









大模型发展日益迅猛,作为普通开发人员,如何快速跟上节奏、把大模型应用到我们自己的产品中呢?这里给出一个解决方案,可以快速在本地部署一套大模型服务,并能通过多种方式进行应用。
目录
1. Ollama介绍
Ollama 是一个开源的大型语言模型(LLM)服务工具,旨在简化在本地机器上部署和运行大型语言模型的过程。
- 本地部署:Ollama 允许用户在本地机器上部署和运行大型语言模型,无需依赖外部服务器或云服务。这使得用户可以在私有环境中使用强大的语言模型功能,保护数据隐私和安全性.
- 简化部署过程:通过提供一键安装和配置的脚本,Ollama 大幅简化了在 Docker 容器中部署大型语言模型的过程。用户只需运行简单的命令,即可快速搭建起模型运行环境,无需手动配置复杂的依赖和参数.
- 多模型支持:Ollama 支持多种流行的大型语言模型,如 Llama、Falcon 等。用户可以根据自己的需求选择不同的模型进行部署和使用,无需为每种模型单独配置环境.
- 模型导入与定制:支持从多种格式导入模型,如 GGUF、PyTorch 和 Safetensors。用户还可以通过编写 Modelfile 配置文件来自定义模型的推理参数,满足特定的业务需求.
- 推理加速:Ollama 提供多种加速推理的技术,如混合精度(FP16)和张量并行(Tensor Parallelism),可有效提高模型的推理速度,降低延迟,提升用户体验.
- 资源高效利用:在保持高性能的同时,Ollama 优化了资源的使用,使得在资源受限的设备上也能高效运行大型语言模型,降低了硬件要求和成本.
- 简洁的 API:Ollama 提供了简洁的 API,使得开发者能够轻松创建、运行和管理大型语言模型实例。API 的设计遵循 RESTful 原则,易于理解和使用.
- OpenAI API 兼容:Ollama 完整实现了 OpenAI API 规范,能够与其他基于该规范的工具和平台无缝集成。这使得用户可以利用现有的 OpenAI 应用程序和工具来调用 Ollama 部署的模型,无需修改代码.
- 跨平台兼容性:支持 macOS、Windows 和 Linux 系统,这使得不同平台的用户都能轻松使用 Ollama,无需担心平台兼容性问题.
总的来说,Ollama 通过其易用性、灵活性和高性能,为用户在本地部署和运行大型语言模型提供了一个优秀的解决方案,极大地降低了使用门槛,拓展了大型语言模型的应用范围。
2. 安装
* 需要科学上网
Ollama支持多种操作系统:macos、linux、windows。各个系统的安装方式如下:
- macos:
下载并安装:https://ollama.com/download/Ollama-darwin.zip
- linux:
curl -fsSL https://ollama.com/install.sh | sh- windows(10/11):
下载并安装:https://ollama.com/download/OllamaSetup.exe
安装完毕后,在命令行输入“ollama”或“ollama -h”能看到如下结果,则表明安装成功:
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
3. 基本使用
安装完毕后,可以通过ollama run XXX来下载并启动一个大模型,或者只pull不启动。我们以run为例,拉取一个qwen2.5大模型来做个测试。
PS: Qwen2.5模型在阿里巴巴最新的大规模数据集上进行预训练,该数据集包含高达18万亿个标记。该模型支持最多128,000个标记,并具有多语言支持功能。
启动模型(如果尚未拉取,则会自动拉取改模型到本地):
ollama run qwen2.5其他模型,比如deepseek,也可用类似方式拉取:
ollama run deepseek-r1:1.5b更多模型可参考:Ollama。
下面是与qwen2.5的一次简单对话:
>>> 你好
你好!有什么我可以帮助你的吗?
>>> 你是谁
我是Qwen,一个由阿里云开发的语言模型助手。我被设计用来提供信息、回答问题和协
助各种任务。有什么我可以帮忙的吗?
>>> 你能做什么
当然可以!我能够帮助你完成多种任务,包括但不限于:
1. **问答与知识查询**:我可以为你提供百科全书式的知识,帮助解答各类问题。
2. **撰写文本**:无论是文章、故事、信件还是其他类型的文本,都可以请你来帮忙
润色或创作。
3. **编程与技术咨询**:对于编程问题和技术咨询,我也可以提供支持和建议。
4. **学习辅助**:我可以解释复杂的概念,帮助你更好地理解课程内容。
5. **日常生活建议**:从旅行建议到健康小贴士,我可以提供一些建议。
请告诉我你需要什么帮助或想要了解的内容,我会尽力协助你!
