






前言
大型语言模型(LLM)近年来取得了巨大进展,但要将其与人类价值观和意图相一致,使其变得有用、诚实和无害,仍然是一个挑战。强化学习从人类反馈中(RLHF)是一种常用的方法,通过微调语言模型来实现有效对齐。传统的RLHF方法虽然取得了令人印象深刻的结果,但其多阶段过程(包括训练奖励模型和优化策略模型以最大化奖励)带来了优化挑战。
-
Huggingface模型下载:https://huggingface.co/princeton-nlp/Llama-3-Instruct-8B-SimPO
-
AI快站模型免费加速下载:https://aifasthub.com/models/princeton-nlp
技术特点
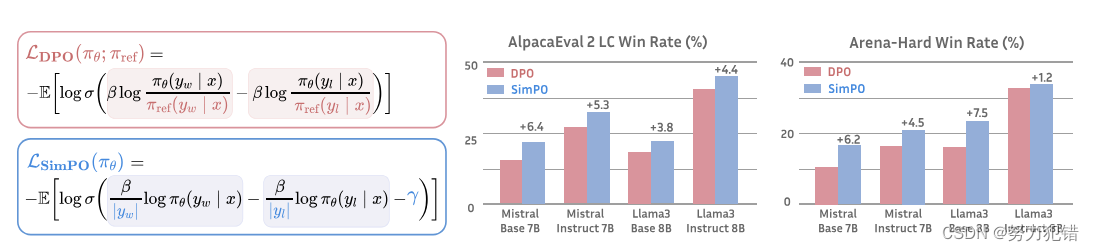
为了解决这些挑战,研究人员开始探索更简单的离线算法。直接偏好优化(DPO)是其中的一种方法。DPO重新参数化RLHF中的奖励函数,直接从偏好数据中学习策略模型,无需显式奖励模型。它因其简单性和稳定性而被广泛应用于实际中。
DPO 使用当前策略模型和监督微调(SFT)模型之间的响应可能性对数比作为隐式奖励。然而,这种奖励公式与指导生成的度量标准(近似于策略模型生成响应的平均对数可能性)不完全一致。这种训练和推断之间的差异可能会导致次优性能。
SimPO 针对 DPO 的局限性,提出了一种更简单但更有效的离线偏好优化算法。SimPO 的核心是将偏好优化目标中的奖励函数与生成度量标准保持一致。SimPO 包含两个主要组成部分:
-
长度归一化奖励: 使用策略模型计算响应中所有标记的平均对数概率。
-
目标奖励边际: 确保获胜响应的奖励比失败响应的奖励至少高出此边际。
SimPO 具有以下优点:
-
简单性: SimPO 不需要参考模型,比 DPO 和其他依赖参考模型的方法更轻量级且更容易实现。
-
显著的性能优势: 尽管简单,SimPO 显著优于 DPO 及其最新变体(例如,最近的无参考目标 ORPO)。这种性能优势在各种训练设置和广泛的指令遵循基准测试中都保持一致,包括 AlpacaEval 2 和具有挑战性的 Arena-Hard 基准测试。
-
