







参考文章:文章转载自:易百教程 [http:/www.yiibai.com]
本文标题:Python 3开发网络爬虫
本文地址:http://www.yiibai.com/python/python3-webbug-series1.html
1、最简单的,用python抓取网页
import urllib.request
url="http://www.baidu.com"
data =urllib.request.urlopen(url).read()
data = data.decode("utf-8")
print (data)2、urlencode()
通过urllib.parse.urlencode()来将一个通俗的字符串, 转化为url格式的字符串。
urllib.parse.urlencode(query, doseq=False, safe=”, encoding=None, errors=None)
urllib.parse.quote_plus(string, safe=”, encoding=None, errors=None)
3、Python队列
在爬虫程序中, 用到了广度优先搜索(BFS)算法. 这个算法用到的数据结构就是队列.
Python的List功能已经足够完成队列的功能, 可以用 append() 来向队尾添加元素, 可以用类似数组的方式来获取队首元素, 可以用 pop(0) 来弹出队首元素. 但是List用来完成队列功能其实是低效率的, 因为List在队首使用 pop(0) 和 insert() 都是效率比较低的, Python官方建议使用collection.deque来高效的完成队列任务.
queue = deque([“”, “”, “”])
=>队列的增加也是用append(),移除使用popleft();
4、Python的集合
在爬虫程序中, 为了不重复爬那些已经爬过的网站, 我们需要把爬过的页面的url放进集合中, 在每一次要爬某一个url之前, 先看看集合里面是否已经存在. 如果已经存在, 我们就跳过这个url; 如果不存在, 我们先把url放入集合中, 然后再去爬这个页面.
Python提供了set这种数据结构. set是一种无序的, 不包含重复元素的结构. 一般用来测试是否已经包含了某元素, 或者用来对众多元素们去重. 与数学中的集合论同样, 他支持的运算有交, 并, 差, 对称差.
创建一个set可以用 set() 函数或者花括号 {} . 但是创建一个空集是不能使用一个花括号的, 只能用 set() 函数. 因为一个空的花括号创建的是一个字典数据结构. 以下同样是Python官网提供的示例.
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # 这里演示的是去重功能
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # 快速判断元素是否在集合内
True
>>> 'crabgrass' in basket
False>>> # 下面展示两个集合间的运算.
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含元素
{'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素
{'a', 'c'}
>>> a ^ b # 不同时包含于a和b的元素
{'r', 'd', 'b', 'm', 'z', 'l'5、附上自己写的抓取网页图片的代码
没有优化过,初学者,只是基本实现了功能。
获取某个网站的图片,并且可以翻到下一个获取图片,我用来下漫画了。因为不需要登录,就没做登录的了
import urllib.request
import urllib.parse
import urllib
import re
import os
import http.cookiejar
def makeMyOpener(head = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}):
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key,value in head.items():
elem = (key,value)
header.append(elem)
opener.addheaders = header
return opener
def getItemUrl(data):
retext=re.compile('<div class=\"camLiTitleC hot\"><b><a href=\"(.*)\" title')
m=retext.findall(data)
return m
def getImgSrc(data):
imgSrc=re.findall(r'class=\"mb10\" src=\"(.*)\" alt',data)
return imgSrc
def saveImg(url,filename,num):
web = urllib.request.urlopen(url)
jpg = web.read()
DstDir = "E:\\manhua\\" + str(num) +"\\"
if not os.path.isdir(DstDir):
os.mkdir(DstDir)
try:
f = open(DstDir + filename,"wb")
f.write(jpg)
f.flush()
f.close()
return
except IOError:
print("io error \n")
return
except Exception:
print("error \n")
return
def getPageUrl(data):
pageRe = re.compile('<a href=\'(.*)\' btnmode=\'true\' hideFocus>')
pageList = pageRe.findall(data)
return pageList
oper = makeMyOpener()
url="输入网址"
url_main='输入网址'
try:
data = oper.open(url,timeout = 1000).read()
data = data.decode("utf-8")
except Exception:
pribt('error \n')
i = 0
n = 1
pageList = getPageUrl(data)
for pageItem in pageList:
pageUrl = url_main + pageItem
thePage = urllib.request.urlopen(pageUrl).read().decode("utf-8")
listUrl = getItemUrl(thePage)
for itemUrl in listUrl:
itemData = urllib.request.urlopen(itemUrl).read()
itemData = itemData.decode("utf-8")
imgList = getImgSrc(itemData)
for imgItem in imgList:
saveImg(imgItem,str(i) + ".jpg",n)
i = i + 1
print('one image')
n=n+1
print('one page')
print('finish')
运行过程中发现出了一个异常,顺带记录一下IncompleteRead
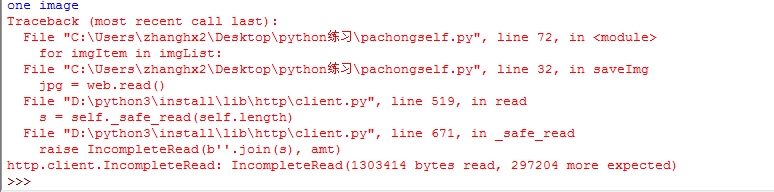
查了资料:http://www.wl566.com/biancheng/146535.html
摘抄记录:
1、 这个异常表示client端期待从HTTP body 中读取A 字节,但实际能够读取的字节数小于A个字节
HTTP Response 的Header 大致如下:
{‘connection’: ‘keep-alive’, ‘content-type’: ‘application/json’, ‘content-length’: ‘44668’, ‘content-encoding’: ‘gzip’}
可以判断Response body完整传输(safe transport)的要素是 content-length,也就是实际读到的body体的长度小于content_length
2、重现几率不定。
IncompleteRead 任务结束后2天,重新执行此脚本,发现跑多少遍,都没有再抛出异常
3、重试,异常没有重现这推断我们的代码应该是没有问题的。所能读取的字节长度基本固定,我推断有可能是某个硬件设备,网卡或者交换机路由器达到了服务能力上限,导致异常的中断,从而抛出IncompleteRead。只要在代码逻辑中加入重试机制即可。















 3163
3163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









