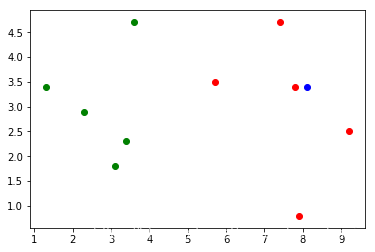
<matplotlib.collections.PathCollection at 0x20ba3c947b8>
1. kNN实现过程
欧拉距离
D
i
s
t
=
∑
i
=
1
n
(
X
i
(
a
)
−
X
i
(
b
)
)
2
Dist = \sqrt{\sum_{i=1}^n(X_i^{(a)} - X_i^{(b)})^2}
Dist=i=1∑n(Xi(a)−Xi(b))2
from math import sqrt
distances =[]for x_train in X_train:# 计算欧拉距离
d = sqrt(np.sum((x_train - x)**2))
distances.append(d)# 也可以如下写法# distances = [sqrt(np.sum((x_train - x) ** 2)) for x_train in X_train]
import numpy as np
from math import sqrt
from collections import Counter
from metrics import accuracy_score
classKNNClassifier:def__init__(self, k):assert k >=1,"k must be valid"
self.k = k
self._X_train =None
self._y_train =Nonedeffit(self, X_train, y_train):"""根据训练数据集X_train和y_train训练kNN分类器"""assert X_train.shape[0]== y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k."
self._X_train = X_train
self._y_train = y_train
return self
defpredict(self, X_predict):assert self._X_train isnotNoneand self._y_train isnotNone, \
"must fit before predict!"assert X_predict.shape[1]== self._X_train.shape[1], \
"the feature number of X_predict must be equal to X_train"
y_predict =[self._predict(x_predict)for x_predict in X_predict]return np.array(y_predict)def_predict(self, x_predict):"""给定单个待预测数据x,返回x的预测结果值"""assert x_predict.shape[0]== self._X_train.shape[1], \
"the feature number of x must be equal to X_train"
dist =[ sqrt(sum((x_train - x_predict)**2))for x_train in self._X_train]
nearest = np.argsort(dist)
top_K =[ self._y_train[i]for i in nearest[:self.k]]
votes = Counter(top_K)return votes.most_common(1)[0][0]defscore(self, X_test, y_test):
y_predict = self.predict(X_test)return accuracy_score(y_test, y_predict)def__repr__(self):return"KNN(k=%d)"% self.k
metrics.py
import numpy as np
defaccuracy_score(y_true, y_predict):"""计算 y_true 和 y_predict 之间的准确率"""assert y_true.shape[0]== y_predict.shape[0], \
"the size of y_true must be equal to the size of y_predict"returnsum(y_true == y_predict)/len(y_true)






















 77
77











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









