







1.torch.scatter
这是out-of-place版本(相对于in-place版本),它会返回一个新的张量。
torch.Tensor.scatter_ 就是in-place版本,它直接修改自身,返回的也是自身
Tensor.scatter_(dim, index, src, *, reduce=None) → Tensor
import torch
if __name__ == '__main__':
index = torch.tensor([[0], [1]])
value = 2
a = torch.zeros(3, 5)
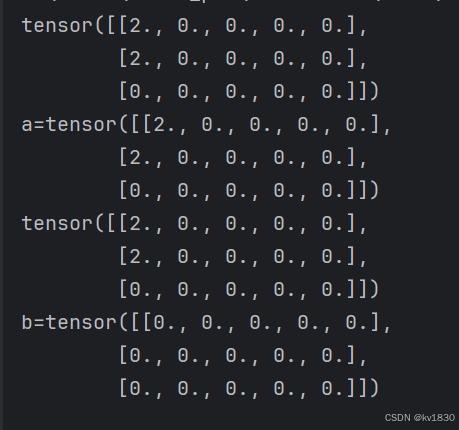
print(a.scatter_(0, index, value))
print(f'a={a}')
b = torch.zeros(3, 5)
print(torch.scatter(b, 0, index, value))
print(f'b={b}')比如上面这段代码,a被修改了,b就没被修改。
另外, Tensor也有out-of-place的版本,它自己就是input,但不会修改它自己,返回一个新张量。

