通过取底层数组的第一个元素的地址,即切片第一个元素的地址
var a1= make([]lint,1,5)切片长度len为1,容量cap为5,本质上数据的存储利用底层数组,元素是存储在底层数组中,打印[0]
var a0 = []int{10, 11, 12}
[]int 切片类型
元素有3个,len为3;容量cap为3
打印[10 11 12]
&a0表示切片的地址,header这个结构体的地址
&a0[0] 第一个元素的地址,由于第一个元素存在底层数组中,数组的第一个元素地址就是数组的地址
append(切片,1) append(切片,1,11,111)

指针可以通过取底层数组的第一个元素的地址,即切片第一个元素的地址
var a1 = make([]int,1,5) 切片长度len为1,容量cap为5,本质上数据的存储利用底层数组,元素是存储在底层数组中,打印[0]
子切片
选取当前切片的一段等到一个新的切片,共用底层数据(因为不扩容),但是header中的三个属性会变
slice[start:end] 前包后不包
cap的意思是,从header中指针开始向后到底层数组的最后一个元素的位置还能容纳几个元素
len = end - start,从指针开始用几个元素

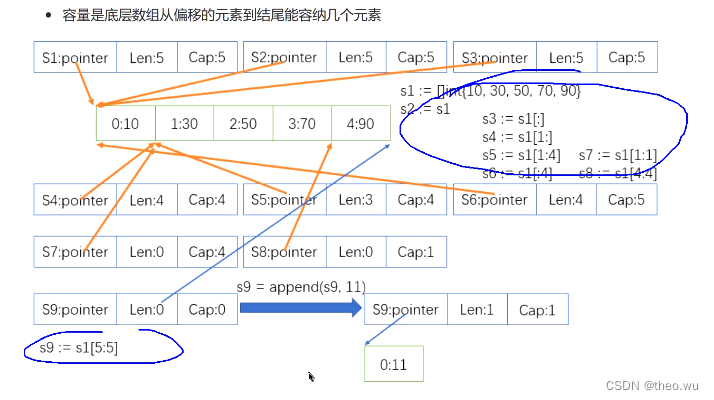
Go切片增加元素好不好? Go只提供了append,why? 因为尾部追加影响最小。如果爆了只需要扩容。但扩容不要太频繁,最后创建时一次性给够。不希望对切片这个顺序表在中间或首部插入
GO认为频繁对线性数据结构增删,应该用链表。尾部链表直接使用内部保持tail指针直接找尾部
子切片是使用原切片一段,不会引起数据的增删
线性数据结构
顺序表: CRUD,数组。GO中数组、切片,线性数据结构的物理实现
链接表: CRUD,list,线性数据结构的物理实现
栈stack:子弹夹 后进先出LIEO,不可以首部、中间操作
逻辑
队列Queue,消息中间件 (消息队列)一般队列不允许中间操作,不提供中间操作的方法
先进先出FIFO ,不可以中间和尾部移除,首部移除:增加只能在尾部,中间和首部不可以插入
物理实现?链接表。因为头部移除,对于顺序表代价高,其后元素往前挪动使用双端队列实现
后进先出LIFO stack,只能尾部追加,尾部移除
物理实现?
顺序表可以。但是顺序表扩容,需要连续的大空间
链接表可以,更合适,多数使用链表实现的
stack底层是使用双端队列实现
双端队列 deque
两头操作,操作只能在两头,尾部追加或移除,首部插入或移除,中间不可以操作
物理实现?链表实现
首部或者操作或尾部操作呢?
优先队列,数据结构是堆(小顶堆实现),不是线性数据结构实现的
编码表
信息化,数据都二进制化
0x61 0b0110 0001
int,十进制的97
uint8,十进制的97
字符,认为规定a
ASCII表
数字 和 字符 映射表,包括了英文字符和标点
用1个字节,256状态,用低7位128种状态就够了,0~127,都有对应的字符,可见字符、不可见字符、控制字符
