







自 ChatGPT 发布以来,大型语言模型(Large Language Model,LLM,大模型)得到了飞速发展,它在处理复杂任务、增强自然语言理解和生成类人文本等方面的能力让人惊叹,几乎各行各业均可从中获益。
然而,在一些垂直领域,这些开源或闭源的通用基础大模型也暴露了一些问题,主要体现在以下 3 个方面:
- 知识的局限性: 大模型的知识源于训练数据,目前主流大模型(如:通义千问、文心一言等)的训练数据基本来源于网络公开的数据。因此,非公开的、离线的、实时的数据大模型是无法获取到(如:团队内部实时业务数据、私有的文档资料等),这些数据相关的知识也就无从具备。
- 幻觉问题: 大模型生成人类文本底层原理是基于概率(目前还无法证明大模型有意识),所以它有时候会一本正经地胡说八道,特别是在不具备某方面的知识情况下。当我们也因缺乏这方面知识而咨询大模型时,大模型的幻觉问题会各我们造成很多困扰,因为我们也无法区分其输出的正确性。
- 数据的安全性: 对于个人、创新团队、企业来说,数据安全至关重要,老牛同学相信没有谁会愿意承担数据泄露的风险,把自己内部私有数据上传到第三方平台进行模型训练。这是一个矛盾:我们既要借助通用大模型能力,又要保障数据的安全性!
为了解决以上通用大模型问题,检索增强生成(Retrieval-Augmented Generation,RAG)方案就应运而生了:
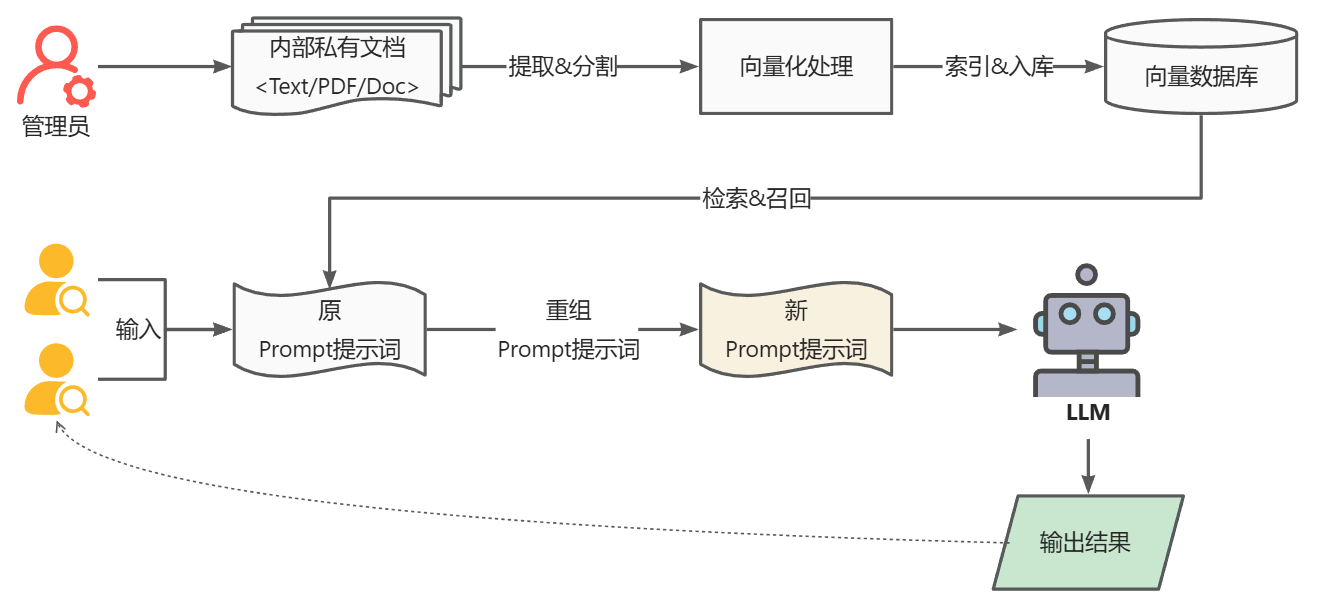
RAG 的主要流程主要包含以下 2 个阶段:
- 数据准备阶段: 管理员将内部私有数据向量化后入库的过程,向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果;入库即将向量数据构建索引,并存储到向量数据库的过程。
- 用户应用阶段: 根据用户的 Prompt 提示词,通过检索召回与 Prompt 提示词相关联的知识,并融入到原 Prompt 提示词中,作为大模型的输入 Prompt 提示词,通用大模型因此生成相应的输出。
从上面 RAG 方案我们可以看出,通过与通用大模型相结合,我们可搭建团队私有的内部本地知识库,并能有效的解决通用大模型存在的知识局限性、幻觉问题和隐私数据安全等问题。
目前市面上已经有多个开源 RAG 框架,老牛同学将选择AnythingLLM框架(16.8K ☆,https://github.com/Mintplex-Labs/anything-llm)与大家一起来部署我们自己或者团队内部的本地知识库。整个部署过程将涉及以下几个方面:
- 环境准备: AnythingLLM框架推荐使用 Docker 部署,因此我们需要提前把 Docker 安装和配置好
- 大模型准备: 老牛同学继续使用Qwen2-7B大模型,大家可以根据自己实际情况选择,无特殊要求
- RAG 部署和使用: 即 AnythingLLM 安装和配置,并最终使用我们大家的 RAG 系统
环境准备:Windows 打开虚拟化功能(Hyper-V 和 WSL)
友情提示: 老牛同学用的是 Windows 操作系统,因此下面是 Windows 的配置方式。
安装 Docker 需要用到虚拟化,因此需要 Windows 系统打开Hyper-V和WSL 子系统功能。如果是 Windows 11 家庭版,默认并没有安装Hyper-V功能,可以通过以下方式进行安装:
【第一步(家庭版):安装 Hyper-V 依赖包】
- 新建一个 txt 临时文本,并复制以下代码并保存,之后把该临时文件重命名为
Hyper-V.bat - 右键以管理员方式运行
Hyper-V.bat,本代码自动安装相关包,完成之后输入Y重启电脑后即可
pushd "%~dp0"
dir /b %SystemRoot% 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2945
2945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









