






你是否曾想过,只需几张自己的照片,就能在数字世界中拥有一个与你别无二致、还能摆出各种姿势、穿梭于不同场景的高清“分身”?过去,这可能需要复杂的 3D 建模或大量的数据微调。但现在,来自字节跳动 (ByteDance) 的研究团队为我们带来了颠覆性的开源模型——InfiniteYou!
正如其名,InfiniteYou 旨在释放无限的个性化创意。仅需 1 到 4 张参考图像,它就能精准捕捉你的核心身份特征,生成细节丰富、风格多样、姿态可控的高保真个性化图像。这对于内容创作、虚拟形象定制、个性化营销等领域无疑是一大利好。更重要的是,它已经开源!让我们一起揭开 InfiniteYou 的神秘面纱。
AI快站下载
模型仓库:ByteDance/InfiniteYou · Hugging Face

什么是 InfiniteYou?“我”的无限可能
InfiniteYou 是一款先进的个性化图像生成 (Personalized Image Generation) 模型,专注于高保真度的人物身份保持 (High-Fidelity Identity Preservation)。
简单来说,它的核心任务是:给定极少量(1-4 张)包含目标人物的人脸参考图像,以及一个描述期望场景、姿态或风格的文本提示 (Text Prompt),生成一张全新的图像。这张新图像需要同时满足两个条件:
- 1. 身份高度一致: 生成的人物必须看起来就是参考图像中的那个人,保留其独特的面部特征和细节。
- 2. 内容灵活可控: 生成图像的姿态、表情、服装、背景、艺术风格等需要遵循文本提示或 ControlNet 等控制信号的要求。
InfiniteYou 的主要优势在于:
- 极高身份保真度: 精准还原人物细节。
- 数据门槛极低: 仅需 1-4 张参考图。
- 生成多样性强: 轻松驾驭不同姿态、风格和场景。
- 无需微调: 训练一次,即可用于任意新身份,推理速度快。
- 兼容控制工具: 可与 ControlNet 等结合,实现精细控制。
- 完全开源: 社区共享,自由使用。
深入核心:InfiniteYou 如何“记住你”并“创造你”?
InfiniteYou 的出色表现,源于其在强大的预训练文本到图像扩散模型 (Text-to-Image Diffusion Model)(如 Stable Diffusion)基础上进行的巧妙设计:
- 1. 专门的身份编码器 (Identity Encoder):
- 不同于仅依赖文本编码器来间接表达身份,InfiniteYou 引入了一个独立的身份编码器。
- 这个编码器的作用是专门从输入的 1-4 张参考图像中,提取出与人物身份最相关的细粒度特征。它专注于捕捉那些定义“你是谁”的关键视觉元素,例如脸型、五官比例、皮肤纹理等,并将这些信息编码成特定的身份嵌入 (Identity Embedding)。
- 2. 创新的全局-局部融合注意力 (Global-Local Fusion Attention):
- 这是 InfiniteYou 的核心创新所在。如何将提取出的“身份信息”有效地融入到图像生成过程中,同时又不干扰文本提示或 ControlNet 对姿态、风格等的控制?这就是融合注意力机制要解决的问题。
- 传统的交叉注意力 (Cross-Attention) 主要负责将文本提示信息注入扩散模型的 U-Net 结构中。InfiniteYou 对此进行了扩展。
- 它设计的融合注意力机制,能够智能地、动态地将身份编码器提取的全局身份特征,与来自文本提示的语义信息、以及来自 ControlNet 的局部结构/姿态信号进行融合。
- 这种融合不是简单的叠加,而是根据生成过程的需要,自适应地平衡身份信息与其他控制信号的权重。既要确保“画的是你”,也要确保“画的是你想要的姿势和场景”。
