






前言
近年来,视觉基础模型 (VFM) 在众多下游任务中取得了巨大成功,例如图像分类、目标检测和图像生成等。然而,现有的 VFM 通常专注于特定领域,例如 CLIP 擅长零样本视觉语言理解,DINOv2 擅长语义分割,SAM 擅长开放词汇实例分割,并且计算成本高昂。为了解决这些问题,英伟达的研究人员开发了 AM-RADIO (Agglomerative Model – Reduce All Domains Into One),这是一个高效的 VFM,它通过多教师蒸馏技术将多个预训练的 VFM(如 CLIP、DINOv2 和 SAM)的知识融合到一个统一的模型中,在一个模型中聚合了多个 VFM 的独特特性,实现了“集多家之所长”。
-
Huggingface模型下载:https://huggingface.co/nvidia/RADIO
-
AI快站模型免费加速下载:https://aifasthub.com/models/nvidia

技术特点
多教师蒸馏
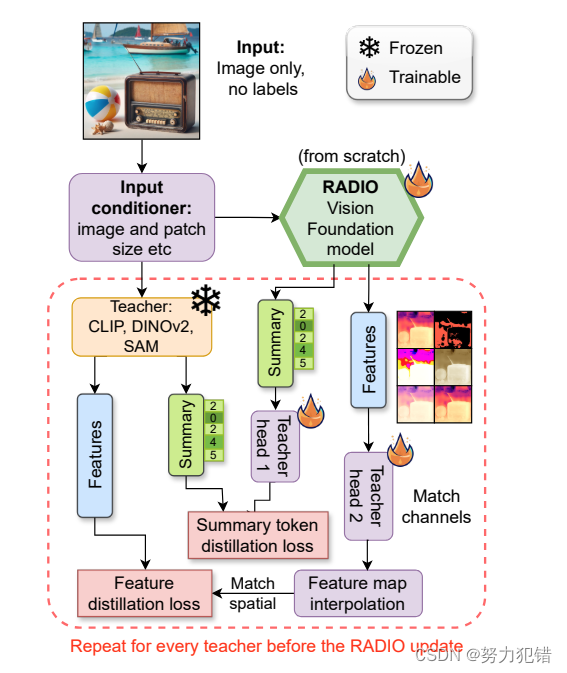
AM-RADIO 的核心技术是多教师蒸馏。简单来说,该技术将多个“教师”模型的知识转移到一个“学生”模型中,使学生模型能够学习到多个教师模型的优势。在 AM-RADIO 中,研究人员选择了 CLIP、DINOv2 和 SAM 作为教师模型,因为它们在各自的领域表现出色:
-
CLIP: 擅长零样本视觉语言理解,在 LAION-400M 等大型数据集上进行训练,能够将图像和文本映射到同一特征空间,实现跨模态理解。
-
DINOv2: 在需要精细空间特征的密集任务(如语义分割)上表现出色。它使用自监督学习方法,通过最大化同一图像的不同视图之间的特征一致性来学习图像特征。
-
SAM: 拥有出色的开放词汇实例分割能力。它可以根据用户提供的提示(如点、框或文本)分割图像中的任何对象。
AM-RADIO 的多教师蒸馏框架包括以下步骤:
-
输入图像: 将图像输入到所有教师模型和学生模型中。
-
特征提取: 每个教师模型都提取图像的特征,包括汇总特征向量和空间特征向量。
-
适配器头: 学生模型使用适配器头将自身的特征映射到每个教师模型的特征空间。
-
特征匹配: 使用余弦相似度和 smooth L1 损失函数来最小化学生模型和每个教师模型之间的特征差异。
通过多教师蒸馏,AM-RADIO 成功地将这些教师模型的独特属性融合到一个统一的模型中,使其能够在多个任务上表现出色。
高效模型架构 E-RADIO
为了进一步提高模型效率,AM-RADIO 还提出了一种新的混合架构 E-RADIO,该架构结合了 CNN 和 Transformer 的优势,在保证模型性能的同时,显著提高了推理速度。E-RADIO 的主要特点包括:
-
多尺度输入: 为了匹配不同教师模型的输入分辨率,E-RADIO 采用了多尺度输入策略,例如使用 432x432 分辨率匹配 CLIP 和 DINOv2,使用 1024x1024 分辨率匹配 SAM。
-
多尺度特征: E-RADIO 利用 CNN 的优势,在模型的早期阶段快速降低特征图分辨率,并在后期阶段使用 Transformer 进行全局信息整合。
-
多分辨率注意力: E-RADIO 采用了多分辨率注意力机制,允许模型在不同分辨率下进行特征交互,从而更好地捕捉图像的细节信息。

