







离散强化学习 d4rl环境安装
我是在算力云上进行的安装,具体操作参考
都是小徐的血泪史啊啊啊

首先是算力云的使用,在本机安装的同学可以直接跳过这一步(●’◡’●)
1.选一个GPU,随机选,选便宜的(bushi)

2.选择镜像
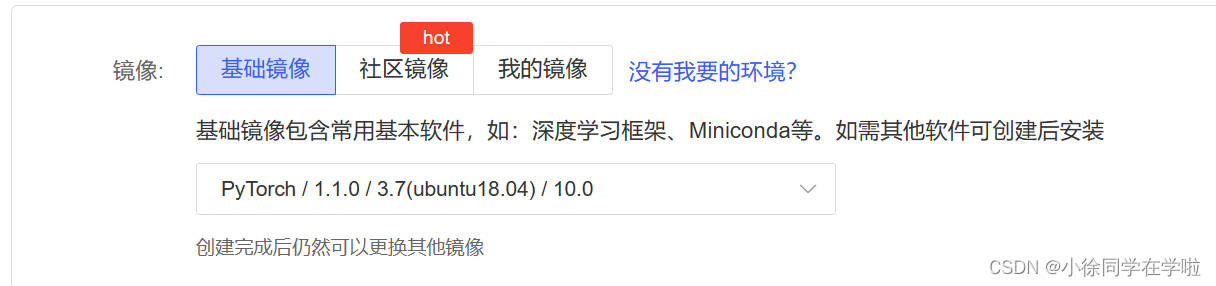
3.点击右下角立即创建后,开机等待
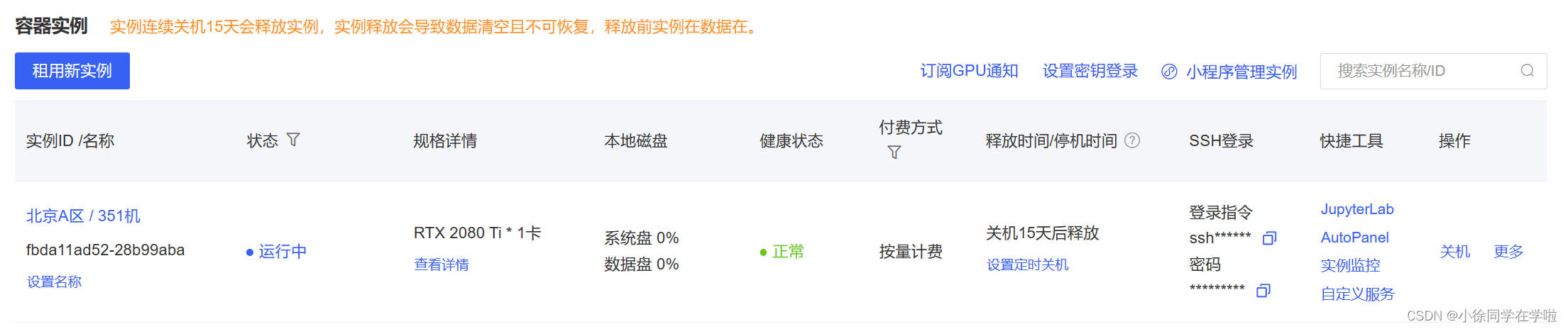
4.进入JupyterLab,点击终端。结束。★,°:.☆( ̄▽ ̄)/$:.°★ 。
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓进入正题↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
第一步——创建环境
conda create -n d4rl_env python=3.7
安装成功后要 输入conda init ,然后关闭终端,重新进入。
激活环境
conda activate d4rl_env
激活成功的界面就是小括号里的base变成你的环境名(如下图)