- 3. 免调优设计 (Tuning-Free):
- 与 DreamBooth、LoRA 等需要为每个新身份重新训练或微调模型部分参数的方法不同,InfiniteYou 的身份编码器和融合注意力机制是在初始训练后就固定的。
- 当需要生成新人物的图像时,只需将新人物的 1-4 张参考图输入身份编码器,获取其身份嵌入,然后直接用于推理生成即可。
- 优势: 大大简化了使用流程,节省了针对每个人的训练时间和计算资源,实现了真正的“即插即用”个性化生成。
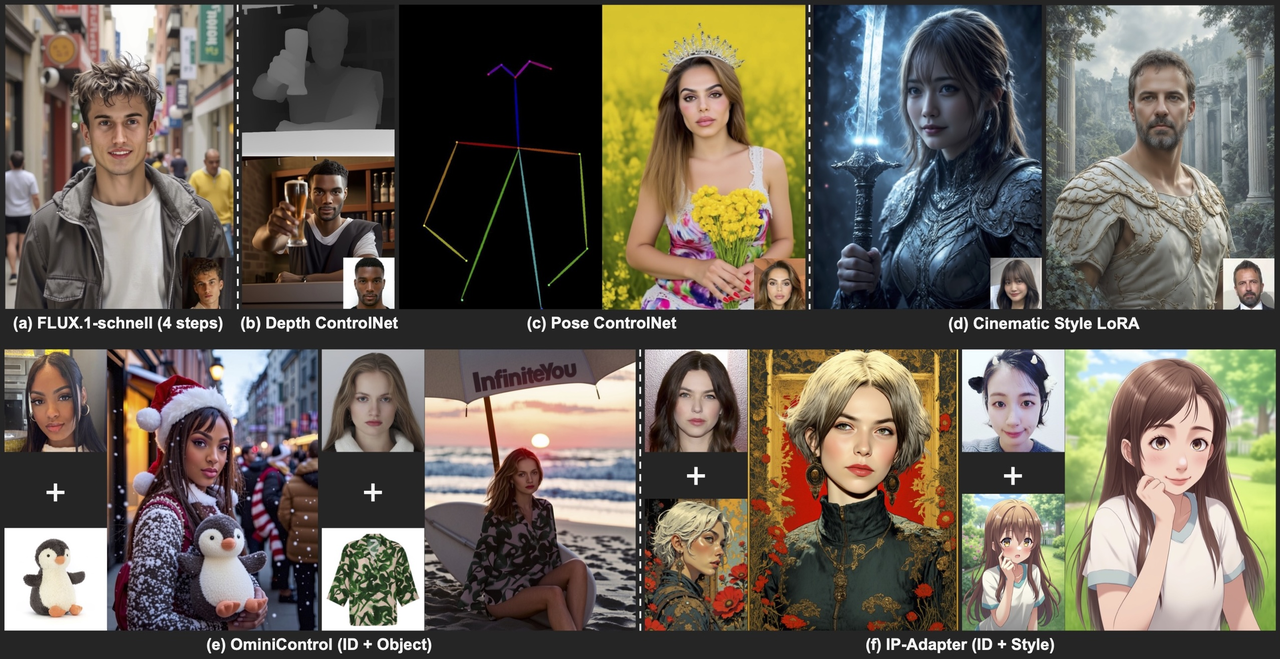
核心功能亮点解析
- 1. 惊人的高保真身份保持
这是 InfiniteYou 最受赞誉的一点。无论是细微的面部特征,还是整体的神态气质,InfiniteYou 都能精准捕捉并稳定复现,生成的图像与参考人物高度相似,达到了以假乱真的高清“数字分身”效果。
- 2. 极低的输入门槛 (1-4 张图)
仅需提供 1 到 4 张包含清晰人脸的参考照片,无需成百上千张数据,即可开启个性化生成之旅。这使得普通用户也能轻松使用。
- 3. 强大的多样性与可控性
- 姿态/风格/场景自由切换: 只需修改文本提示,就能让你的“数字分身”摆出各种姿势(跑、跳、坐、思考)、变换多种艺术风格(油画、动漫、赛博朋克)、出现在不同场景(沙滩、城市、森林)。
- 兼容 ControlNet: 可以结合 ControlNet 使用姿态骨架图、深度图、边缘图等作为额外控制信号,对生成图像的姿态、构图进行像素级的精准控制。
- 4. 免调优,推理高效
无需为每个人单独训练模型,大大加快了个性化内容的生产速度,降低了技术门槛和成本。
性能表现如何?实力超群
InfiniteYou 不仅在视觉效果上令人印象深刻,其性能也经过了验证:
- 定性评估: 在官方发布的大量视觉对比案例中,InfiniteYou 相较于其他流行的免调优个性化生成方法(如 IP-Adapter、PhotoMaker、InstantID 等),在身份保持的逼真度、细节一致性以及生成图像的多样性方面,通常展现出更优越或更均衡的表现。
- 定量评估: (通常在相关研究论文中有详细数据)InfiniteYou 在多个行业标准指标上表现出色:
- 高身份相似度: 在 CLIP-I Score, DINO Score, Face Similarity (基于 ArcFace 等人脸识别模型) 等衡量生成图像与参考图像身份相似度的指标上得分很高。
- 良好的文本对齐度: 同时,在 CLIP-T Score 等衡量生成图像与文本提示匹配程度的指标上保持良好水平,证明其在保持身份的同时没有牺牲对文本指令的遵循。

应用场景与未来展望
InfiniteYou 的出现,为个性化视觉内容的生成开辟了广阔天地:
- 个性化头像与虚拟形象: 为社交媒体、游戏、元宇宙创建独一无二的数字替身。
- 虚拟试穿/试妆: 让用户看到自己穿戴不同服饰、尝试不同妆容的效果。
- 创意广告与营销: 生成符合品牌调性、主角是目标用户的个性化广告素材。
- 影视与内容创作: 快速生成演员在不同场景、穿着不同服装的概念图或辅助素材。
- 教育与娱乐: 创建个性化的故事书角色或互动游戏人物。
结语
InfiniteYou 以其仅需 1-4 张图的极低门槛、惊人的高保真身份保持能力、强大的生成多样性与可控性,以及免调优、快速推理的便捷性,真正将高清“数字分身”的创建带到了我们指尖。字节跳动的开源贡献,让这一前沿技术得以惠及更广泛的开发者和创意社区。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









