







 超级会员免费看
超级会员免费看
 CLIP模型利用大规模的图文配对数据,通过自然语言监督信号训练,实现强大的零样本迁移能力。无需预先定义类别,模型在多个数据集上表现出优秀的泛化性能,尤其在物体识别上,与有监督的ResNet50效果相当。然而,对于抽象任务和特定领域任务,CLIP的性能有待提升。
CLIP模型利用大规模的图文配对数据,通过自然语言监督信号训练,实现强大的零样本迁移能力。无需预先定义类别,模型在多个数据集上表现出优秀的泛化性能,尤其在物体识别上,与有监督的ResNet50效果相当。然而,对于抽象任务和特定领域任务,CLIP的性能有待提升。
Paper:Learning Transferable Visual Models From Natural Language Supervision
Code:https://github.com/OpenAI/CLIP
引言:利用自然语言的监督信号去训练一个迁移效果很好的视觉模型,文字+图片多模态。
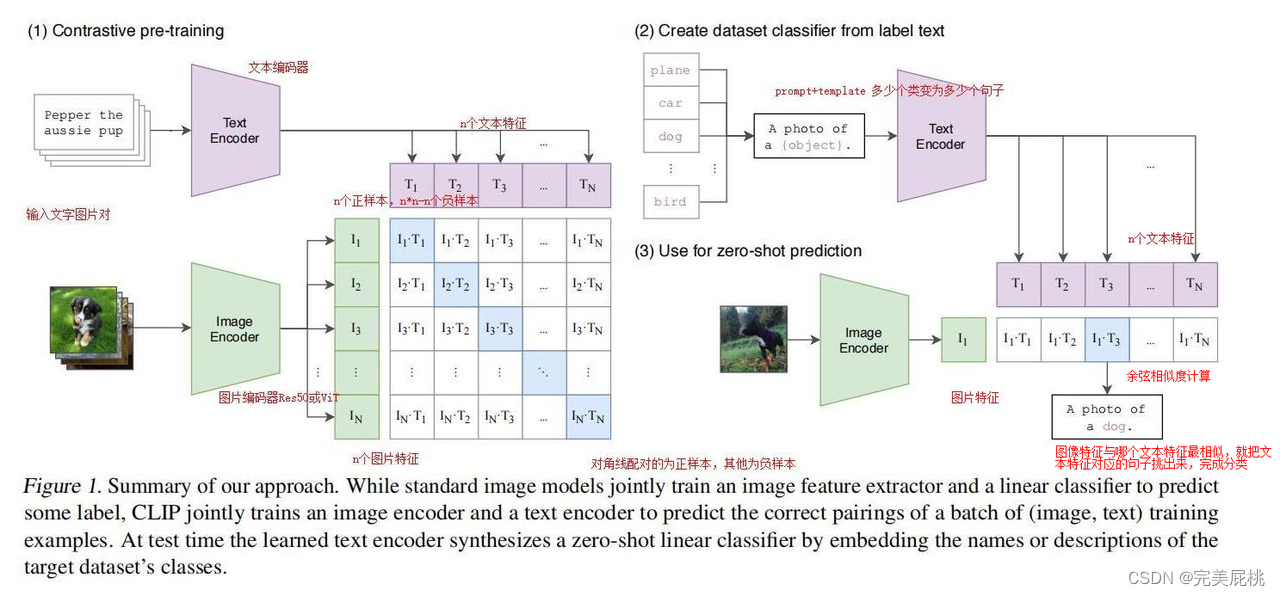
-
其中,标签可以更改,不仅限于imageNet中的一千个类,可以换为任意的单词,图片也可以为任意的图片。
-
彻底摆脱了分类标签这个性质,不论训练还是推理都不需要有提前定义好的类别。
-
不仅能识别新的物体,而是真的把视觉和文字的语义联系到了一起,学到的特征语义性极强,迁移效果也很好。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1948
1948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