建立映射
某字符1 法文 编码表130 -》-》某字符2 德文 编码表
中文编码表
数字 到 中文单一字符映射,至少常用的3k~5k个,一个字节不够了,汉字只能使用多字节
2字节,65536种状态
GB2312
GBK
GB18030
BIG 5
所有编码表都兼容单字节的ASCII表,问题来了有一篇文章多语言字符共存,字符全是0和1?
UNICODE
多字节,一张编码表解决全球多数字符对应问题
表示汉字多数使用2个字节
Go中'x'方式,保存int32 rune整数值,%c打印通过Unicode编码表找到字符输出
UTF-8
多字节
字符串,字符序列,每个汉字就是utf8编码的,也就是汉字是3个字节,
乱码问题:编码和解码用得不是一套编码表
字符串
字符串
类型是string
"abc"
127 "127”
文本文件本质上就是长长的字符串
本质都是二进制的,从二进制角度看,存的都是某种编码的码点对应的数字。但是人喜欢字符,展示给人看得时候,应用正确的编码表来解密这些码点,找到码点对应的字符显示到屏幕,打印到纸张
len对于字符串返回的是占用的字节数
虽然可以看做是字符组成的有序序列,但从类型来说就不是
时间复杂度
0(2)
n表示数据规模
o(n) 该时间复杂度和规模有关,n越人,消耗时间越大
文本文件本质上就是长长的字符串
本质都是二进制的,从二进制角度看,存的都是某种编码的码点对应的数字。但是人喜欢字符,展示给人看得时候,应用正确的编码表来解密这些码点,找到码点对应的字符显示到屏幕,打印到纸张
len对于字竹串返回的是占用的字节数
虽然可以看做是字符组成的有序序列,但从类型来说就不是
时间复杂度
0(2)
n表示数据规模
0(1) 1表示常量,是个固定的常数,表示与规模n无关,总是使用固定的计算步骤,对于计算机计算来讲毛毛雨了,顺序表索引定位
这是我们写程序追求极致目标
o(n) 该时间复杂度和规模有关,n越人,消耗时间越人 y=kx
o(n^2) 该时间复杂度和规模有关,n越大,消耗时间越大,y=k(x^2)
0(n^3) 该时间复杂度和规模有关,n越大,消耗时间越大,y=k(x^3) ,比上面的消耗更大,灾难
0(1) 1表示常量,是个固定的常数,表示与规模n无关,总是使用固定的计算步骤,对于计算机计算来讲毛,这是我们写程序追求极致目标
o(n) 该时间复杂度和规模有关,n越人,消耗时间越人 y=kx有的时候这种只与规模相关的也是我们得追求
o(n^2) 该时间复杂度和规模有关,n越大,消耗时间越大,y=k(z^2)2层循环,如果每一层循环都与n相关
九九乘法表,2层循环,时间复杂度是多少 ?
for i l~n n
for j 1~n <=i i增加j也增加 j随着规模而增加 n
o(n * n)
一般排序sort都是O(n^2),好一点是o(n * logn) 。排序算法很耗时,能不排序就不要排序
o(n^3) 该时间复杂度和规模有关,n越大,消耗时间越大,y=k(x^3) ,比上面的消耗更大,灾难3层循环,如果每一层循环都与n相关

