






强化学习Datawhale打卡班
第1章 强化学习基础
强化学习(reinforcement learning,RL)讨论的问题是智能体(agent)怎么在环境(environment)中最大化奖励。
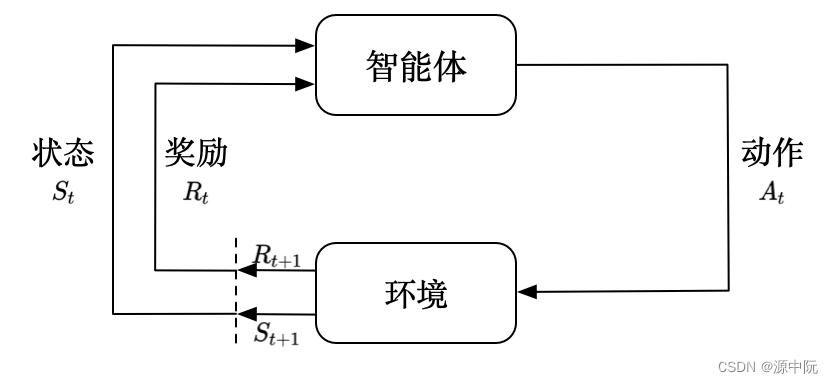
强化学习和监督学习的区别
强化学习和监督学习的区别如下:
(1)强化学习输入的样本是序列数据,监督学习样本是独立的。
(2)学习器不知道正确的动作应该是什么,需要通过不停地尝试,自己去发现哪些动作可以得到最多的奖励。
(3)智能体获得自己能力的过程,其实是不断地试错探索(trial-and-error exploration)的过程。探索 (exploration)和利用(exploitation)是强化学习里面非常核心的问题。
(4)在强化学习过程中,没有非常强的监督者(supervisor),只有奖励信号(reward signal),并且奖励信号是延迟的。
序列决策
在一个强化学习环境里面,智能体的目的就是选取一系列的动作来最大化奖励。但在这个过程里面,智能体的奖励被延迟,即智能体当时做出的决策,要等到很久后才知道这一步产生了什么样的影响。
强化学习通常被建模成部分可观测马尔可夫决策过程(partially observable Markov decision process, POMDP)的问题。 部分可观测马尔可夫决策过程依然具有马尔可夫性质,但是假设智能体无法感知环境的状态,只能知道部分观测值。比如在自动驾驶中,智能体只能感知传感器采集的有限的环境信息。部分可观测马尔可夫决策过程可以用一个七元组描述:(S,A,T,R,Ω,O,γ)。其中 SS 表示状态空间,为隐变量,AA 为动作空间,T(s′∣s,a) 为状态转移概率,RR 为奖励函数,Ω(o∣s,a)Ω(o∣s,a) 为观测概率,OO 为观测空间,γγ 为折扣系数。















 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









