








 超级会员免费看
超级会员免费看

深入解析:多模态大语言模型中的多层视觉特征融合——原理、实践与最佳方案
论文:Multi-Layer Visual Feature Fusion in Multimodal LLMs: Methods, Analysis, and Best Practices
一、问题本质:为什么需要多层视觉特征?
当前多模态大语言模型(MLLMs)存在两大核心痛点:
- 视觉层选择随意性:现有方法(如MiniCPM、LLaVA)常仅用最后一层特征,但浅层(纹理)和深层(语义)特征各有价值
- 融合策略缺乏系统研究:特征该插入LLM输入层还是中间层?是否需要额外融合模块?
下图揭示不同视觉层特征的显著差异:
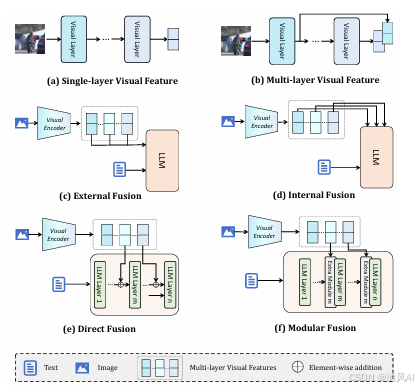
Figure 1. Different Visual Features and Fusion Paradigms. (a) and (b) illustrate the acquisition methods for single-l

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