最小长度利用: 与 SFT 或 DPO 模型相比,SimPO 不会显著增加响应长度,表明它几乎没有利用长度偏差。
性能表现
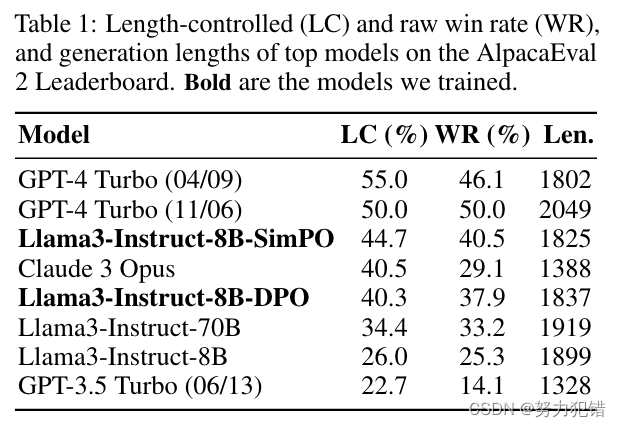
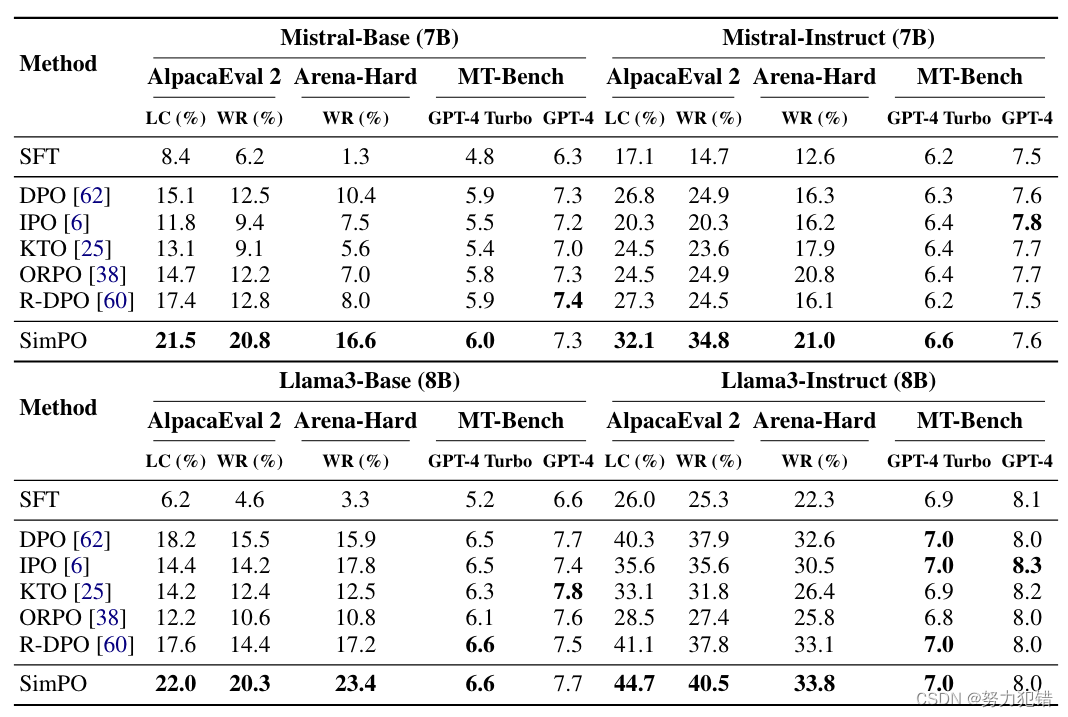
SimPO 在 AlpacaEval 2 和 Arena-Hard 基准测试上都表现出优异的性能。在 AlpacaEval 2 上,SimPO 比 DPO 的胜率高出高达 6.4 个百分点。在 Arena-Hard 上,SimPO 比 DPO 的胜率高出高达 7.5 个百分点。SimPO 基于 Llama3-8B-Instruct 构建的模型在 AlpacaEval 2 上实现了 44.7 的长度控制胜率,超过了排行榜上的 Claude 3 Opus,并在 Arena-Hard 上实现了 33.8 的胜率,成为目前最强大的 8B 开源模型。
应用场景
SimPO 可以用于各种需要从人类反馈中学习的应用场景,例如:
-
聊天机器人: 提高聊天机器人的响应质量,使其更符合人类期望。
-
文本生成: 生成更符合人类意图和价值观的文本。
-
代码生成: 生成更安全、更可靠的代码。
总结
SimPO 是一种简单而有效的偏好优化算法,它通过将奖励函数与生成可能性对齐,并引入目标奖励边际,消除了对参考模型的依赖,并在不利用长度偏差的情况下实现了强大的性能。SimPO 证明了其在各种训练设置和基准测试中的有效性,并表明其有潜力成为下一代 LLM 对齐算法的基础。SimPO 的成功为进一步提升 LLM 的性能和安全性提供了新的思路和方向。
模型下载
Huggingface模型下载
https://huggingface.co/princeton-nlp/Llama-3-Instruct-8B-SimPO
AI快站模型免费加速下载
https://aifasthub.com/models/princeton-nlp















 5381
5381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