哈希表、函数
哈希表、哈希算法
map原理介绍及使用
map常用操作、sort排序
Go函数调用原理、形参和实参
哈希表
map是go中的实现
存储kv对,一个kv对称为一个元素,键值对entry、item
len表示元素的个数,即 kv对的个数
key 不能重复,无序
key是关键的,还有唯一的意思
相同key会 去重
无序的意思
举例 x、y 如果用序列(线性表) 表达,我认为x是y的前驱,y是x的后继
在hash table中,x、y如果认为是key,不认为有前后依存关系,认为是不一样的独立的不同的key,当然在物理存储上,也是在空间中相对位置不确定
不是线性表,是无序的,就不能编号,也就说不能索引
引用必型
有一个标头值
有一个指针指向底层的hash表
不支持零值可用
高效的,依赖与key,用空间换时间
hash算法设计还要兼顾 高效
hash不可逆,不能从结果反推输入值
单向散列算法 不可逆
用在KEY的计算上
冲突解决方案
设计好的hash算法,来减少碰撞
x值一个微小的变化 (bit) 都会引起y值巨大的变化,尽量分散
x不同取值得到的y值在y空间分布均匀
真正的物理实现:开地址法、拉链法等
算法
md ? md5
输出128大整数,按照hex的宁符串输出的,字符串长度32
密码加密,彩虹表
文件看做一个人的二进制的字节序列,是不是就是输入x,也会求得一个y值
大小不一样一定不是同一个文件
相同大小,字字节序列扔给md5算出一个hash值,如果hash一样则文件相同
上传文件比较、下载文件比较
重复文件查找器
比较大小
hash
大字节序列对比
数据库中一些很大的字段
SHA
ba7816bf8f01cfea414140de5dae2223b00361a396177a9cb410ff61f20015ad
map
header
指针 指向 底层的hash表
构造
零值不可用,用var a map[int]int 零值是ni1但是后面无法增加kv对
字面量定义map[string]int{k1:v1} ,花括号表示字面量
make(map[string]int) // 没有告诉未来容纳多少元素,先开牌较小空间,如果未来kv对较多,可能频繁扩容
make(map[string]int,100) //表示为100个元素自动生成足够 (内部按照算法生成)的空间 
map
header
指针 指向 底层的hash表

 字面量定义map[string]int{k1:v1} 花括号表示字面量
字面量定义map[string]int{k1:v1} 花括号表示字面量
make (map[string]int) // 没有告诉未来容纳多少元素,先开较小空间,如果未来kv对较多,可能频繁扩容
make(map[string]int,100) //表示为100个元素自动生成足够(内部按照算法生成) 的空间make(map[string]int,100) // 告诉未来容纳多少元素,先开合适的空间来存储这些kv对,注意一般空间大小别元素个数大一些
var mo map[string]int 这不是赋值语句,go语言零值可用,但是这是引用类型,所以是nil
赋值
key存在覆盖; key不存在新建kv对存储
var m = map[int]string {1:"abc"]
var s = []int{1000, 2000}
m[1] s[1]虽然不一样,但是都是该类型最高效的定位方式
排序
元素如何大小? 元素必须同类型
如果是自定义类型,go没法知道同类型元素如何比较大小,需要你提供
int、string是内建类型,go在sort库里集成了对他们的增强,StringSlice、IntSlice为他们提供了比较和交互的方法
作用域、递归函数;匿名函数、defer
函数作用域
递归函数
闭包、defer、结构体
函数
函数function功能,有一定的语法,封装多条语句,实现一定功能的语句块
封装,黑匣子,给输入返回输出。故意不需要让使用者都成为专家,了解实现原理
复用,可以调用n回
append




闭包
内层函数用到了外层函数某一层函数的局部变量,就形成了闭包
类型和实例
int、string、bool、结构体都是类型
1是int的一个实例,它是int类型
""是string的一个实例,它是string类型
[3]int是类型,[3]int{}字面量表达一个数组,它是[3]int类型的实例,它的类型是[3]int
结构体的方法、属性,称为成员。方法也称为成员方法,属性也称为成员属性
结构体和数组一样,是值类型
结构体指针
先创建实例,取地址
用new,定义出该结构体的零值实例并返回该实例的指针 new(Point) 
结构体构造函数
构造 实例
Go没有构造函数,使用者约定俗成提供一个返回 该类型的实例或指针的 普通函数
名字建议NewXXX或newXXX
结构体的成员可能有太多的属性了,对于属性特别多的结构体实例化很繁琐,提供一个只需要几个参数就可以实例化返回一个实例的函数很方便
接口
抽象,只有方法的声明,没有具体的实现
接口中是0个或者多个方法(函数)声明《签名 )
谁实现了接口,就要把当前这个接口中所有未实现方法 一个不能少 全部实现,才称为实现了该接口,也就是说,你是该接口类型
实现,你要把方法(函数)的函数体写出来
函数体,怎么写,想怎么写怎么写
约束(规范),方法《动作、行为、操作、函数) 的约束
class xxx implements i1,Java写法,也要实现这些未实现的接口方法
tom这个人,属于人类(生物学),也属于可驾驶类(操作技能)
1、什么叫接口
一系列方法的集合组成的类型
2 、什么叫实现了该接口
该接口的所有方法一个不落全部要实现,就说实现了该接口
我受该接口约束,我只能乖乖的 实现其所有方法
3、实例到底是什么类型
实例属于某类型,如果该类型正好也实现了某接口,也说该实例是该接口类型的
4、可以实现多少个接口?
不限
接口是行为规范的集合
能力的集合
能驾驶?
能吃吗 ?
实现什么接口,就具备了该接口的能力


