







 论文提出了一种新的Transformer模型——TG-Transformer,它利用异质性文本图和采样方法处理大规模语料库,有效地进行文本分类。通过对比实验,TG-Transformer在多个数据集上优于CNN、LSTM和fastText等传统模型。
论文提出了一种新的Transformer模型——TG-Transformer,它利用异质性文本图和采样方法处理大规模语料库,有效地进行文本分类。通过对比实验,TG-Transformer在多个数据集上优于CNN、LSTM和fastText等传统模型。
©原创作者 | 苏菲
论文来源:
https://aclanthology.org/2020.emnlp-main.668/
论文题目:
Text Graph Transformer for Document Classification (文本图Tranformer在文本分类中的应用)
论文作者:
Haopeng Zhang Jiawei Zhang
01 引言
文本分类是自然语言处理中的基本任务之一,而图神经网络(GNN)技术可以描述词语、文本以及语料库,最近研究者将GNN应用到抓取语料库中单词全局共现关系中。但此前的图神经网络引用存在不能扩展到大型语料库、且忽略文本图异质性的缺陷。
在此背景下,本文作者引入了一个基于异质性图神经网络的新Transformer方法(文本图Transformer,或者TG-Transformer)。
深度学习模型如卷积神经网络(CNN)、循环神经网络(RNN)已经被用于文本特征的学习中,取代了一些传统的特征生成(如n元语法特征、词袋特征)。
最近,一些学者又把图神经网络(GNN)用于文本分类的研究中,但论文作者指出了其中的一些缺陷,并提出使用文本图Transformer,一个异质性的图神经网络用于文本分类问题。而且这是一种可扩展的基于图的方法。
02 方法论
作者首先用图表示一个已知语料库的异质性文本图,然后引入文本图的采样方法(Sampling)从文本图中生成小批量子图。这些小批量子图可以送入TG-Transformer中,用于学习文本分类的有效节点特征,总体框架如图1所示。
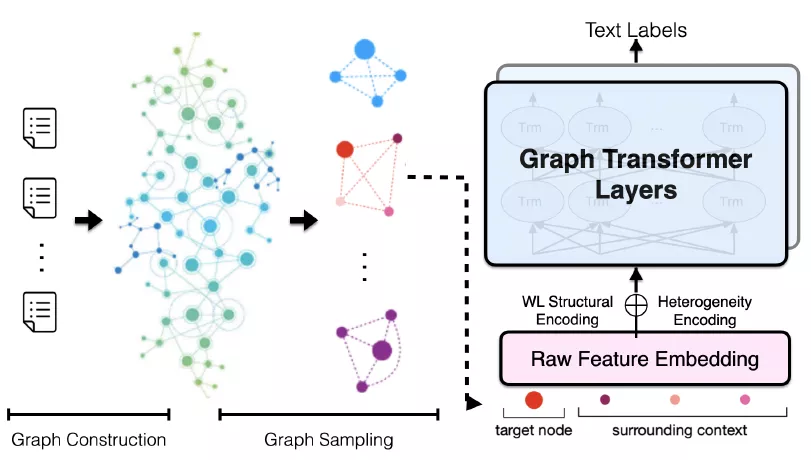
图1 TG-Tranformer的总体框架
(1)建立文本图(Text Graph)
为了获得语料库中词语的全局共现,论文作者建立了一个异质性文本图G(异质图比同质图更贴近于现实世界),G =(U; V; E;F)。 所谓异质性就是图中不只包含一种类型的节点或边(nodes or edges)。
在G中建立了两种类型的节点,一种是文本节点(U),代表语料库中的所有文档;另一种是词语节点(V),代表语料库词汇表中的所有词语。一种是词语节点(U),代表语料库词汇表中的所有词语;另一种是文档节点(V),代表语料库中的所有文档。
文本图中也包含了两种类型的边:一种是词语-文档边,用大写E来表示;另一种是词语-词语边,用大写字母F来表示。词语-文档边的权重由TF-IDF方法来计算得到。而词语-词语边的权重通过计算点间互信息(point-wise mutual information)得到,该互信息基于在语料库中滑动窗口的局部词语共现来获得。点间互信息的计算公式如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











