









1、动机
CNN中的核心操作就是卷积,早期大多研究都在探索如何增强空间编码能力,以提升CNN的性能。这篇文章探索了通道上的注意力,明确地建模通道间的依赖关系,并提出了一个新颖的模块,称为SE-block。
2、方法
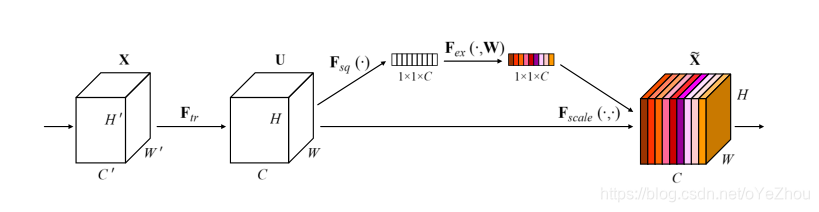
SE的架构如上图所示,简单描述为:
- 对于一个输入X,其经过卷积之后得到一个feature map(U),对于该feature map即可接上一个SE块,来附加上通道注意力;
- 对于U,先将其每个通道的空间信息压缩到一个单值,也即从H*W*C大小的U得到了1*1*C大小的向量;
- 然后,对该向量应用一组FC层进行权重调整,得到一个1*1*C的通道注意力向量;
- 最后,将通道注意力向量加权到U,形成一个加权后的feature map。
可以看出,SE的原理还是非常简单,总的来说,SE就是对每个通道上的权重进行了显式建模,然后再对原feature map加权,使其每个通道具有不同的重要程度,也即有了通道注意力机制。
3、Pytorch实现
下面给出SE模块的Pytorch实现,可以将下面的代码作为插件用于任意feature map之后,以增强其通道注意力。
import torch
from torch import nn
class SE_Block(nn.Module):
def __init__(self, ch_in, reduction=16):
super(SE_Block, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局自适应池化
self.fc = nn.Sequential(
nn.Linear(ch_in, ch_in // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(ch_in // reduction, ch_in, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c) # squeeze操作
y = self.fc(y).view(b, c, 1, 1) # FC获取通道注意力权重,是具有全局信息的
return x * y.expand_as(x) # 注意力作用每一个通道上



















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