空接口变量可以接受所有类型的实例类型
断言(接口)
对接口类型变量的类型进行断言
断言
成功
失败
b.(类型) 断言失败panic,成功返回值
t, ok := b.(int)
如果失败,ok为false,t不值得使用
如果成功,ok为true,t值得信任,可以使用

异常处理
面向对象


面向对象
封装
继承
override 覆盖
多态
前提: 继承、覆盖
借用接口语法实现
实现同一种类型的实例(父类的实例),其实都是子类的实例,调用统一的方法,这些方法在子类中被覆盖了,所以调用统一的方法,表示出不同的态
var a Animal = Cat{}
a.run() #
c是Cat类型,Cat中run做了覆盖,调用的是Cat中的run。如果cat没有覆盖run,调用Animal中定义的run
重载overload
func add(x, y int) int {} // add(4,5)
func add(x,y string) string {} // add("4","5")
func add(x,y,z []int} []int {}
排序
掌握接口的运用
Go语言数据结构
文件的本质
序列
任何文件都是二进制的字节序列
习惯上有文本文件,把二进制的字节序列看做是某种字符编码的宇符组成的序列
序列化***
序列化: 不管你是什么类型的实例,我都要把你变成字节序列
反序列化:把 字节序列 能够还原成 原来类型的 实例
硬盘存储(持久存储设备),序列化存储,一个个字节顺序存储,持久化网络传输,buffer线性的序列,序列化,按照字节成批发送
不管从磁盘还是网络获得
序列化的数据,还原(反序列化)的时候,都得在一个新的程序的进程中再造其对应类型的数据
内存中数据是属于某种类型的,某种类型在内存中元素未必连续
序列化方案,称为协议
针对内部实现的类型切片、整数、宁符串、map、结构体等,语言提供了序列化方案
不同的序列化方案,包括第三方协议,转换方式不一样,对序列化后得到序列大小不一