注意:在之前的很多次安装中,我都是在安装mujoco之前安装这些库,但是一直会遇到各种错误,后来我尝试先安装mujoco,就成功安装了。所以第一次按照正常流程安装的你,如果安装失败,可以直接跳到mujoco的安装,忽略下面的包安装。(感觉实际运行代码过程中也会遇到各种各样的包版本问题)
但是我成功安装mujoco和d4rl之后,安装不上这些包,目前还没解决,小徐会随时更新哒(●’◡’●)
安装相应的库(这一步可能出错多次,反复输入命令直至成功即可,需要等很久很久,花都谢掉的那种~≡(▔﹏▔)≡)
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.1 -c pytorch -c conda-forge
记录一下安装的版本信息,因为有两个差不过1G多的包,所以拼网速的时刻到了kkk(∪.∪ )…zzz

经过漫长的等待,安装完成后,我们输入以下命令进行检查是否安装成功
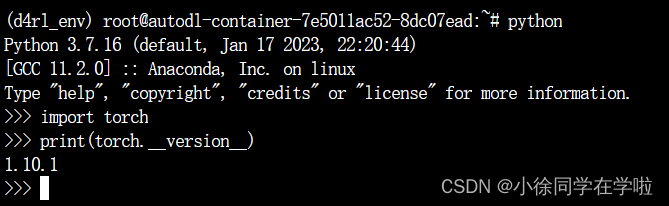
首先进入python(直接输入python)
import torch
print(torch.__version__) #注意是双下划线
输出结果如下证明我们安装成功
对了,退出python命令是exit()
(我第一次操作真的啥啥不知道,完全靠自己摸索,哭哭━┳━ ━┳━)
到此环境安装配置结束🎊
mujoco安装
linux下基础命令一些基本命令 cd进入文件 cd–退出文件
cd进入文件,下载压缩包
(新建一个Downloads文件夹,下载的东西都放在里边)
cd ~/Downloads/
wget https://github.com/deepmind/mujoco/releases/download/2.1.0/mujoco210-linux-x86_64.tar.gz
这一步也挺慢的。。。

解压
tar -zxvf mujoco210-linux-x86_64.tar.gz
然后改名字
mv mujoco210-linux-x86_64.tar.gz mujoco210
解压之后Downloads文件夹下多出来一个mujoco210文件夹
新建文件夹mujoco,把解压后的文件复制到我们之前建的mujoco文件夹下
mkdir ~/mujoco
cp -r mujoco210 ~/mujoco
接下来是环境变量的设置,如果你要在自己的电脑上安装,可以参考一些文章:
https://zhuanlan.zhihu.com/p/649494341
https://zhuanlan.zhihu.com/p/489475047
https://jasonzhujp.github.io/2023/04/06/coding-d4rl-install/
vim ~/.bashrc#进入配置文件
复制下面这条报错信息到文件最后,然后按电脑esc键,输入:wq!保存退出(英文状态下)。
export MUJOCO_KEY_PATH=~/.mujoco${MUJOCO_KEY_PATH}
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/root/.mujoco/mujoco210/bin
#export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/nvidia
需要更新一下
source ~/.bashrc
然后重新激活环境
然后测试看安装是否成功
cd ~/mujoco/mujoco210/bin
./simulate ../model/humanoid.xml
好像会出现一个木偶小人

