






| Title | GoT: Unleashing Reasoning Capability of Multimodal Large Language Model for Visual Generation and Editing |
| Date | 13 March 2025 |
| Link | https://arxiv.org/abs/2503.10639 |
开源代码和数据集:https://github.com/rongyaofang/GoT
一、Why
Previous work:
-
传统的图像生成系统,尤其是扩散模型:将文本中的语义概念直接映射到视觉元素来生成图像,而不需要进行详细的逻辑推理。在处理需要精确的空间布局和对象之间复杂交互的场景时显得力不从心
| 发展 | Stable Diffusion引入了潜在空间压缩技术,提高了生成过程的效率。将高维数据(如图像)映射到一个低维的潜在空间中,从而在保留关键信息的同时减少计算复杂度和所需的存储空间。 |
| 通过架构创新和更大规模的数据训练,进一步提升了生成图像的真实感 | |
| 可控生成的方法,使得生成的图像可以根据特定需求进行调整。 | |
| 基于指令的编辑框架 ,允许用户通过自然语言指令来指导图像的编辑过程 | |
| 局限 | 当前的模型通常通过直接映射处理提示词,使用像 CLIP [33] 或 T5 [34] 这样的文本编码器,通过交叉注意力机制 [45] 来控制扩散过程。这种方法将文本视为静态表示,缺乏对场景构成或对象关系的显式推理。当生成包含多个对象并具有特定空间布局的复杂场景时,这种基本限制变得尤为明显 |
-
多模态大型语言模型(MLLMs)在执行复杂的推理任务方面表现出色
如何将那些已经在语言理解领域取得显著成就的推理机制整合进视觉内容的生成和编辑过程中?
-
第一条研究路线:使用LLM作为文本编码器,以提高对即时解释的能力,但没有充分利用LLM的推理能力。
将 LLM 用作一种高级的文本编码器,将自然语言输入编码转换为语义特征向量,这些语义特征随后被传递给下游生成模型(如扩散模型),用于生成图像或其他内容。
忽略了 LLM 的多步推理和上下文理解能力。
-
第二条研究路线:开发MLLM,旨在统一理解和生成过程
-
基于布局的方法(如GLIGEN、LayoutGPT和RPG)结合了用于布局规划的LLM和扩散模型,首先利用LLM来决定元素应该如何布局,然后使用扩散模型根据这个布局来生成最终的内容。但由于它们将规划和生成视为独立阶段,而不是在整个端到端过程中集成推理,因此也未能充分利用推理能力。
| GLIGEN | 引入了边界框的概念,并通过门控交叉注意力层将其整合到生成过程中 | 增强了模型在对象放置上的能力,例如更准确地定位和排列图像中的对象 | 在视觉合成中引入了布局规划,提升了对象放置和场景生成的能力 |
| LayoutGPT | 首先将文本描述转换为场景布局(如对象的位置和大小),然后基于这个布局生成最终的图像。 | 将文本信息转化为明确的布局指导 | |
| RPG | 布局优化和图像合成之间采用了递归规划的策略,模型会不断交替进行布局优化和图像合成,逐步完善生成结果。 | ||
| SmartEdit | 改进了现有的 LLaVA 模型,使其专门适用于图像编辑任务 | 强调通过预训练模型来提升图像编辑的精确性 | 结合了多模态理解和用户指令,增强了图像编辑的精确性和灵活性 |
| FlexEdit | 使用多模态大语言模型(MLLM)来理解图像内容、掩码和用户指令 | 结合多种信息源来增强编辑能力 | |
| 不足 | 布局被视为静态约束或生成前的顺序计划,与生成过程缺乏动态交互。 | 与生成过程缺乏动态交互,这种分离导致空间规划与生成过程脱节,限制了模型在复杂场景生成或编辑中的表现。 |
这些方法只是简单地将不同的任务联合起来,而不是在整个端到端过程中集成推理。当前的图像生成方法缺乏推理能力,强调了对将推理与视觉生成和编辑无缝地组合的框架的需要。
引入思维链的挑战:
-
challenge1:与LLM中的CoT不同,用于视觉生成和编辑的推理链需要语义信息和空间信息。它需要一种新的公式并以这种新的格式收集训练数据。
-
challenge2:其次,现有的基于扩散的模型不能利用显式的语言推理链进行视觉生成。我们需要设计一个支持端到端语言推理和视觉生成的框架
二、相关工作
贡献:
-
(challenge1)提出了生成思维链(GoT),这是一种将推理集成到视觉生成和编辑任务中的范例,为这些任务提供了显式的语义和空间推理。对于视觉生成,GoT提供对对象布局、关系和属性的精确控制,而对于编辑,它利用语义和空间理解将用户请求分解为连贯的基础和修改步骤。
-
我们定义了用于视觉生成和编辑的语义和空间推理链的公式,并收集了第一个大规模的GoT数据集,包括840万图像生成样本和92万图像编辑样本。
-
(challenge2)我们开发了一个统一的端到端框架,该框架利用多模态语言模型和扩散模型,并具有一个新颖的语义空间指导模块SSGM,可确保生成的图像遵循推理过程,由显式推理链指导。
-
我们的实验结果表明,文本到图像的生成和编辑都有显著的改进。
三、What