 Go json包
Go json包
所有语言的json包序列化的结果都是 字符串,所有语言的json库反序列化用的都是 字符串
时间
Now
UTC
时区时间宁符串 -> Time parse
Time -> 时间字符串stringformat
时间计算
t1 - t2 => 增量delta
t1+增量 -> new time
导出的全局变量、加入当前名词空间
. "github.com/calc/minus/"
全局的导出的标识符就不是给你用的,只运行init函数的
- "github.com/mysql/sqldriver"
日志
日志记录器
帮我们输出到输出设备上(stdout、stderr、文件)
我们最关心是message
格式
log
std不对外
Default()
os.Stderr 默认用标准错误输出,默认用控制台
Print*/Fatal*/Panic* std
日志记录必须使用Logger
New返回一个全新的Logger
log.New(out io.Writer, prefix string, flag int)
io.Writer er说明是接口
out应该有自己的类型,同时其类型又实现了Writer的方法,out也可以看作是Writer类型的实例
out都可以调用Writer
写什么?写入设备,out管写入到设备
prefix
flag 确定logger工作方式
color
red 1
black 2
blue 3
黑红 4
color
red 1
black 2
blue 4
黑红 red | black
zerolog
日志记录器
Logger 全局, -1 // Logger类型
.With() 返回上下文,携带 新增的字段
Context
.Logger() 返回日志记录器
创建
New, 构造一个全新的Logger, TraceLevel -1
log.Logger.With().Bool("success", true).Logger() 觉得全局的不满意,增强返回了logger
log.Level(zerolog.InfoLevel) 返回全局的子logger, InfoLevel
级别:
通过级别来筛选消息,我们在代码中随便输出消息,配置输出门槛,拦截部分级别的消息
消息级别、logger的级别
gLevel 全局log级别,全局级别,控制所有logger
级别设定
在logx上产生的消息的消息级别 >= max(日志记录器级别logx级别,glevel) 才可输出
消息级别、Logger
Logger.Debug()
level debug
l1.Debug().Msg() 消息级别是0,l1级别是1 <
l1.Info().Msg() 消息级别是1,l1级别是1 = 通过
l1.Warn() 消息级别2 > 通过
数据库编程
mysql server端 管理进程mysqld,OS帮你启动,成立进程
client端 mysql os帮你启动后,操作系统中,就成了进程了
都要发送消息,对方都要解析信息,规则,协议,Mysql协议
由mysql官方或者第三方提供对协议支持的库,同时是为了方便把网络连接(连接池)封装到里面,提供一个库,称为驱动库。针对不同的语言,提供不同的库
Client 《-》Server
网络 序列化 、反序列化
操作描述(规矩)发给s端,s端解析,可以理解去操作,操作后的结果由s封装,发给c端
c端收到了,反序列化,拿到数据,解析数据
Mysql
多个库
每个库是独立的
每个库有多个表
每张表里面存储数据,一行行
数据库操作
insert into table (id, name) values(3, wu)
候选键
一个字段或多个字段组合能唯一确定一行
倾向于 选择单一字段 候选键 选为 主键
主键
来自于候选键
约束:不能为null,且唯一
唯一键
字段可以为null, 一旦不是null必须唯一不能重复
主键、唯一键、索引
B+树,多叉 有序 排序 平衡树
利用主键、唯一键、索引都可以加速查找定位,where条件中使用主键是最快的
空间换时间
SQL
加索引
索引,要建立索引数据结构的,占磁盘空间
B+范围搜索
hash 不能范围,但是O(1)精确定位
数据库编程
通信
客户端 某个进程
服务端Server 某个进程
序列化、反序列化
物理网络、底层协议
TCP
连接
TCP协议
双向通信
库
类、结构体、接口、方法
提供建立TCOP连接,池
连接池(Pool) 看做游泳池
有范围,资源有限,控制你无线使用本机资源,泳道
懒汉式
有人来,先等着,放好水之后,开始使用泳道
再来人
有没有空闲泳道,优先利用
没有空闲的呢?开辟新泳道,要看还有没有资源。等着
饥饿汉式 勤快
提前放水,开辟好所有泳道
有人来,有空闲就直接下水,占用空闲泳道,无空闲就等着
提前放水,预留、开辟部分泳道,应付使用。
复用
提到响应速度?
扩建泳池
Mysql协议
封装不同种类的消息
解析不同种类的消息
标准库不会提供,往往有数据库方或第三方提供
多数数据库操作是近似的,那么Go定义了所有的操作(接口)
https://github.com/go-sql-driver/mysql 支持database/sql,推荐
GORM
客户端使用面向对象的方式 转换 SQL语句,该语句发给服务端
服务器端得到一个结果,发送给客户端,客户端使用ORM来把一条条记录塞入一个个(某个结构体)实例中
ORM管不管和数据库通信,不管通信,也就是网络通信和数据库协议不管
1、驱动,打开
2、操作
表谁? 结构体 和表建立映射关系
结构体命名采用驼峰,表名默认建议使用蛇形命名法
手动建立映射 配置
实现Tabler接口
TableName() string
自动(有约定)
表名:结构体的名称遇到非首字母的大写变小写前加_,结尾加s
字段是谁?
约定
手动配置
主键 `gorm:"primaryKey"`
指定字段名
un `gorm:"column:user_name"`
结构体 标识符和属性标识符 一定要大写,否则后果自负
写入数据库都是用UTC,读出来也是按照UTC读,调用Local()
插入
构建实例,或者实例的切片,调用db.Create(xxx) -> insert into
MongoDB
dbPath 缺省数据路径,放数据库数据的\data\db
库对等关系型的库
集合对等关系型的表
字段对应关系型字段,类型不一样
库、集合、字段都可以事先不定义,集合中每一条 文档的字段都可以不一样(字段名不一样,字段类型不一定)
希望各位每个集合只放该业务数据,可以后期扩展字段
文档Document(bson格式)对等关系型的记录
编程
驱动库:底层网络通信协议,应用层协议
filter 过滤器,条件(where)
bson
D
M
Go语言并发编程
数据安全与加解密算法.
1.对称加密

