






马尔可夫决策过程
MDP
1.马尔科夫链及马尔可夫奖励过程
Markov Property
如果一个状态转移是符合马尔可夫的,那就是说一个状态的下一个状态只取决于它当前状态,而跟它当前状态之前的状态都没有关系。
Markov Process/Markov Chain
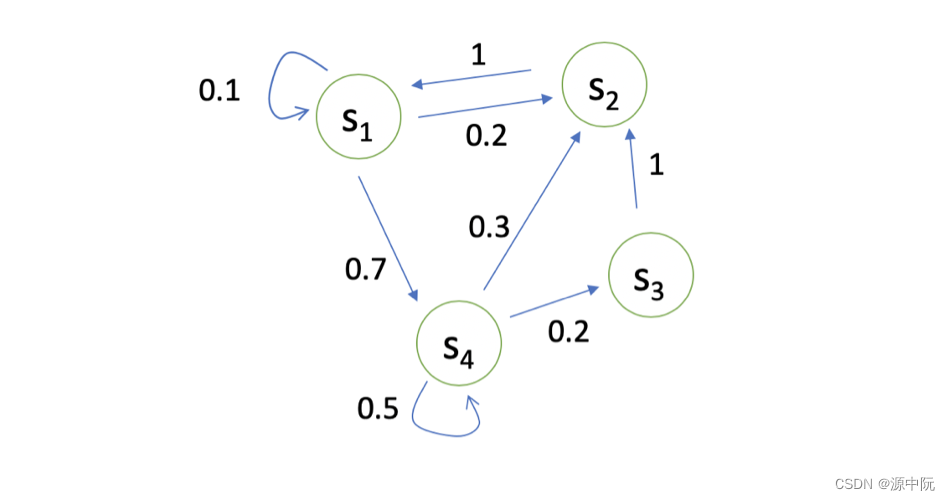
可以用状态转移矩阵(State Transition Matrix) P 来描述状态转移
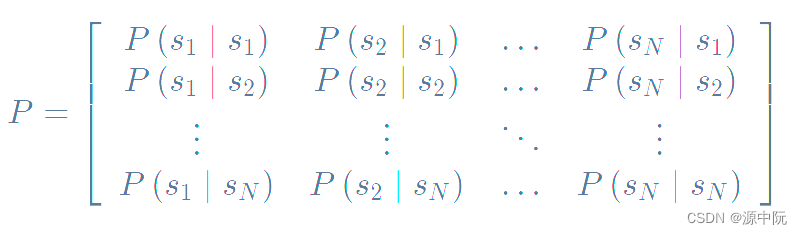
Markov Reward Process(MRP)
马尔可夫奖励过程(Markov Reward Process, MRP) 是马尔可夫链再加上了一个奖励函数。奖励只当其变换到某一个状态的时候,可以获得的结果。同时,定义一些概念:
1.Horizon 是指一个回合的长度(每个回合最大的时间步数),它是由有限个步数决定的。
2.Return(回报) 说的是把奖励进行折扣后所获得的收益。Return 可以定义为奖励的逐步叠加,如下式所示:
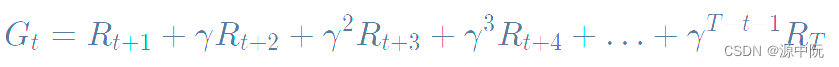
这里有一个叠加系数,越往后得到的奖励,折扣得越多。这说明我们其实更希望得到现有的奖励,未来的奖励就要把它打折扣。(这里容易使人联想到其在金融股票投资等的应用,如等一个月赚1000元与等一年赚2w,前者更能够被接受。)
Discount factor 可以作为强化学习 agent 的一个超参数来进行调整,然后就会得到不同行为的 agent。
state value function:对于 MRP,state value function 被定义成是 return 的期望,如下式所示:
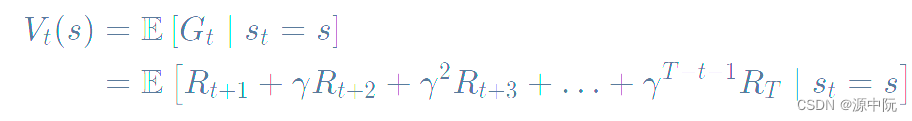
Bellman Equation(贝尔曼等式)

