







本系列文章总共有七篇,目录索引如下:
AdaBoost 人脸检测介绍(1) : AdaBoost身世之谜
AdaBoost 人脸检测介绍(2) : 矩形特征和积分图
AdaBoost 人脸检测介绍(3) : AdaBoost算法流程
AdaBoost 人脸检测介绍(4) : AdaBoost算法举例
AdaBoost 人脸检测介绍(5) : AdaBoost算法的误差界限
AdaBoost 人脸检测介绍(6) : 使用OpenCV自带的 AdaBoost程序训练并检测目标
AdaBoost 人脸检测介绍(7) : Haar特征CvHaarClassifierCascade等结构分析
3. AdaBoost算法流程
Adaboost是一种迭代方法,其核心思想是针对不同的训练集训练同一个弱分类器,然后把在不同训练集上得到的弱分类器集合起来,构成一个最终的强分类器。
3.1 弱分类器的训练及选取
最初的弱分类器可能只是一个最基本的Haar-like特征,计算输入图像的Haar-like特征值,和最初的弱分类器的特征值比较,以此来判断输入图像是不是人脸,然而这个弱分类器太简陋了,可能并不比随机判断的效果好,对弱分类器的孵化就是训练弱分类器成为最优弱分类器,注意这里的最优不是指强分类器,只是一个误差相对稍低的弱分类器,训练弱分类器实际上是为分类器进行设置的过程。至于如何设置分类器,设置什么,我们首先分别看下弱分类器的数学结构。
其中
f
为特征,
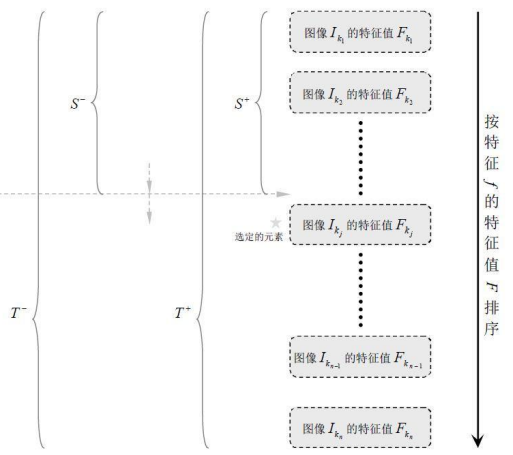
弱分类器训练的过程大致分为如下几步:
1)对每个特征
f
,计算所有训练样本的特征值;
2)将特征值排序;
3)对排好序的每个元素计算:
3.1)全部正例的权重和
3.2)全部负例的权重和
T−
;
3.3)该元素前正例的权重和
S+
;
3.4)该元素前负例的权重和
S−
.
4)选取当前元素的特征值
F(kj)
和它前面的一个特征值
Fkj−1
之间的数作为阈值,所得到的弱分类器就在当前元素处把样本分开 —— 也就是说这个阈值对应的弱分类器将当前元素前的所有元素分为人脸(或非人脸),而把当前元素后(含)的所有元素分为非人脸(或人脸)。该阈值的分类误差为:
于是,通过把这个排序表从头到尾扫描一遍就可以为弱分类器选择使分类误差最小的阈值(最优阈值),也就是选取了一个最佳弱分类器。
3.2 训练强分类器
给定一个训练数据集 T=(x1,y1),(x2,y2),⋯,(xN,yN) ,其中实例空间 x∈X ,而实例空间 X∈Rn, yi∈Y=−1,+1 。AdaBoost算法的目的就是从训练数据中学习一系列弱分类器,然后将这些弱分类器组合成一个强分类器。AdaBoost算法流程如下:
步骤1:首先,初始化训练数据的权值分布。每个训练样本初始都被赋予相同的权值:1/N。
步骤2:进行多轮迭代,用
m=1,2,⋯,M
表示迭代的第多少轮。
a). 使用具有权值分布
Dm
的训练数据集学习,得到基本分类器(选取让误差率最低的阈值来设计基本分类器):
b). 计算
Gm(x)
在训练数据集上的分类误差率:
由上述式子可知,
Gm(x)
在训练数据集上的误差率
em
就是被
Gm(x)
误分类样本的权值之和。
c). 计算
Gm(x)
的系数,
αm
表示
Gm(x)
在最终分类器中的重要程度(目的:得到基本分类器在最终分类器中所占的权重):
由上述式子可知,
em≤1/2
时,
αm≥0
,且
αm
随着
em
的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大。
d). 更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代:
使得被基本分类器 Gm(x) 误分类样本的权值增大,而被正确分类样本的权值减小。就这样,通过这样的方式,AdaBoost方法能“重点关注”或“聚焦于”那些较难分的样本上。其中, Zm 是规范化因子,使得 Dm+1 成为一个概率分布:
步骤3:组合各个弱分类器
从而得到最终的分类器,如下:
简单来说,AdaBoost有很多优点:
● AdaBoost是一种有很高精度的分类器;
● 可以使用各种方法构建子分类器,AdaBoost算法提供的是框架;
● 当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单;
● 简单,不用做特征筛选;
● 不用担心overfitting!