但是我的只会出现一个版本信息,不会出现小人,网上的回复是可以忽略。

over!!!
Mujoco_py安装
#git clone https://github.com/openai/mujoco-py.git
#cd mujoco-py
#pip install -e .
pip install mujoco_py
cd mujoco-py
pip3 install -r requirements.txt
pip3 install -r requirements.dev.txt
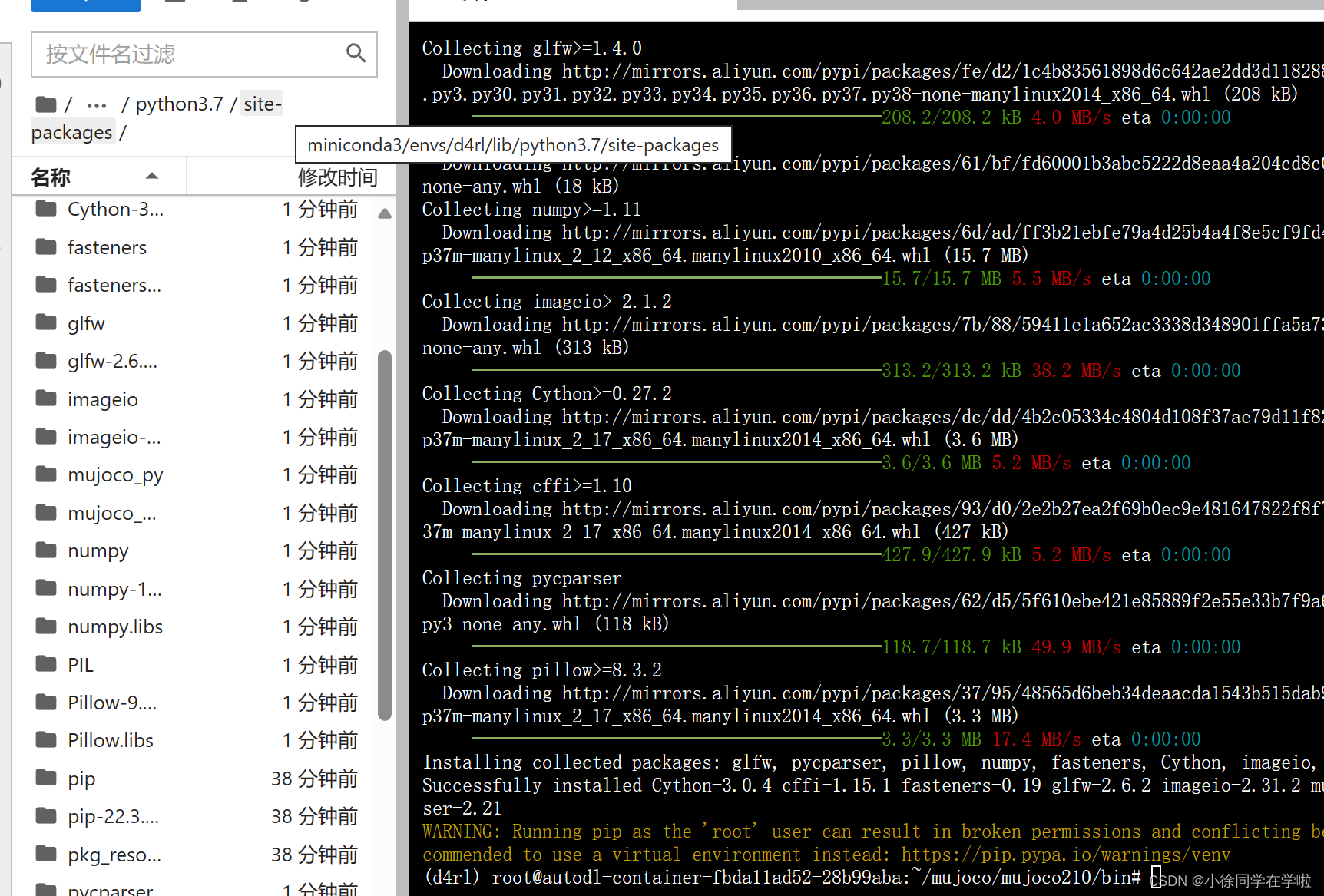
输入以上三条指令后,运行界面如下:

直接输入pip安装界面如下
然后检查,还是在python下
import mujoco_py
出现报错(正常现象)
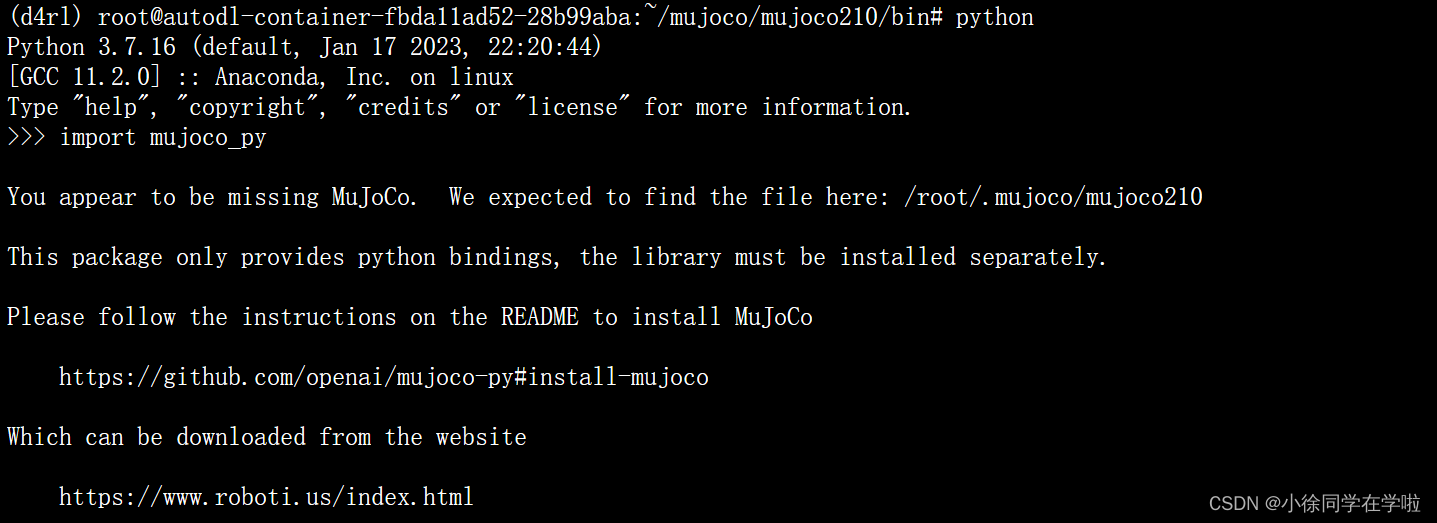
找不到路径,网上说是因为要下载mjkey?
这里还要到https://www.roboti.us/license.html这个网址申请mjkey,点击activation key,会下载一个.txt文件,把文件复制到mujoco210的bin文件夹下和mujoco文件夹下