DES数组分级
DES子密钥生成
DES加密过程
S盒替换
分组模式
AES
2.非对称加密

RSA
对称加密和非对称加密结合使用
RSA加密过程
椭圆曲线加密
3.哈希算法
哈希函数的基本特征
SHA1
MD5
哈希函数的应用

数字签名
密码学api

数据结构与算法
1.链表
单向链表
package main
import "fmt"
// 链表中的一个元素
type Node struct {
Info int
Next *Node
}
// 链表
type List struct {
Head *Node
Len int
}
func (list *List) Add(ele int) {
node := &Node{Info: ele, Next: nil}
if list.Len == 0 {
list.Head = node
} else {
head := list.Head
for i := 1; i < list.Len; i++ {
head = head.Next
}
head.Next = node
}
list.Len += 1
}
func (list *List) Travers() {
if list.Len == 0 {
return
}
head := list.Head
fmt.Println(head.Info)
for i := 1; i < list.Len; i++ {
head = head.Next
fmt.Println(head.Info)
}
}
func main() {
list := List{}
list.Add(1)
list.Add(8)
list.Add(4)
list.Add(3)
list.Add(5)
list.Travers()
}
func (list *List) Add(ele int) {
node := &Node{Info: ele, Next: nil}
if list.Len == 0 {
list.Head = node
list.Tail = node
} else {
list.Tail.Next = node
list.Tail = node
}
list.Len += 1
}
链表的应用:LRU缓存淘汰
·LRU(Least Recently Used)最近最少使用思路:缓存的kev放到链表中,头部的元素表示最近刚使用如果命中缓存,从链表中找到对应的key,移到链表头部
如果没命中缓存:
如果缓存容量没超,放入缓存,并把key放到链表头部.
如果超出缓存容量,删除链表尾部元素,再把key放到链表头部
LRU和超时缓存
循环链表

环
RING添加元素

RING的应用:基于滑动窗口的统计
最近100次接口调用的平均耗时、最近10笔订单的平均值最近30个交易日股票的最高点
ring的容量即为滑动窗口的大小,把待观察变量按时间顺序不停地写入ring即可
2.栈
先进后出
3.堆
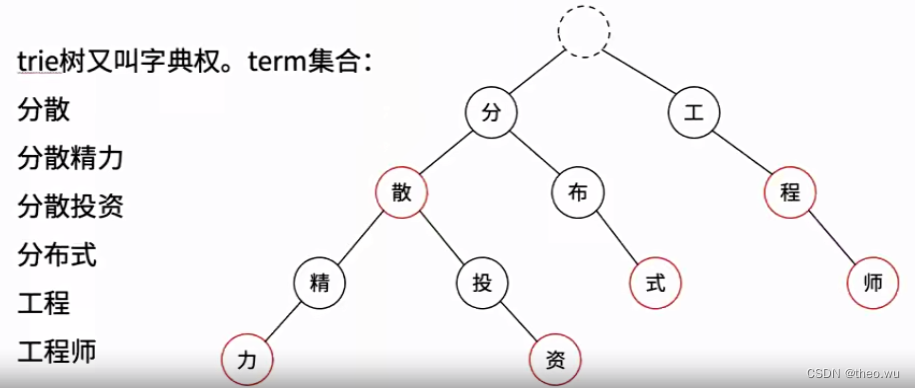
4.Trie树
根节点是总入口,不存储字符
对于英文,第个节点有26个子节点,子节点可以存到数组里;中文由于汉字很多,用数组存子节点太浪费内存,可以用map存子节点从根节点到叶节点的完整路径是一个term从根节点到某个中间节点也可能是一个term,即一个term可能是另一个term的前缀