3.3 再次介绍弱分类器以及为什么可以使用Haar特征进行分类
对于本算法中的矩形特征来说,弱分类器的特征值 f(x) 就是矩形特征的特征值。由于在训练的时候,选择的训练样本集的尺寸等于检测子窗口的尺寸,检测子窗口的尺寸决定了矩形特征的数量,所以训练样本集中的每个样本的特征相同且数量相同,而且一个特征对一个样本有一个固定的特征值。
对于理想的像素值随机分布的图像来说,同一个矩形特征对不同图像的特征值的平均值应该趋于一个定值k。这个情况,也应该发生在非人脸样本上,但是由于非人脸样本不一定是像素随机的图像,因此上述判断会有一个较大的偏差。
对每一个特征,计算其对所有的一类样本(人脸或者非人脸)的特征值的平均值,最后得到所有特征对所有一类样本的平均值分布。
下图显示了20×20 子窗口里面的全部78,460 个矩形特征对全部2,706个人脸样本和4,381 个非人脸样本的特征值平均数的分布图。由分布看出,特征的绝大部分的特征值平均值都是分布在0 前后的范围内。出乎意料的是,人脸样本与非人脸样本的分布曲线差别并不大,不过注意到特征值大于或者小于某个值后,分布曲线出现了一致性差别,这说明了绝大部分特征对于识别人脸和非人脸的能力是很微小的,但是存在一些特征及相应的阈值,可以有效地区分人脸样本与非人脸样本。
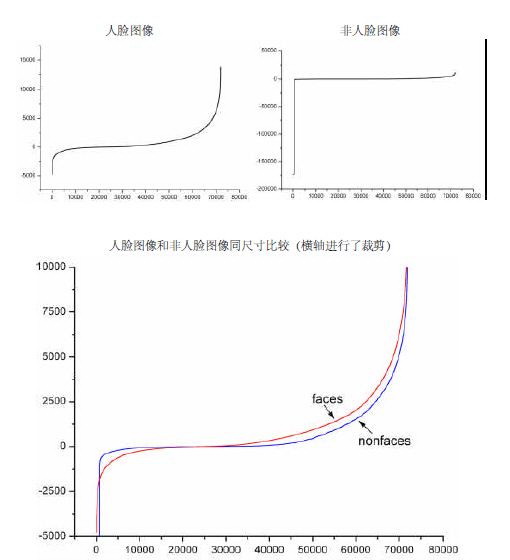
所有矩形特征对所有图片的特征值平均数分布
(横坐标是按特征值平均值排序后的特征编号)
为了更好地说明问题,我们从78,460 个矩形特征中随机抽取了两个特征A和B,这两个特征遍历了2,706 个人脸样本和4,381 个非人脸样本,计算了每张图像对应的特征值,最后将特征值进行了从小到大的排序,并按照这个新的顺序表绘制了分布图如下所示:
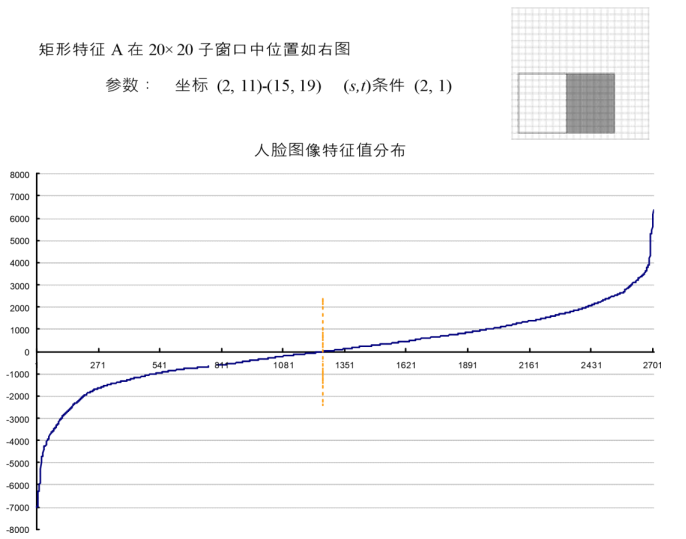
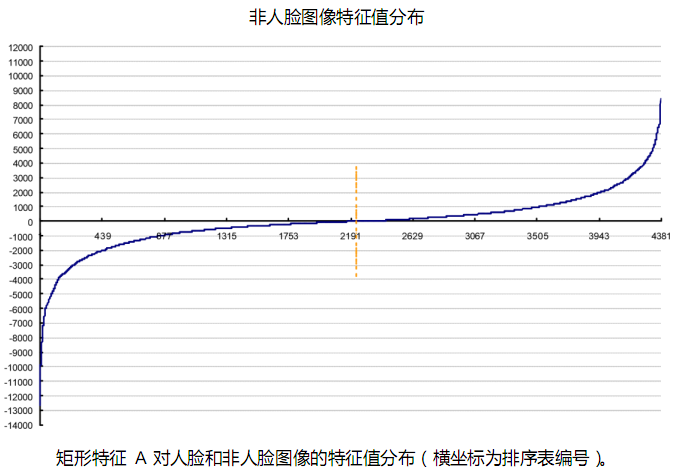
可以看出,矩形特征A在人脸样本和非人脸样本中的特征值的分布很相似,所以区分人脸和非人脸的能力很差。下面看矩形特征B在人脸样本和非人脸样本中特征值的分布:
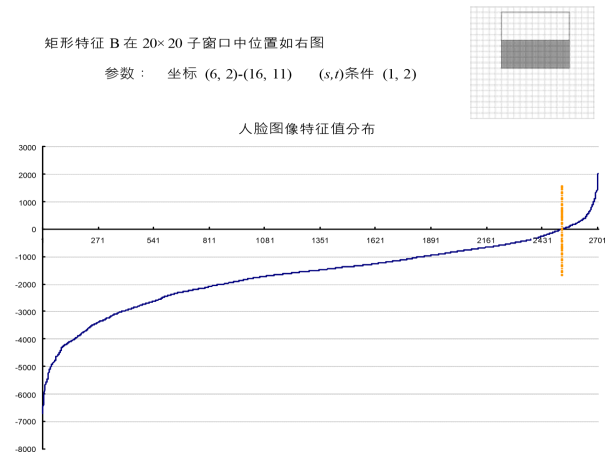