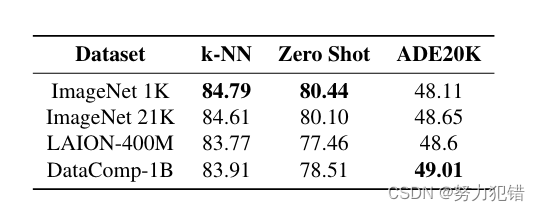
训练数据集
AM-RADIO 使用 DataComp-1B 数据集进行训练,这是一个包含 10 亿张图像的大规模数据集,涵盖了各种主题和场景。与 ImageNet 等更小、更单一的数据集相比,DataComp-1B 能够提供更丰富的图像信息,帮助 AM-RADIO 学习更通用的视觉特征。
性能表现
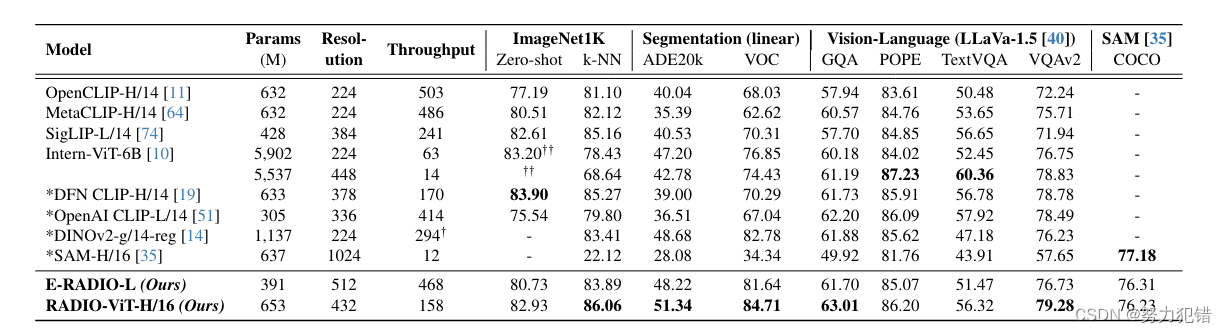
AM-RADIO 在多个基准测试中展现出优异的性能,全面超越了其教师模型:
-
ImageNet 分类: 在 ImageNet-1K 数据集上,AM-RADIO 的 k-NN Top-1 准确率达到 86.06%,零样本准确率达到 82.93%,均优于所有教师模型。
-
语义分割: 在 ADE20K 和 Pascal VOC 数据集上,AM-RADIO 的线性探针语义分割 mIoU 分别为 51.34% 和 84.71%,显著高于其他模型,表明其在密集预测任务上的强大能力。
-
大型视觉语言模型: 将 AM-RADIO 作为视觉编码器集成到 LLaVA-1.5 中,在 GQA、TextVQA、POPE 和 VQAv2 等任务上取得了最佳成绩,证明了其在视觉语言理解方面的优势。
-
SAM-COCO 实例分割: AM-RADIO 能够替代 SAM 的视觉编码器,在 COCO 实例分割任务上取得了 76.23% 的 mIoU,与 SAM 的性能相当,说明 AM-RADIO 成功地学习了 SAM 的开放词汇实例分割能力。
-
推理速度: 相比于教师模型,AM-RADIO 的推理速度提升高达 6 倍,这得益于其高效的模型架构 E-RADIO。
应用场景
AM-RADIO 凭借其强大的性能和高效的推理速度,在各种应用场景中具有巨大潜力:
-
图像理解: AM-RADIO 能够用于图像分类、目标检测、语义分割等任务,帮助人们更好地理解图像内容。
-
视觉问答: AM-RADIO 可以作为视觉编码器集成到大型视觉语言模型中,用于回答与图像相关的问题。
-
机器人视觉: AM-RADIO 可以为机器人提供强大的视觉感知能力,使其能够更好地理解周围环境。
-
内容创作: AM-RADIO 可以用于生成高质量的图像描述,辅助内容创作者进行创作。
总结
AM-RADIO 是一种高效且强大的视觉基础模型,通过多教师蒸馏技术融合了多个预训练模型的优势,并在多个基准测试中取得了最佳成绩。其高效的模型架构 E-RADIO 使其能够以更快的速度进行推理,使其在各种应用场景中都具有巨大的潜力。相信 AM-RADIO 将推动视觉基础模型的发展,为人工智能应用带来更多可能性。
模型下载
Huggingface模型下载
https://huggingface.co/nvidia/RADIO
AI快站模型免费加速下载
https://aifasthub.com/models/nvidia















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









