








 本文介绍了如何使用Python代码从PETA数据集中解析行人的性别属性,并将图片按性别分类到不同的文件夹。该数据集包含多个子数据集,每个子数据集具有不同的视角、光照和分辨率,总共有8705个行人和19000张图像。提供的代码实现了读取Label.txt文件,根据个人ID和性别信息复制图片到相应的男性或女性文件夹。
本文介绍了如何使用Python代码从PETA数据集中解析行人的性别属性,并将图片按性别分类到不同的文件夹。该数据集包含多个子数据集,每个子数据集具有不同的视角、光照和分辨率,总共有8705个行人和19000张图像。提供的代码实现了读取Label.txt文件,根据个人ID和性别信息复制图片到相应的男性或女性文件夹。
本文提供了一个从PETA数据集中提取性别属性的方法,并提供了代码实现及下载方式。
目录
1、数据集介绍
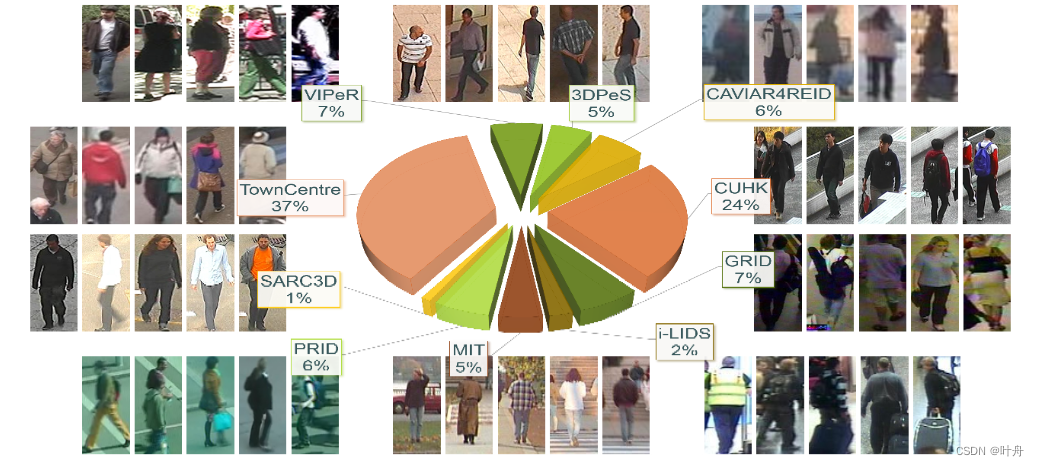
PETA (PEdesTrian Attribute)数据集包含了8705个行人,共19000张图像(分辨率跨度范围大,从17x39到169x365的大小都有)。每个行人标注了61个二值的和4个多类别的属性。实际上,PETA数据集是由多个较小的行人重识别数据集经过属性标注后汇集而成的。
数据集包含了多种场景,每种场景的详情如下:
| Datasets | #Images | Camera angle | View point | Illumination | Resolution | Scene |
| 3DPeS | 1012 | high | varying | varying | from 31x100 to 236 x 178 | outdoor |
| CAVIAR4REID | 1220 | ground | varying | low | from 17x39 to 72x141 | outdoor |
| CUHK | 4563 | high | varying | varying | 80x160 | indoor |
| GRID | 1275 | varying | frontal & back | low | from 29x67 to 169x365 | indoor |
| i-LIDS | 477 | medium | back | high | from 32x76 to 115x294 | outdoor |
| MIT | 888 | ground | back | high | 64x128 | outdoor |
| PRID | 1134 | high | profile | low | 64x128 | outdoor |
| SARC3D | 200 | medium | varying | varying | from 54x187 to 150x307 | outdoor |
| TownCentre | 6967 | medium | varying | medium | from 44x109 to 148x332 | outdoor |
| VIPeR | 1264 | ground | varying | varying | 48x128 | outdoor |
| Total = PETA | 19000 | varting | varying | varying | varying | varying |
数据集样式如下:















2、代码实现
通过以下代码,可以从数据集中解析出每个图片的属性,并根据性别存放到不同文件夹:
"""
parse person's gender from PETA
"""
import glob
import os
import shutil
def parse_peta(root_path, new_dataset_path):
classes = ['0_Female', '1_Male']
os.makedirs(new_dataset_path, exist_ok=True)
Male_path = os.path.join(new_dataset_path, '1_Male')
Female_path = os.path.join(new_dataset_path, '0_Female')
os.makedirs(Male_path, exist_ok=True)
os.makedirs(Female_path, exist_ok=True)
for sub_ds in os.listdir(root_path):
print("processing: {}".format(sub_ds))
label_path = os.path.join(root_path, sub_ds, 'archive', 'Label.txt')
imgs_path = os.path.join(root_path, sub_ds, 'archive')
with open(label_path, 'r') as f:
lines = f.readlines()
for line in lines:
line_split = line.replace('\n', '').split(' ')
person_id = line_split[0]
cls_id = 1 if 'personalMale' in line_split else 0
class_name = classes[cls_id]
person_imgs = glob.glob(imgs_path + '/{}*'.format(person_id))
for person_img in person_imgs:
name = person_img.split('/')[-1]
img_save_to = os.path.join(new_dataset_path, class_name, 'peta_' + name)
shutil.copy(person_img, img_save_to)
if __name__ == '__main__':
root_path = '../PETA/PETA dataset'
new_dataset_path = '../from_PETA'
parse_peta(root_path=root_path, new_dataset_path=new_dataset_path)参考:
下载:http://mmlab.ie.cuhk.edu.hk/projects/projects/PETA_files/PETA.zip
Pedestrian Attribute Recognition At Far Distance
Y. Deng, P. Luo, C. C. Loy, X. Tang, "Pedestrian attribute recognition at far distance", in Proceedings of ACM Multimedia (ACM MM), 2014


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