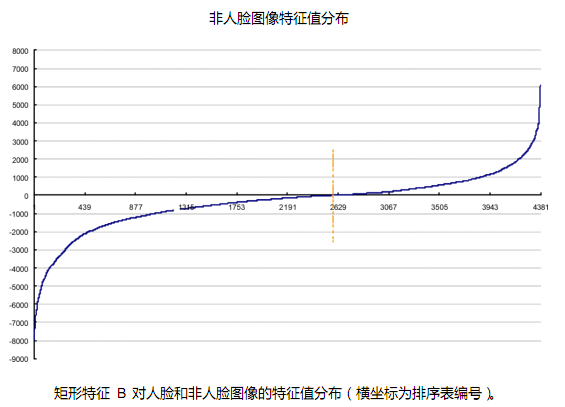
可以看出,矩形特征B的特征值分布,尤其是0点的位置,在人脸样本和非人脸样本中差别比较大,所以可以更好的实现对人脸分类。
有关特征A和B的一些统计数据如下表:

特征 A 和特征 B 的表现大相径庭。
特征 A 对人脸和非人脸样本的特征值为0的点几乎处于相同位置(46.5%,51.5%),且都在所有特征的中间范围 (-5%)。这说明矩形特征 A对于人脸和非人脸几乎没有分辨能力。
特征 B 对非人脸样本的分布,符合我们的预想,特征值为 0的点处于所有特征的中间范围(59.4%),这说明特征 B也“ 看不到” 非人脸的特点。但是对于人脸样本,特征 B 表现了很一致的倾向性,93.4%的特征在 0 点的一侧,与非人脸样本的相差 34%。这说明特征 B 能够相当可靠地分辨人脸和非人脸。
上述的分析说明,确实存在优势的矩形特征,能够在一定的置信范围内区分人脸和非人脸。由于是使用统计的方法计算人脸图像和非人脸图像的差别,因此最后得到的区分阈值,也只能是在某个概率范围内准确地进行区分。
由上述的分析,阈值 θ 的含义就清晰可见了。而方向指示符 p <script type="math/tex" id="MathJax-Element-46">p</script> 用以改变不等号的方向。一个弱学习器(一个特征)的要求仅仅是:它能够以稍低于50%的错误率来区分人脸和非人脸图像,因此上面提到只能在某个概率范围内准确地进行区分就已经完全足够。按照这个要求,可以把所有错误率低于50% 的矩形特征都找到(适当地选择阈值,对于固定的训练集,几乎所有的矩形特征都可以满足上述要求)。每轮训练,将选取当轮中的最佳弱分类器(在算法中,迭代T 次即是选择T 个最佳弱分类器),最后将每轮得到的最佳弱分类器按照一定方法提升(Boosting)为强分类器。
[同步本人网易博客的文章] AdaBoost 人脸检测介绍(3) : AdaBoost算法流程















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