关键组件:
-
一个综合性的数据集:该数据集必须包含与视觉内容相对应的详细推理链,同时捕捉语义关系和空间配置。
-
一个兼容的视觉生成模型:该模型需要能够接受推理链输入,以整合语义分析和空间推理,从而确保有效执行从数据集中得出的推理步骤。
3.1 GoT数据集:用于视觉生成和编辑的语义空间推理链
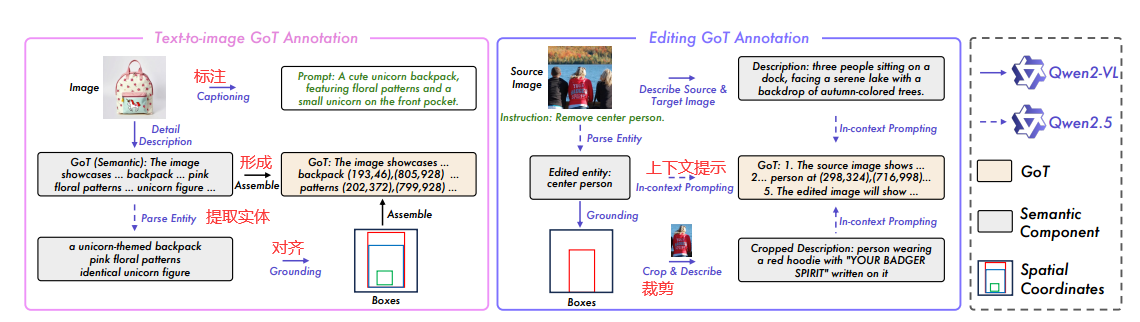

数据集:
-
图像生成:Laion-Aesthetics,JourneyDB和FLUX;
-
图像编辑:OmniEdit(单轮)和SEED-Edit-Multiturn(多轮)编辑操作(添加,删除,交换,更改表情/颜色/天气/照明和样式转换)
3.2 GoT框架:推理引导的视觉生成和编辑、

两个主要组件:
-
语义空间感知MLLM生成具有空间信息的结构化推理链
-
多引导扩散模型
3.2.1语义空间MLLM设计
采用了MLLM Qwen2.5VL-3B作为骨干
空间指引Gs通过解析和转换所生成的 GoT 推理链中的显式空间信息而导出。
语义引导嵌入 Gt 是通过模型对 [IMG] 标记的编码以及结合推理链中的信息生成的
[IMG] 标记 是一种特殊的占位符(token),用于表示图像的潜在表示或特征向量。
MLLM 通过两条路径接收监督信号:一是对 GoT 推理标记的交叉熵损失,二是通过语义引导 Gt 从端到端的SSGM 扩散模块反向传播的梯度信号。
交叉熵损失:
-
针对推理标记(GoT)的任务,直接优化 MLLM 的推理能力。
-
这种监督信号主要关注模型的语言理解和推理能力。
梯度信号:
-
针对生成任务,通过扩散模型的损失反向传播优化 MLLM 的语义引导能力。
-
这种监督信号主要关注模型的生成能力和语义表达能力。
3.2.2语义空间引导扩散生成
端到端扩散模块建立在SDXL的架构之上,通过我们的语义空间指导模块(SSGM)集成了语义理解,空间感知和参考知识。
语义指导Gt:通过引导N = 64 MLLM生成的嵌入Gt通过交叉注意层来增强扩散模型,取代传统的CLIP嵌入,以实现更精确的语义控制。
空间引导Gs:我们从生成的 GoT 中提取坐标信息,创建颜色编码的掩码。每个对象或编辑区域根据 GoT 序列中预定义的顺序被赋予不同的颜色。这些颜色编码的掩码通过 VAE 编码器 [18] 处理并取平均值,生成空间潜在特征 Gs。这些特征与扩散模型的潜在表示相连接,从而在生成和编辑任务中实现精确的空间控制。
参考图像指导Gr:对于编辑任务,源图像作为参考,而对于文本到图像生成,我们使用黑色的参考图像来保持体系结构的一致性。所有参考都通过VAE编码器进行处理,以提取视觉特征Gr.
3.2.3多指导策略
我们采用了一种无分类器的指导策略,集成了语义、空间和参考图像指导。在扩散过程中,通过加权组合计算得分估计εθ:
$$εθ =εθ(zt, ∅, ∅, ∅)+αt · [εθ(zt, Gt, ∅, Gr) − εθ(zt, ∅, ∅, Gr)]+αs · [εθ(zt, Gt, Gs, Gr) − εθ(zt, Gt, ∅, Gr)]+αr · [εθ(zt, ∅, ∅, Gr) − εθ(zt, ∅, ∅, ∅)]$$
zt是噪声潜在,Gt表示语义指导嵌入,Gs表示空间指导特征,Gr表示参考图像特征。指导尺度αt、αs和αr控制每种指导类型的强度,而∅表示空条件作用。
-
通过引入 𝛼𝑡,𝛼𝑠,𝛼𝑟模型可以在不同的任务中灵活调整各类型引导的重要性。例如,在某些任务中可能更注重语义信息(增大 𝛼𝑡),而在其他任务中则可能更关注空间布局(增大 𝛼𝑠)。
-
在训练过程中,随机采样不同的条件组合(包括部分条件和无条件的情况),可以增强模型的鲁棒性。例如,排除全条件情况 𝜖𝜃(𝑧𝑡,𝐺𝑡,𝐺𝑠,𝐺𝑟) 的随机采样有助于防止过拟合,并确保模型能够在不同条件下稳定工作。
-
ϵθ(zt,conditions) 是扩散模型的核心,它是一个神经网络的输出,用于预测用于前时间步 zt 中的噪声分布。
-
调整 αt,αs,αr 的目的是优化ϵθ,使其能够更好地结合语义、空间和参考图像等信息,从而生成或编辑出高质量的图像。
-
得到 𝜖𝜃后,我们用它来进行逆向扩散过程,逐步去噪,最终生成或编辑出符合预期的图像。
四、How
训练过程
预训练:LAHR-GoT, JourneyDB-GoT, OmniEdit-GoT(60,000轮)
微调:FLUX-GoT、OmniEdit-GoT和SEEDEDit-MultiTurn-GoT(10,000轮)
采用LoRA来高效更新 Qwen2.5-VL 解码器的参数,同时对基于 SDXL 的扩散模块进行完全优化。整个过程以端到端的方式运行,联合优化 MLLM GoT 的交叉熵标记损失和扩散模块的均方误差(MSE)损失,并赋予两者相同的权重 1.0,从而在无需复杂超参数调优的情况下展现出强大的鲁棒性。
4.1文本到图像生成
GoT框架采用αt = 7.5和αs = 4.0
不管αr ,T2I任务不需要用到Gr
4.1.1定量分析

