







kl散度意义:
-
In the context of machine learning,
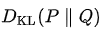
is often called the information gain achieved if Q is used instead of P. -
This reflects the asymmetry in Bayesian inference, which starts from a prior Q and updates to the posterior P.
-
公式:

证明:https://stats.stackexchange.com/questions/7440/kl-divergence-between-two-univariate-gaussians















 4880
4880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









