






Label Encoding:
假如颜色就是一个特征,该特征的取值有三种:红、黄、蓝,
对于标签编码,就是令 红=1,黄=2,蓝=3,即给不同类别以标签
但这并不是我们的让机器学习的本意,只是想让机器区分它们,并无大小比较之意。所以这时标签编码是不够的,需要进一步转换
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit([1,10,88,100])
le.transform([1,1,100,88,10])
输出: array([0,0,3,2,1])
逆过程:
list(le.inverse_transform([2, 2, 1]))
输出:[88, 88, 10]
One-hot编码:
One-hot编码解决了标签编码存在的问题。
假如颜色就是一个特征,该特征的取值有三种:红、黄、蓝,
One-not编码为:红色:1 0 0 ,黄色: 0 1 0,蓝色:0 0 1
以向量编码特征取值,向量维度就是特征不同取值的个数。
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]) # fit来学习编码
enc.transform([[0, 1, 3]]).toarray() # 进行编码
``
输出:array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]])`
数据矩阵是4*3,即4个数据,3个特征维度。
|0|0|3|
|1|1|0|
|0|2|1|
|1|0|2|
第一列特征有两个值,所以0:01, 1:10.
第二列特征3个值,0:100, 1:010,1:001
第三列特征4个值,0:1000, 1:0100, 2:0010, 3:0001
优点:独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
缺点:当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA来减少维度。而且one hot encoding+PCA这种组合在实际中也非常有用。
One-hot编码用来解决类别型数据的离散值问题,
将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码。 有些基于树的算法在处理变量时,并不是基于向量空间度量,数值只是个类别符号,即没有偏序关系,所以不用进行独热编码。 Tree Model不太需要one-hot编码: 对于决策树来说,one-hot的本质是增加树的深度。
频数编码(count encoding)
频数编码使用频次替换类别,频次根据训练集计算。这个方法对离群值很敏感,所以结果可以归一化或者转换一下(例如使用对数变换)。未知类别可以替换为1。
AskReddit 221941
politics 98233
news 33559
worldnews 32010
gaming 25567
Name: subreddit, dtype: int64
第一列为属性,第二列为属性的值出现的频次
是以哦那个频数编码后:
221941 221941
98233 98233
33559 33559
32010 32010
25567 25567
Name: subreddit_count_encoded, dtype: int64
基本上,用频次替换了类别。我们也可以除以最频繁出现的类别的频次,以得到归一化的值:
1.000000 221941
0.442609 98233
0.151207 33559
0.144228 32010
0.115197 25567
Name: subreddit_count_encoded_normalized, dtype: int64
LabelCount编码
LabelCount编码分两步:
- 对属性的取值,使用各自的频次进行排序,或者降序,或者升序;
- 对排序好的属性,使用label Encoding 进行编码。
例如上面的例子可以变为:
0 221941
1 98233
2 33559
3 32010
4 25567
Name: subreddit_labelcount_encoded_descending, dtype: int64
目标编码
也称均值编码,相对其他编码要复杂一些。
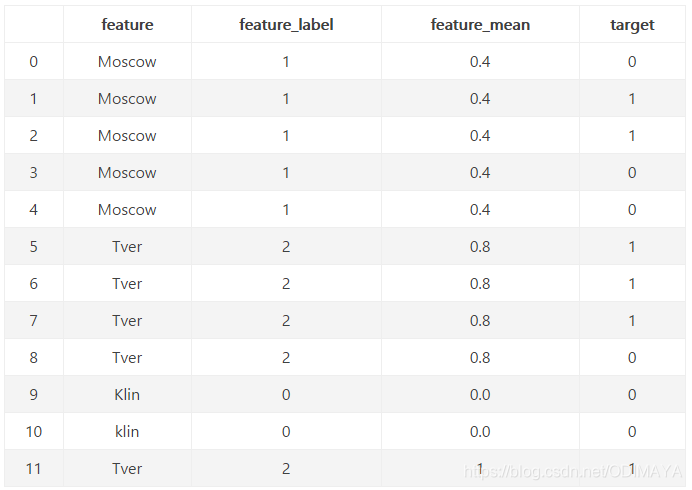
对feature变量进行编码,第二列为标签编码,第三类为目标编码。
目标编码用每个城市自身对应的目标均值来进行编码。例如,对于Moscow,我们有五行,三个0和两个1。 所以我们用2除以5或0.4对它进行编码。用同样的方法处理其他城市。
pandas例子:
means= X_tr.groupby(col).target.mean()
train_new[col+'_mean_target'] = train_new[col].map(means)
val_new[col+'_mean_target'] = val_new[col].map(means)
改进方法:
改进方法有很多,在注中介绍了几种。
细说一种:kflod
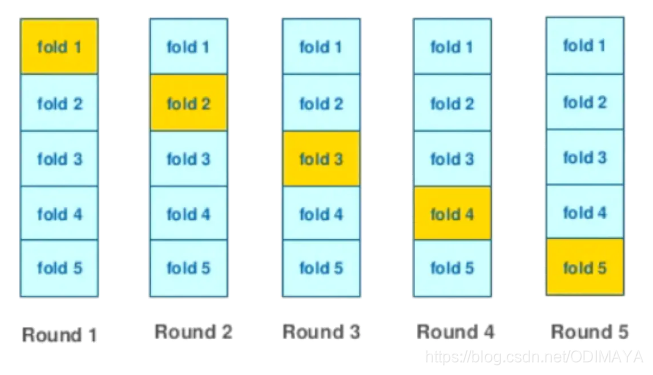