我的理解是,未来打了折扣的奖励加上现在状态下可以立刻获得的奖励,就组成了这个等式。
Law of Total Expectation(全期望公式)
仿照Law of Total Expectation(全期望公式)的证明过程来证明下面的式子:
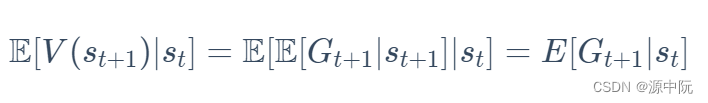
全期望公式如下所示:
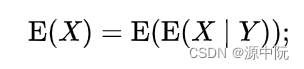
证明过程如下:
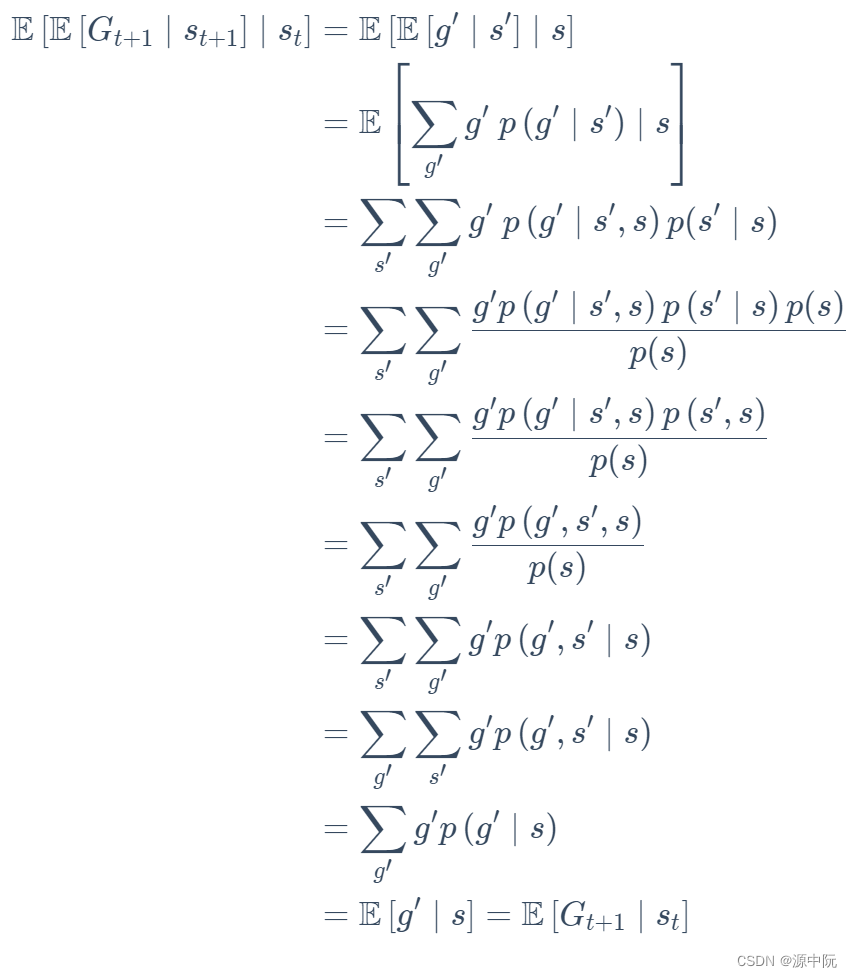
由此,bellman推导过程如下:
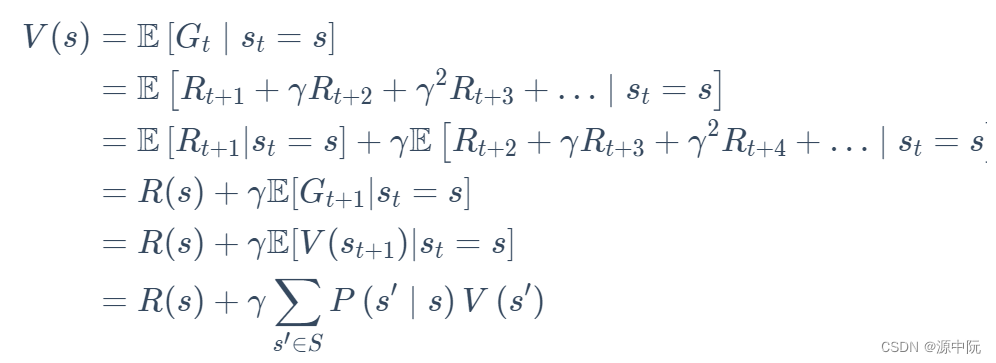
求解得到v的解析解,由于其算法复杂度过高(O = N^3),只适用于很小量的MRP
求解方法
主要包含
1.动态规划的方法,
2.蒙特卡罗的办法(通过采样的办法去计算它),
3.时序差分学习(Temporal-Difference Learning)的办法。 Temporal-Difference Learning 叫 TD Leanring,它是动态规划和蒙特卡罗的一个结合。
1.动态规划的方法:一直去迭代bellman equation,当其收敛时,可以得到它的一个状态。

2.蒙特卡罗方法:从某状态开始,产生一个轨迹及奖励,即可得到折扣奖励g,累计到一定轨迹后,直接用gt除以轨迹数量,就会得到价值。

Markov Decision Process(MDP)
相比于MRP,MDP多了决策过程,在状态专业中也多了一个动作,

且价值函数多了一个条件
知道当前状态过后,我们可以把当前状态带入 policy function,然后就会得到一个概率,即















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