斐波那契数列
递归造成计算浪费
用栈解除递归
斐波那契数列非递归实现
堆的应用
堆的底层表示
堆是一棵二叉树。大根堆:任意节点的值都大于等于其子节点。反之为小根堆。用数组来表示堆,下标为i的结点的父结点下标为(i-1)/2,其左右子结点分别为(2i+ 1)、(2i+ 2)。

构建堆
每当有元素调整下来时,要对以它为父节点的三角形区域进行调整
删除堆顶
向下调整
用堆实现超时缓存
把超时的元素从缓存中删除
1.按key的到期时间把key插入小根堆中
2周期扫描堆顶元素,如果它的到期时间早于当前时刻,则从堆和缓存中删除,然后向下调整堆
 求集合中最大的K个元素
求集合中最大的K个元素
1.用集合的前K个元素构建小根堆
2.逐一遍历集合的其他元素,如果比堆顶小直接丢弃;否则替换掉堆顶,然后向下调整堆
把超时的元素从缓存中删除
1.按key的到期时间把key插入小根堆中
2.周期扫描堆顶元素,如果它的到期时间早于当前时刻,则从堆和缓存中删除,然后向下调整堆
堆的实现
 Trie树
Trie树
根节点是总入口,不存储字符
对于英文,第个节点有26个子节点,子节点可以存到数组里;中文由于汉字很多,用数组存子节点太浪费内存,可以用map存子节点从根节点到叶节点的完整路径是一个term从根节点到某个中间节点也可能是一个term,即一个term可能是另一个term的前缀
 1.实现数字签名
1.实现数字签名
2.用map和链表实现LRU缓存
3.用map和堆表实现超时缓存
并发编程
go并发模型
并发合并文件
channel
并发安全性
多路复用
web开发
http标准库
实现router
http协议
go http编程
router
验证器和中间件
Gin
Socket编程
网络通信原理
聊天室的实现
tcp编程
tcp面向字节流和udp
TLS和websocket
websocket 编程方式
Go操作数据库
mysql基础
mysql实践
go操作mysql
sql-builder
自己实现sql
gorm
go操作mongo
文件中转站
简易版工具开发
以系统方式开发
项目工程
demo简化版
demo后端开发
demo IOC版
demo后端开发
RPC入门
rpc入门
protobuf编解码
proto3语法入门
grpc入门
框架支持grpc
cmdb api
云资源provider
云凭证管理
云资源同步api
用户中心
用户中心
登录认证
权限判定
审计中心
消息队列kafka
审计中心
web入门
javascript基础
web基础html
web基础css
web基础浏览器
vue入门
vue基础
vue路由与状态管理
项目前端框架
登陆页面
项目404页面
项目导航页面
项目前端
主机列表页面
cmdb主机页面
cmdb搜索页面
cmdb同步页面
总线和缓存
web和prometheus二次开发
prometheus概念
exporter开发
kubernetes二次开发
Kubernetes 简介与client-go使用
基于client-go 的多集群管理平台
Kubernetes Operator 开发
kubernetes二次开发
API Server开发
API Server pipeline开发
pipeline调度器开发
informer和服务注册
订阅SCM事件
调度器controller开发
step调度器开发和node开发
api server订阅scm事件
项目工程框架搭建
后端API开发
web基础之-Javascript
项目设计
项目骨架搭建
项目V1简化版
项目骨架开发与业务模块开发
业务模块接口设计
业务模块数据库模型设计
业务模块的业务实现
业务模块的Restful接口设计
工程化
后端API开发
RESTFul API开发和工程化
web基础之-Javascript
JavaScript基础
Web入门基础-HTML和CSS
Vue入门
Vue组件
Vue路由
项目前端
前端+RPC入门
Protobuf编解码
















 92
92











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









