









正则化
正则化的作用实际上就是防止模型过拟合,提高模型的泛化能力。
正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项(regularizer)或惩罚项(penalty term)。正则化一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。比如,正则化项可以是模型参数向量的范数。正则化项可以:
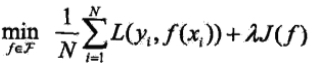
其中,第1项是经验风险,是对第i个样本的预测值f(xi)和真实的标签yi之前的误差,因为我们的模型是要拟合我们的训练样本,所以我们要求这一项最小,也就是要求我们的模型尽量的拟合我们的训练数据;第2项是正则化项,也就是对参数w的规则化函数J(f)去约束我们的模型尽量的简单,λ>=0(读音:lambda)为调整两者之间关系的系数。

L0范数
L0是指向量中非0的元素的个数。 如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0。换句话说,让参数W是稀疏的。
但不幸的是,L0范数的最优化问题是一个NP hard问题,而且理论上有证明,L1范数是L0范数的最优凸近似,因此通常使用L1范数来代替。

L1范数
L1范数是指向量中各个元素绝对值之和 ,也有个美称叫“稀疏规则算子”(Lasso regularization)。
L1正则化之所以可以防止过拟合,是因为L1范数就是各个参数的绝对值相加得到的,我们前面讨论了,参数值大小和模型复杂度是成正比的。因此复杂的模型,其L1范数就大,最终导致损失函数就大,说明这个模型就不够好。
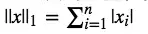
L2范数
L2范数向量元素绝对值的平方和再开平方 ,也叫“岭回归”(Ridge Regression),也叫它“权值衰减weight decay”。
但与L1范数不一样的是,它不会是每个元素为0,而只是接近于0。越小的参数说明模型越简单,越简单的模型越不容易产生过拟合现象。
L2范数即欧氏距离:
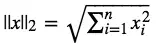
elastic net
L1+L2结合的方式,即elastic net。这种方式同时兼顾特征选择(L1)和权重衰减(L2)。其公式如下这种方式同时兼顾特征选择(L1)和权重衰减(L2)。其公式如下
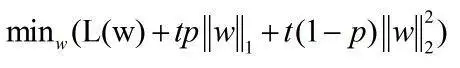
上式中,t为正则项与L(w)之间的trade-off系数,和之前的描述一致,p是elastic net里独有的参数,它是L1和L2之间的一个trade-off,如果p为0,那么上式退化为L2正则化,如果p为1,那么上式退化为L1正则化。所以当p取值为0到1时(不包含端点),上式兼顾了L1和L2的特点。又由于L1为1范式,L2为2范式,那么elastic net就介于1范式和2范式之间。
总结
L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。所有特征中只有少数特征起重要作用的情况下,选择L1更合适;而如果所有特征中,大部分特征都能起作用,而且起的作用很平均,选择L2更合适。
- L1/L2范数让模型变得稀疏,增加模型的可解析性,可用于特征选择。
- L2范数让模型变得更简单,防止过拟合问题。
讨论几个问题
为什么L1稀疏,L2平滑?
这个角度从权值的更新公式来看权值的收敛结果。
首先来看看L1和L2的梯度(求导过程,同时假定:w等于不为0的某个正的浮点数,学习速率η 为0.5,λ为1.0):
L1梯度:
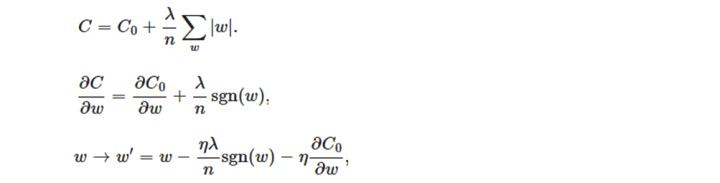
L1正则化是通过加上或减去一个常量ηλ(η读作eta ,λ读作lambda}),让w向0靠近。也即是w = w - η*λ = w - 0.5*1.0,权值每次更新都固定减少一个特定的值(比如0.5),那么经过若干次迭代之后,权值就有可能减少到0。
L2梯度:
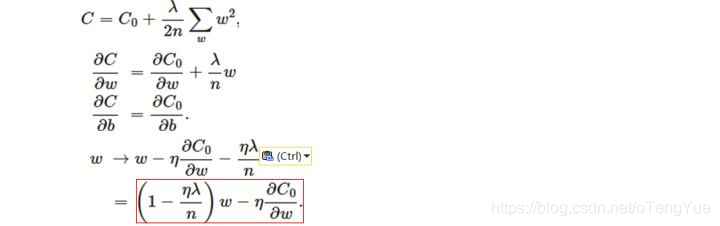
L2正则化,它使用了一个乘性因子 (1-ηλ)去调整权重,使权重不断衰减。也即是w = (1 - η*λ) * w = (1 - 0.5*1.0)*w = 0.5*w,此时可以看到当w值较大时,L2下降速度较快,当w小的时候,下降较慢。虽然权值不断变小,但是因为每次都等于上一次的一半,所以很快会收敛到较小的值但不为0。
实现参数的稀疏有什么好处吗?
一个好处是可以简化模型,避免过拟合。因为一个模型中真正重要的参数可能并不多,如果考虑所有的参数起作用,那么可以对训练数据可以预测的很好,但是对测试数据就只能呵呵了。另一个好处是参数变少可以使整个模型获得更好的可解释性。
参数值越小代表模型越简单吗?
是的。为什么参数越小,说明模型越简单呢,这是因为越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括一些异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反映了在这个区间里的导数很大,而只有较大的参数值才能产生较大的导数。因此复杂的模型,其参数值会比较大。
正则式的应用场景
见:
通俗易懂–岭回归(L2)、lasso回归(L1)、ElasticNet讲解(算法+案例):https://juejin.im/post/5c34c5f36fb9a049d13250b7
参考:
《统计学习方法》-李航
机器学习中的范数规则化之(一)L0、L1与L2范数:http://www.cnblogs.com/weizc/p/5778678.html
L0、L1、L2范数在机器学习中的应用:https://www.jianshu.com/p/4bad38fe07e6
L1,L2,L0区别,为什么可以防止过拟合:https://www.jianshu.com/p/475d2c3197d2
岭回归、lasso、ElasticNet、正则化、L1、L2小结:https://vimsky.com/article/969.html
为什么L1稀疏,L2平滑?:https://blog.csdn.net/yitianguxingjian/article/details/69666447

















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