两大类别:那些采用冻结文本编码器来直接生成文本到图像的方法(主要是基于扩散的方法)和利用LLM或MLLM来增强生成过程的方法。
Attribute Binding任务指的是模型识别并绑定(关联)不同属性到相应对象上的能力。
4.1.2定性分析

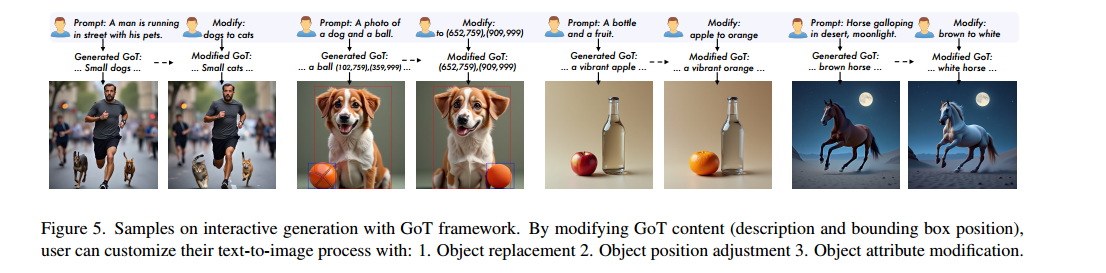
4.2交互式生成
用户能够通过修改GoT内容(包括文本描述和边界框位置)来控制生成过程。用户可以通过三种主要的交互类型来定制他们的文本到图像生成:物体更换,物体位置调整,和对象属性修改。
4.3图像编辑
GoT框架采用αt = 4.0,αs = 3.0,αr = 1.5
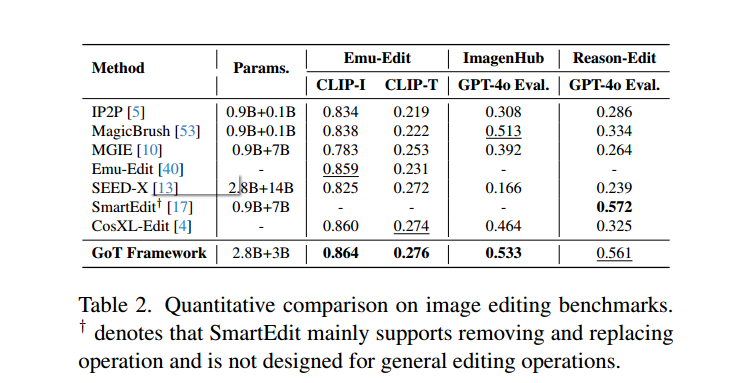

首先,我们的模型准确地识别和定位了通过间接描述引用的对象。其次,我们的方法有效地处理了复杂的空间指令,例如删除特定的标志或向精确位置添加精致的元素。第三,我们的框架擅长多步编辑操作。
4.4.框架设计的消融研究

基准:GenEval和ImagenHub;基线模型:Qwen2.5-VL-3B和SDXL,不包含GoT推理链。
SSGM提供了对扩散模型的空间控制,确保对象放置与推理过程更准确地对齐。这可以实现细粒度编辑,如ImagenHub评估的显著改进所反映的那样。但是,在GenEval中,只有位置类别受到SSGM的显著影响,这解释了相对较小的性能增益。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









