







阅读文献“Learning Transferable Visual Models From Natural Language Supervision”(CLIP)
Abstract
SOTA视觉系统被有标签的数据集训练。这种有监督的训练限制了模型的普遍性和实用性。有一种方法是,从文本中学习关于图片的信息,这种方法利用了一个更加广泛的监督源。我们证明了,通过一种简单的预训练任务,预测的是从网上获取的四亿的数据(image,text)能够更好地学习image特征。
在预训练之后,自然语言被使用去推理学到的视觉概念,这能在下游任务中够实现zero-shot的转化。这个模型在不使用特殊数据集进行训练的情况下,能够和那些经过有监督训练的模型达到差不多的效果。
Intorduction and Motivating Work
NLP领域中已经能够使得未知任务结构实现zero-shot到下游任务中。像GPT-3,相比于那些专门用于特定任务的模型,GPT-3的性能非常具有竞争力,并且只需要很少的或者不需要特定的训练数据。
预训练模型能否直接从网络文本中学习并在计算机视觉领域产生一个相似的突破性进展?
近几年的做zero-shot的视觉模型,以及预训练语言模型的视觉应用(例如ConVIRT)的性能都不及SOTA计算机视觉模型,例如Big Transfer和ResNeXt。但是他们也有不同,首先是数据集规模不同。
本论文弥补了这些差距,并且使用了ConVIRT的简单版本进行训练,该模型称之为CLIP(Contrastive Language-Image Pre-training),借鉴了自然语言监督,是一种有效的和扩展的方法。
CLIP在训练前学习执行一系列广泛的任务,包括OCR、地理定位、动作识别,并在计算效率更高的同时优于最佳的公开可用的ImageNet模型。zero-shot的CLIP模型比相等精度的有监督ImageNet模型更稳健。
Approach:
整个实现图:
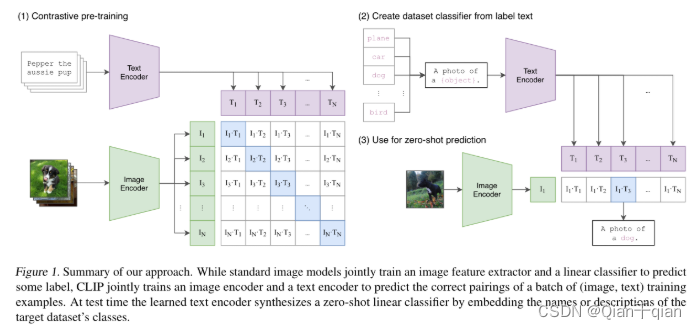
我们的核心是通过与图像配对的自然语言中包含的监督来学习感知。
数据集:数据组成是文本和图像组成的对。一个图片对应一句文本。
CLIP步骤:
- 分别将图像和文本输入对应的编码器得到对应的特征,那么一个batch(N个数据对),就会有N个图像特征和N个文本特征,那么就会有N × \times ×N个特征对,这里面有N个正确的特征对,有N × \times ×N-N个错误的特征对,这样就可以用对比学习的方式进行训练。使用两个编码器对图像和文本进行特征提取,在获得编码特征后,将编码特征线性投影到multi-modal embedding space的过程,这里面包含了所有需要学习的参数(伪代码中的W_i和W_t)。
- 使用过程。假如说想进行分类任务,以ImageNet为例。将其中的一千个类别的名称再加上几个词语组成一句话。然后使用刚刚的文本编码器和图像编码器分别提取这句话的特征和图像的特征,然后进行相似度计算,这样就能成功进行分类。
Creating a Suffciently Large Dataset
已经有的数据集主要有三个:MS-COCO、Visual Genome、YFCC100M。前两个有着较高的品质,但是很小,因此舍去。第三个数据集大小能接受,但是他的文件名有些随意,将比较随意的文件名过滤掉,只剩下那些有着自然语言的文件名,最终的大小也只和ImageNet数据集的差不多(太小了)。
使用自然语言监督的主要原因是因为可以在网上获取到大量的这种形式的数据。最终构建了一个400M大小的数据集(image,text)。为了尽可能地覆盖所有的视觉概念,通过搜索(图像,文本)对,作为构建过程的一部分,文本包含一组50万个查询中的一个(意思应该是文本有50万个种类)。我们通过在每次查询中包含两万对(img,text)来对结果进行分类平衡。结果数据集的总字数与用于训练的GPT-2的WebText数据集类似。将此数据集成为WebImageText,简写为WIT。
Selecting an Efficient Pre-Training Method
最初的方法是使用图像CNN和文本Transformer来对图像进行预测文本。对于一张图片的文本描述可能有很多,因此这种方法非常耗时,如果将预测转化成一个词包的形式,则会提高很多。再者,如果将预测内容变为图片和文本是否配对,并使用对比学习的方法,则在效率上又会提高一个档次。
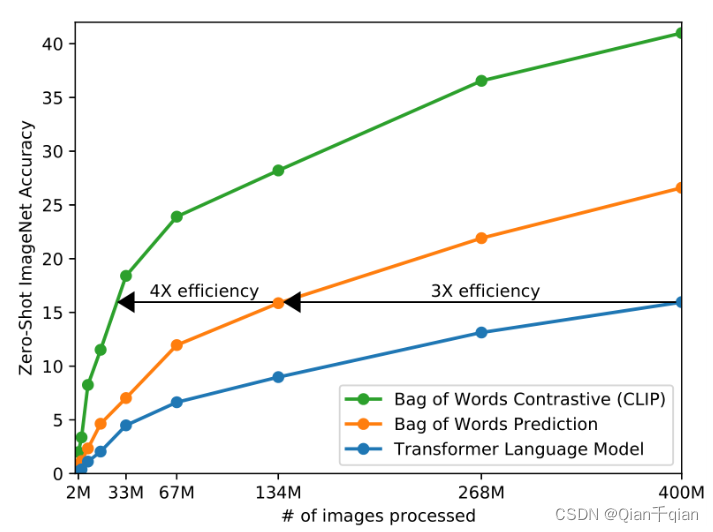
对比学习表明了对比目标能够胜过等价的预测目标。因此只预测哪个文本作为一个整体与哪个图像配对,而不是该文本的确切单词。
给一个batch的(image,text)的数据(假设是N个),CLIP被训练去预测这N × \times ×N个配对的可能性。为了做这个,CLIP学习了一个多模型嵌入空间,通过训练一个图像编码器和文本编码器去最大化这N个正确的配对的余弦相似度,最小化那 N 2 − N N^2-N N2−N个不正确的余弦相似度。优化了一个对称的交叉熵损失函数在这些相似度得分上。
伪代码:

这个模型是Zhang模型的简化版,移除了representation和contrastive embedding层之间的非线性层,使用一个线性层代替。移除了文本转化函数 t u t_u tu,他是将文本映射到一个标准化的句子,然而本文的文本数据基本上都是一个句子。简化了图像转化函数 t v t_v tv。
Choosing and Scaling a Model
视觉方面的encoder,既可以选择vi-Transformer,也可以选择ResNet,文本方面就选择Transformer。
Training
混精度训练
最终效果最好的模型,是使用vit-Transformer训练出来的。
Experiments
为什么做Zero-shot?之前的半监督、无监督的方法,大都是上游任务先去学习一个比较好的特征,然后下游任务使用带标签的数据做微调,这就无法避免数据不好收集的问题。如果能做一个模型以后不再进行微调,那不是很好吗。
Prompt Engineering And Ensembling
文本的引导作用
词语的多义性:如果只用一个标签,进行特征提取,由于多义性的存在,很有可能会计算一个错误的相似度。
在做推理的时候,如果只用标签进行特征提取,那么很容易产生distributing gap。因此做一个模板放在这里:“A photo of a {label}”,然后变成一个句子,再对句子进行特征提取。这句话的上下文就可以作为一个对推理的提示。比如,整个数据集是一个动物类别的数据集,我就可以加一句话:“A photo of a {label}, a type of anaminal”,由于文本编码器是text Transformer,可以提取一整句话的信息,这样后面的a type of anaminal就有了一个提示作用。
假如说用多个模板进行匹配,那么就可以顾及到更多的情况。
Results
CLIP在特别难的分类任务上效果不好,比如纹理分类、肿瘤分类,物体个数。这种情况下,如果一点标签也不给确实有点强人所难。在这种比较难的分类任务中,可以使用few-shot。作者是将图片的编码器冻住,然后做线性分类。














 1610
1610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









