









paper:https://arxiv.org/abs/1501.00092
code: Learning a Deep Convolutional Network for Image Super-Resolution
目录
1. 背景及动机
什么是图像超分辨率?
其目的就是将图像从低分辨率恢复到高分辨率。然而,简单想一下就发现,这个任务本质上是不适定(ill-posed)的,也就是说其是欠定的逆问题,其解不唯一(PS:这就相当于无中生有,凭空想象出高分辨率的细节特征)。所以通常需要较强的先验知识来做一些约束。
有哪些传统方法?
要么利用同一图像的内部相似性[5],[13],[16],[19],[47],要么从外部低分辨率和高分辨率样本对中学习映射函数[2],[4],[6],[15],[23],[25],[37],[41],[42],[47],[48],[50],[51]。后者根据提供的训练样本,可以为通用图像超分辨率制定基于外部示例的方法,或者可以根据提供的训练样本设计以适应特定领域的任务,即面部幻觉 [30]、[50]。
作者提出SRCNN的动机是什么?
对于上述两种传统方法的后者,也即基于外部样本的方法,基于稀疏编码的方法 [49]、[50] 是具有代表性的方法之一。这种方法在其解决方案管道中涉及几个步骤。首先,从输入图像和预处理(例如,减去均值和归一化)中密集裁剪重叠的补丁。然后,这些补丁由低分辨率字典编码。最后,稀疏系数被传递到高分辨率字典中,用于重建高分辨率补丁。
那作者就发现了上述三个步骤,可以利用深度学习统一起来,形成一个端到端的框架,可以直接学习低分辨率图像和高分辨率图像之间的端到端映射,而把中间的patch提取、字典映射、patch合并步骤都通过隐藏层来实现。由此,就形成了SRCNN。
2. 方法
对于一幅低分辨了的原图,先使用bicubic插值得到Y,这个Y同样称为低分辨图,尽管其大小与高分辨率图相等;然后,目的就是使用一个映射函数F得到高分辨结果:F(Y),使其尽可能与真正的高分辨图X相似。所以可以看出,这是个有监督框架,而唯一目标就是通过最小化F(Y)与X的误差来学习一个映射函数F。具体实现见下面描述。
作者沿用稀疏编码的形式,将图像超分表示为三个步骤:
- 1)patch提取和表示:将低分辨图像Y分为若干有重叠的patch,并表示为高维向量;
- 2)非线性映射:将每个patch表示映射到另一个高纬空间,这对应于稀疏编码中低分辨字典到高分辨率字典的映射;
- 3)重构:将高分辨率patch的表示聚合形成最终的高分辨率图像;这对应于利用高分辨率字典重建高分辨率图像的过程;
上述三个步骤,可以用三个卷积层来表示:
![]()
![]()
![]()
网络结构如下:

3. 代码
代码实现【引自:SRCNN-pytorch/models.py at master · yjn870/SRCNN-pytorch · GitHub】也十分之简单,就是三个卷积层+两个激活层:
from torch import nn
class SRCNN(nn.Module):
def __init__(self, num_channels=1):
super(SRCNN, self).__init__()
self.conv1 = nn.Conv2d(num_channels, 64, kernel_size=9, padding=9 // 2)
self.conv2 = nn.Conv2d(64, 32, kernel_size=5, padding=5 // 2)
self.conv3 = nn.Conv2d(32, num_channels, kernel_size=5, padding=5 // 2)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.conv3(x)
return x4. 实验结果
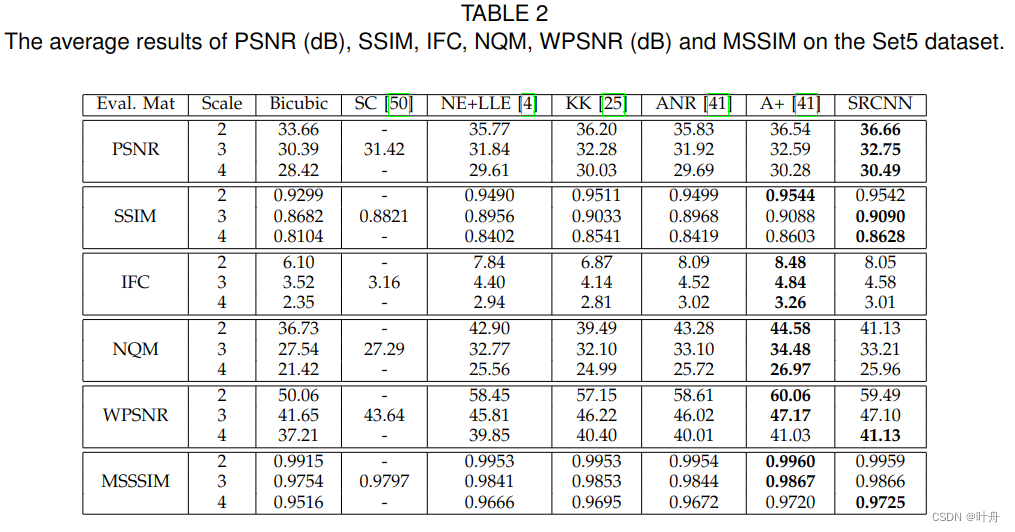
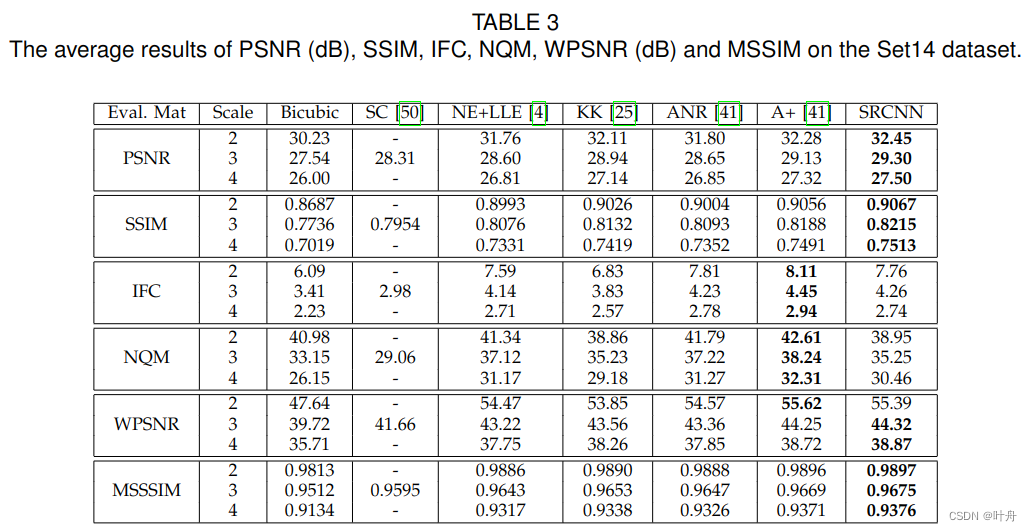
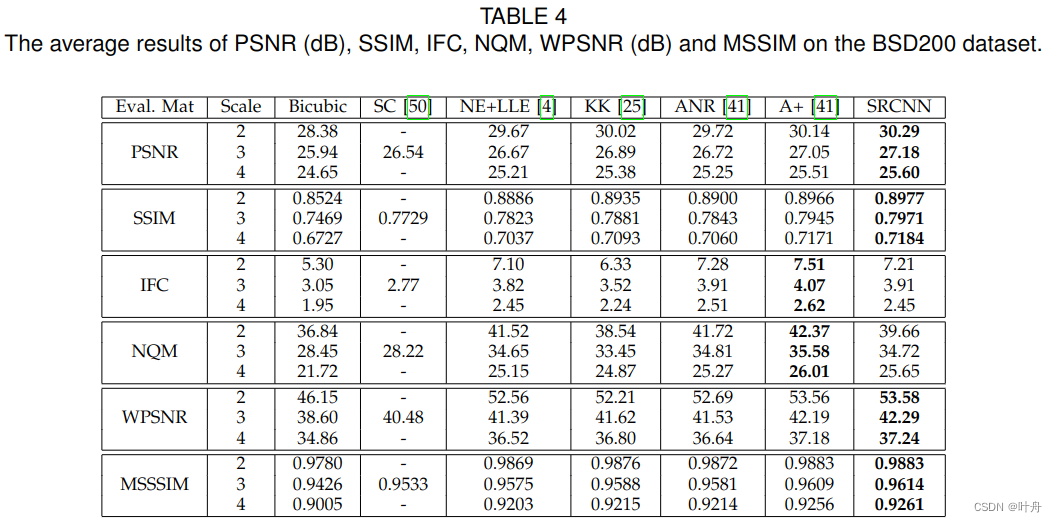
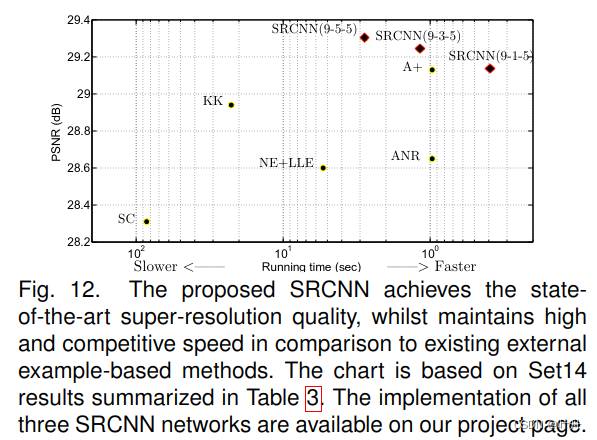



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