>>> 使用C++写一个找质数的代码
当然可以!下面是一个用C++编写的简单程序,用于查找指定范围内的所有质数。我们
将实现一个函数 `isPrime` 来判断一个数是否是质数,并在主函数中打印出2到100之
间的所有质数。
```cpp
#include <iostream>
#include <cmath>
// 判断一个数是否为质数
bool isPrime(int num) {
if (num <= 1) return false; // 小于或等于1的不是质数
if (num == 2) return true; // 2是唯一的偶数质数
if (num % 2 == 0) return false; // 能被2整除的数不是质数
for (int i = 3; i <= sqrt(num); i += 2) {
if (num % i == 0)
return false;
}
return true;
}
// 打印指定范围内的所有质数
void printPrimes(int start, int end) {
std::cout << "Prime numbers between " << start << " and " << end << "
are: ";
for (int i = start; i <= end; ++i) {
if (isPrime(i)) {
std::cout << i << " ";
}
}
std::cout << std::endl;
}
int main() {
// 指定范围
int start = 2, end = 100;
// 打印指定范围内的所有质数
printPrimes(start, end);
return 0;
}
```
### 解释
1. **`isPrime` 函数**:
- 判断一个数是否为质数。
- 首先检查是否小于或等于1,如果是则返回 `false`。
- 检查是否为2(唯一的偶数质数),如果是则返回 `true`。
- 排除所有能被2整除的奇数。
- 从3开始逐个检查奇数因子,如果存在,则该数不是质数。
2. **`printPrimes` 函数**:
- 打印指定范围内的所有质数。
- 使用 `isPrime` 函数判断每个数是否为质数,并打印结果。
3. **主函数 (`main`)**:
- 指定查找的起始和结束范围(这里是2到100)。
- 调用 `printPrimes` 函数来输出结果。
你可以将这段代码复制到你的C++开发环境中运行,它会打印出2到100之间的所有质数
。如果你有任何其他需求或问题,请告诉我!
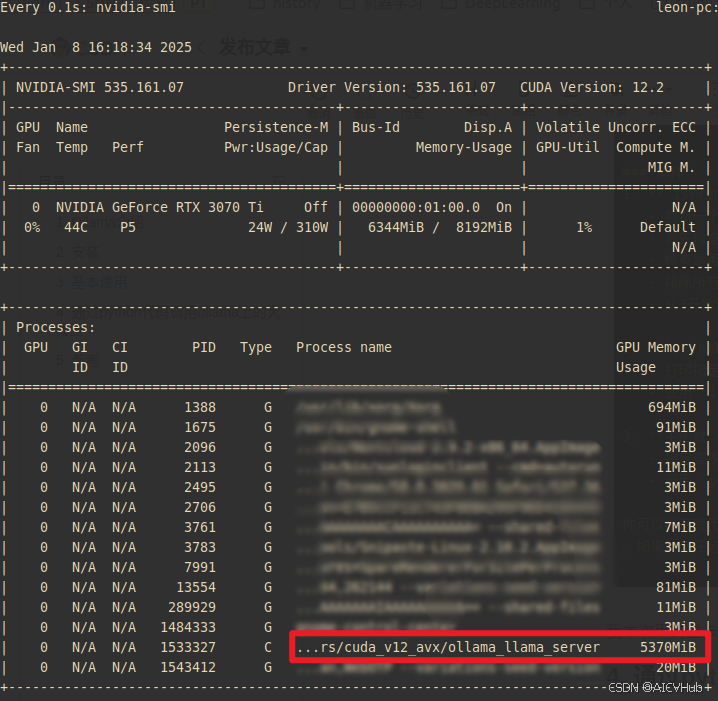
我本次用的显卡是3070Ti,实际使用发现速度停快的,几乎都是秒出结果。
其会自动利用本地的计算设备,从下面的图也能看到占了我5G+的显存:
4. 通过python代码调用ollama上的大模型
通过ollama将大模型拉取到本地后,还可以通过对应的python库来调用大模型,这样就可以实现将大模型集成到其他应用当中的目的了。
首先,在python环境中安装库:
pip install ollama然后,就可以写Python代码来调用大模型进行推理了(注意:里面的model参数用于指定你想要调用的模型名称):
from ollama import chat
from ollama import ChatResponse
response: ChatResponse = chat(model='qwen2.5', messages=[
{
'role': 'user',
'content': '天为什么是蓝色的?',
},
])
print(response['message']['content'])
# or access fields directly from the response object
print(response.message.content)上面是直接一次性响应,对于答案较长且需要实时响应的场景,我们需要启用流式响应。通过设置stream=True可以启用响应流:
from ollama import chat
stream = chat(
model='qwen2.5',
messages=[{'role': 'user', 'content': '天为什么是蓝色的?'}],
stream=True,
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)更多用法,可以参考:GitHub - ollama/ollama-python: Ollama Python library
5. 远程访问ollama
通常我们需要将ollama部署到一台服务器上,然后其他的电脑远程访问。这时,需要对服务器作一定的设置,因为默认的ollama服务只在本地可访问。
# 打开并编辑Ollama的systemd服务文件
# 1. 打开ia
sudo systemctl edit ollama.service
# 2. 添加如下内容; 注意,这一步需要在“### Anything between here and the comment below will become the contents of the drop-in file”下面,“### Edits below this comment will be discarded”前面
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
# 3. 重启服务
sudo systemctl daemon-reload
sudo systemctl restart ollama
# 4. 防火墙设置
sudo ufw allow 11434/tcp
经过上面步骤后,可以在其他电脑上通过访问“http://<Ubuntu服务器的IP地址>:11434
”来验证一下是否能够正常连接服务器。若出现“Ollama is running”字样,则表明OK。


















 2010
2010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