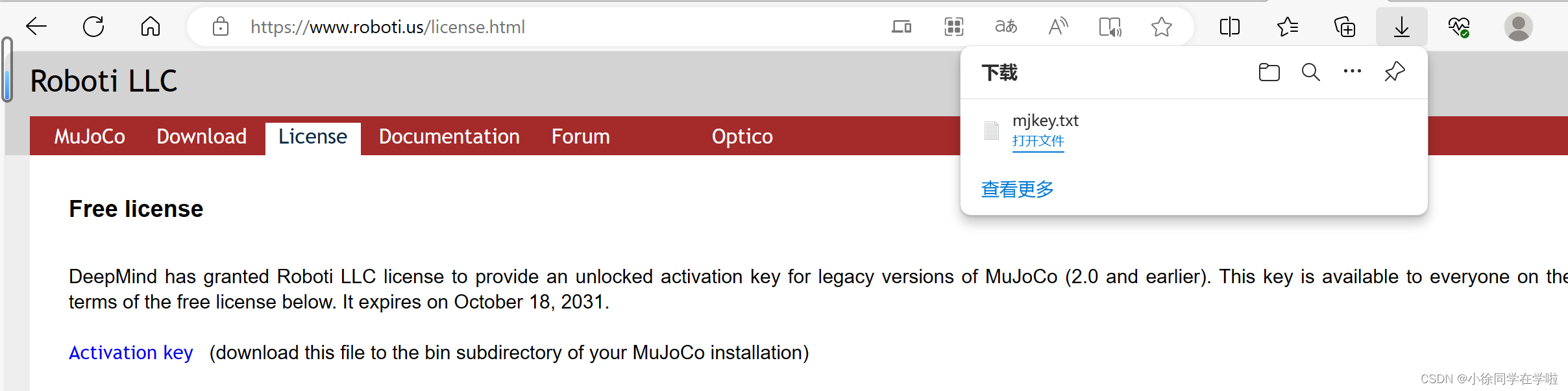
新的报错

fatal error: GL/osmesa.h: No such file or directory,那就安装libosmesa6-dev
sudo apt installaptitude
#选y
sudoaptitudeinstall libosmesa6-dev
#第一次选n,后两次选y
问题解决,再次在python下输入import mujoco_py,出现其他报错
Error: FileNotFoundError: [Errno 2] No such file or directory: ‘patchelf’: ‘patchelf’
sudo apt-get update -y
sudo apt-get install -y patchelf
问题解决,我可真棒~(✿◡‿◡)
…………………………………………………………………………
这一步可能出现不同报错,就反复解决,然后import mujoco_py
直到不报错,就安装成功了。
。以下代码逐行输入
import mujoco_py
import os
mj_path = mujoco_py.utils.discover_mujoco() # 这里好像修改了?改成mj_path = mujoco_py.utils.discover_mujoco()
xml_path = os.path.join(mj_path, 'model', 'humanoid.xml')
model = mujoco_py.load_model_from_path(xml_path)
sim = mujoco_py.MjSim(model)
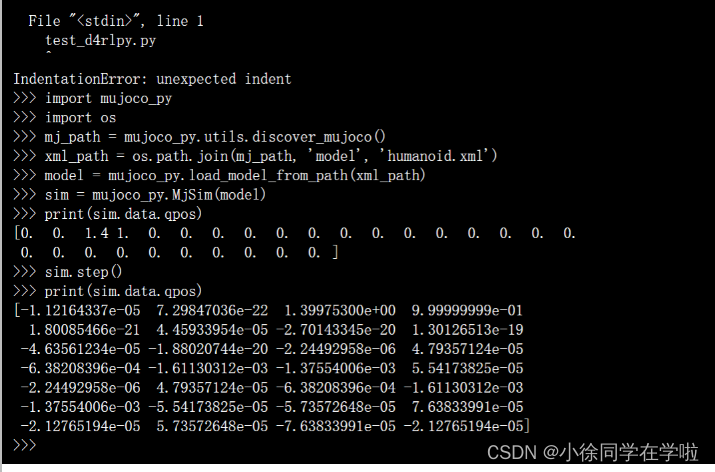
print(sim.data.qpos)
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
sim.step()
print(sim.data.qpos)
# [-2.09531783e-19 2.72130735e-05 6.14480786e-22 -3.45474715e-06
# 7.42993721e-06 -1.40711141e-04 -3.04253586e-04 -2.07559344e-04
# 8.50646247e-05 -3.45474715e-06 7.42993721e-06 -1.40711141e-04
# -3.04253586e-04 -2.07559344e-04 -8.50646247e-05 1.11317030e-04
# -7.03465386e-05 -2.22862221e-05 -1.11317030e-04 7.03465386e-05
# -2.22862221e-05]
安装dm