思路:
- 首先将数据分为训练集和测试集;
- 先将训练数据做kflod;
- 对于每次的分割,用分割出来的训练集来进行目标编码,然后在验证集上使用,并把验证集保存为新的编码数据;
- 对于上述的每折数据都这个处理后,所有的新的编码后的验证集组合起来,就是新的编码好的数据了。
- 对于使用训练集编码好的数据,在使用机器学习模型的时候,直接用编码好的数据,对测试数据中的需要编码的数据,直接进行替换组合,即可。
- 测试集中的数据不能参与编码过程,只能使用训练集编号的编码字典来直接使用。
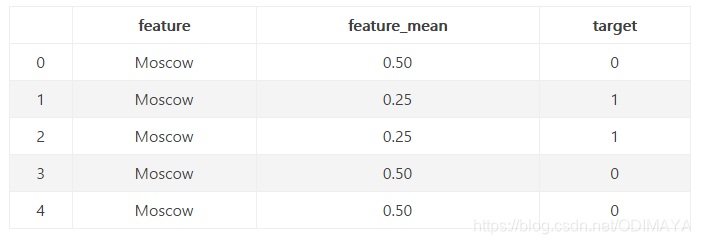
例子:
一共5个数据,分的时候为5-flod。
对于第一行,我们得到0.5,因为有两个1和 其余行中有两个0。 同样,对于第二行,我们得到0.25,依此类推。 但仔细观察,所有结果和由此产生的特征。 它完美地分割数据,具有等于或等的特征的行 大于0.5的目标为0,其余行的目标为1。 我们没有明确使用目标变量,但我们的编码是有偏置的。
注:
使用目标编码时,非常重要的一点是不要泄露任何验证集的信息。所有基于目标编码的特征都应该在训练集上计算,接着仅仅合并或连接验证集和测试集。即使验证集中有目标变量,它不能用于任何编码计算,否则会给出过于乐观的验证误差估计。
如果使用K折交叉验证,基于目标的特征应该在折内计算。如果仅仅进行单次分割,那么目标编码应该在分开训练集和验证集之后进行。
此外,我们可以通过平滑避免将特定类别编码为0. 另一种方法是通过增加随机噪声避免可能的过拟合。
处置妥当的情况下,无论是线性模型,还是非线性模型,目标编码都是最佳的编码方式。
参考:
https://www.jianshu.com/p/35d199b47ca4
https://blog.csdn.net/weixin_39671140/article/details/84801409














 4718
4718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