pip install dm_control
安装d4rl
克隆仓库‘
git clone https://github.com/rail-berkeley/d4rl.git
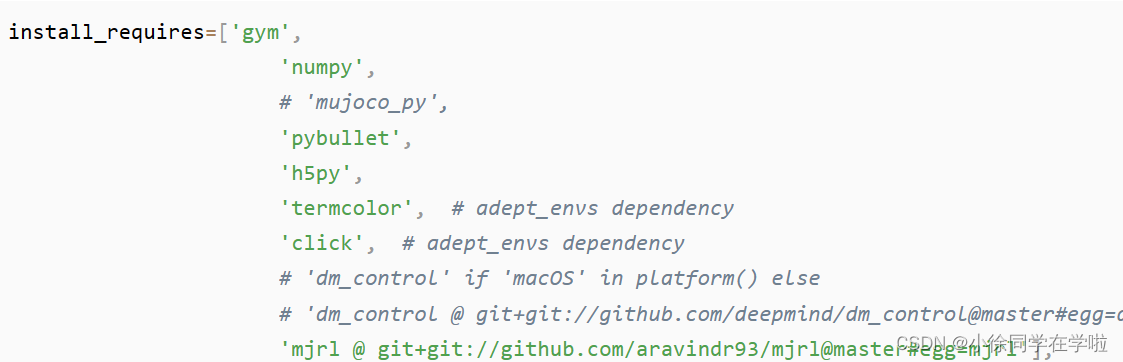
找到到d4rl目录下的setup.py文件,注释mujoco_py, dm_control
安装后在python下逐行敲入以下代码
# installing
pip install -e .
# 测试,创建test_d4rlpy.py并添加如下内容 vim test_d4rl.py
import gym
import d4rl # Import required to register environments
# Create the environment
env = gym.make('maze2d-umaze-v1')
# d4rl abides by the OpenAI gym interface
env.reset()
env.step(env.action_space.sample())
# Each task is associated with a dataset
# dataset contains observations, actions, rewards, terminals, and infos
dataset = env.get_dataset()
print(dataset['observations']) # An N x dim_observation Numpy array of observations
# Alternatively, use d4rl.qlearning_dataset which
# also adds next_observations.
dataset = d4rl.qlearning_dataset(env)
或者vim新建一个test_d4rl.py文件,然后再输入python test_d4rlpy.py。
测试结果如下
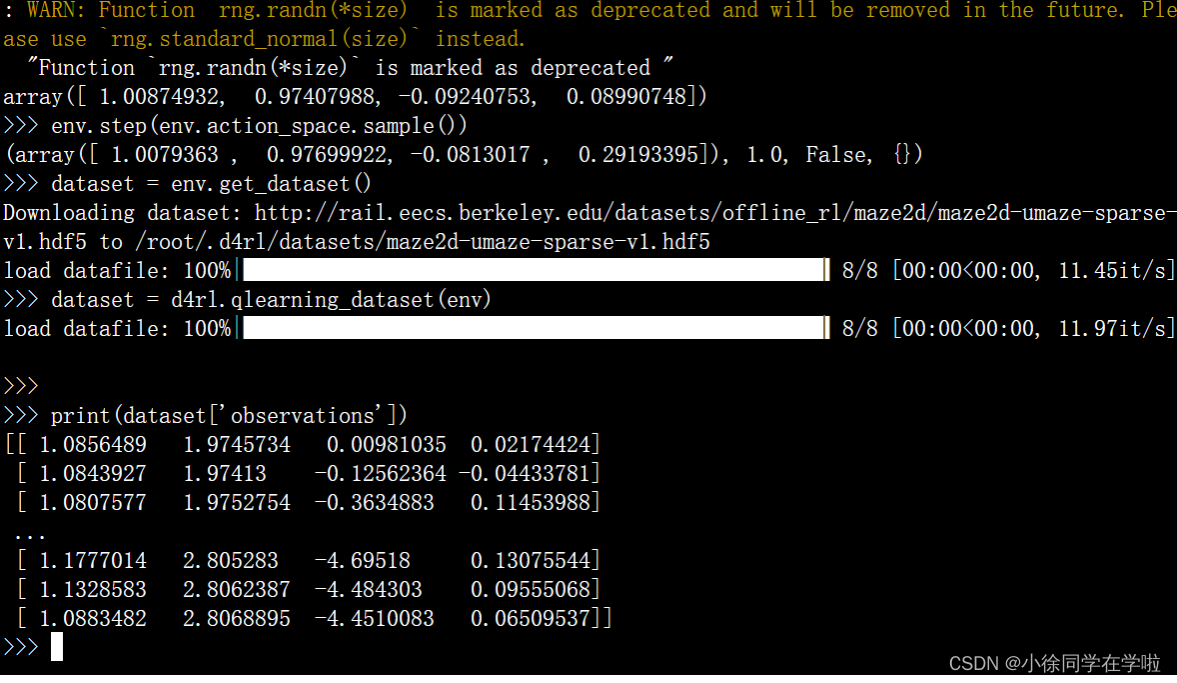
结束。撒花★,°:.☆( ̄▽ ̄)/$:.°★ 。















 1501
1501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