Tensor.scatter_官方文档如下:
https://pytorch.org/docs/stable/generated/torch.Tensor.scatter_.html#torch.Tensor.scatter_
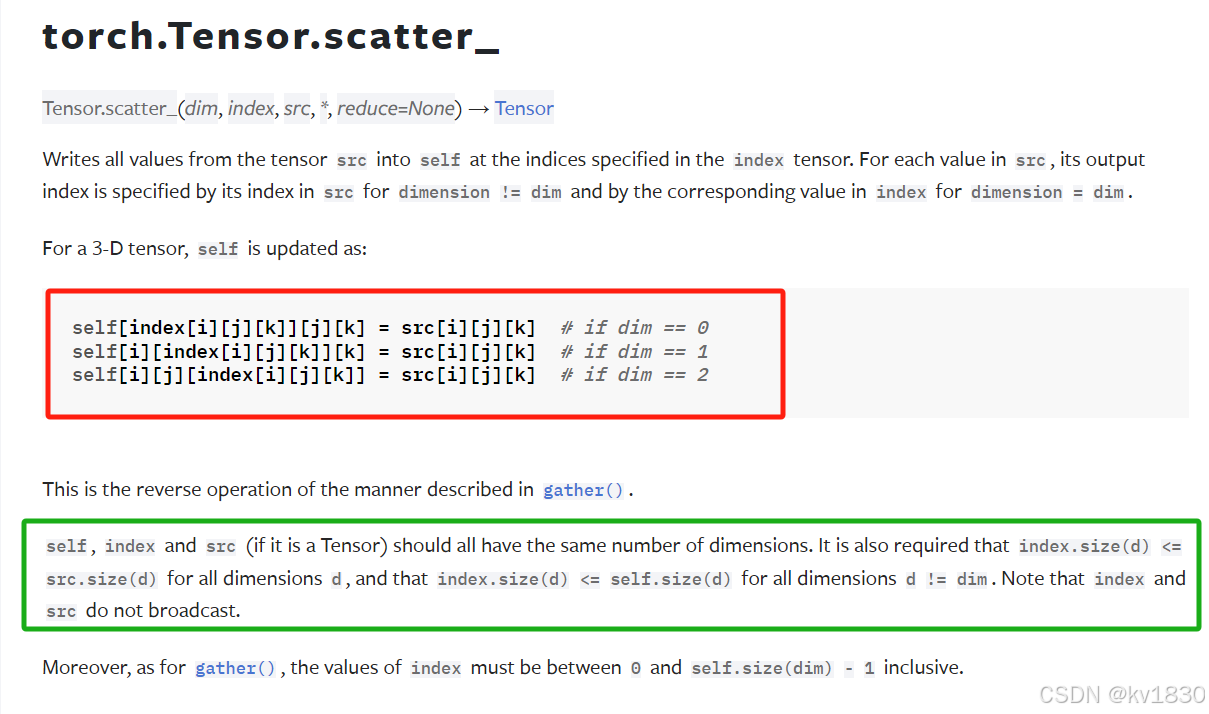
关键就是红框里面的这个式子,但是这i、j、k到底是怎么取值的,似乎不太容易理解,另外绿框中还给了一些维度关系,为什么要这么定?
其实最关键的就是scatter这个词的含义:撒。撒播。
往哪撒?撒什么?如下图,把src张量上的各元素撒到self上(对于torch.Tensor.scatter_来说是self,对于torch.scatter就是返回的新张量)。
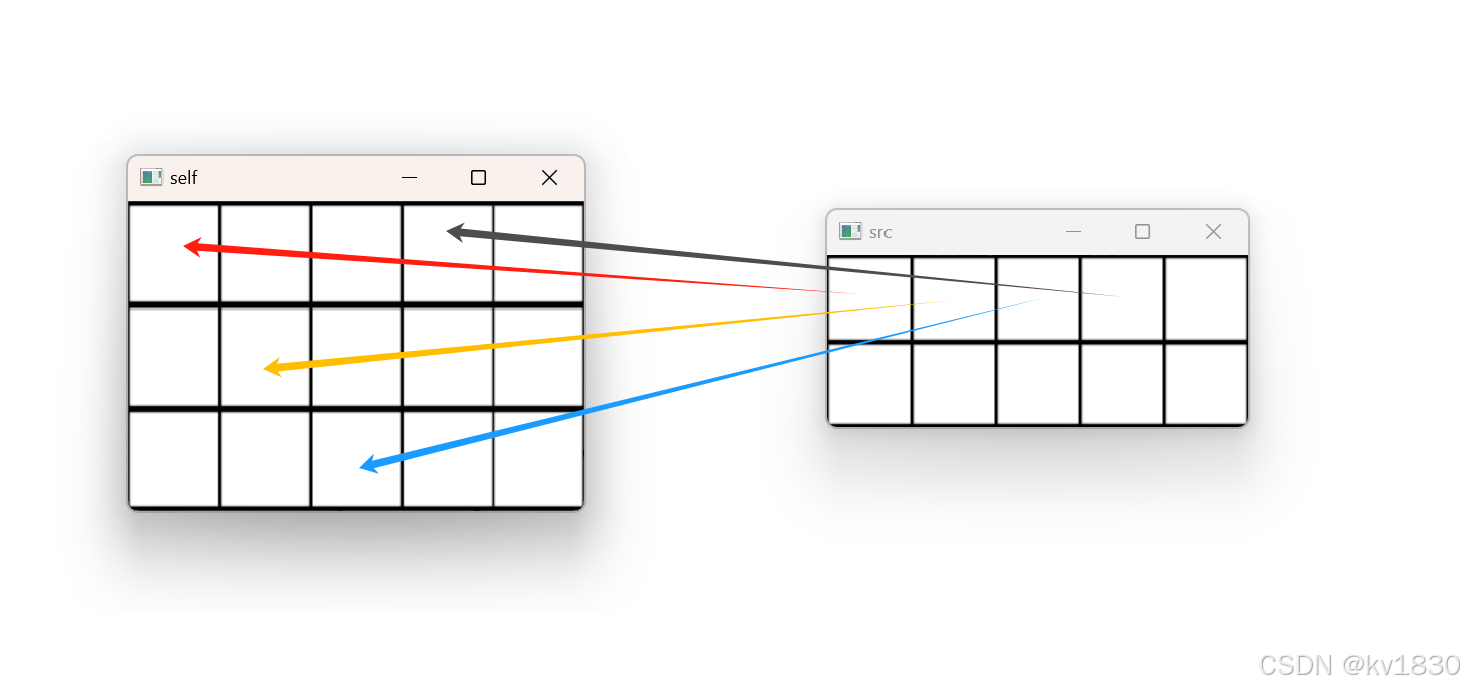
接下来就是,怎么撒?
其实上图就是之前pytorch文档中的一个例子,我们就围绕这个例子来说,如下图。

注意如上图红线处,我们指定的dim为0,下面会讲这个dim怎么用。
现在多了一个index,我们逐个遍历src上的每一个元素(暂且先这么认为。后面我们会发现,其实遍历的主角是index)。第0行第0列,src(0,0)值为1,那应该撒到self的哪里?
我们直接去index里找答案,取index(0,0)的值,index(0,0)值为0。由于上面我们指定的dim为0,所以index(0,0)的值就是self的第0维的坐标,也就是说我们要撒到的地方为:self[0, j],j是多少?在src中j是多少,它就是多少。所以说要撒到self[0,0]。
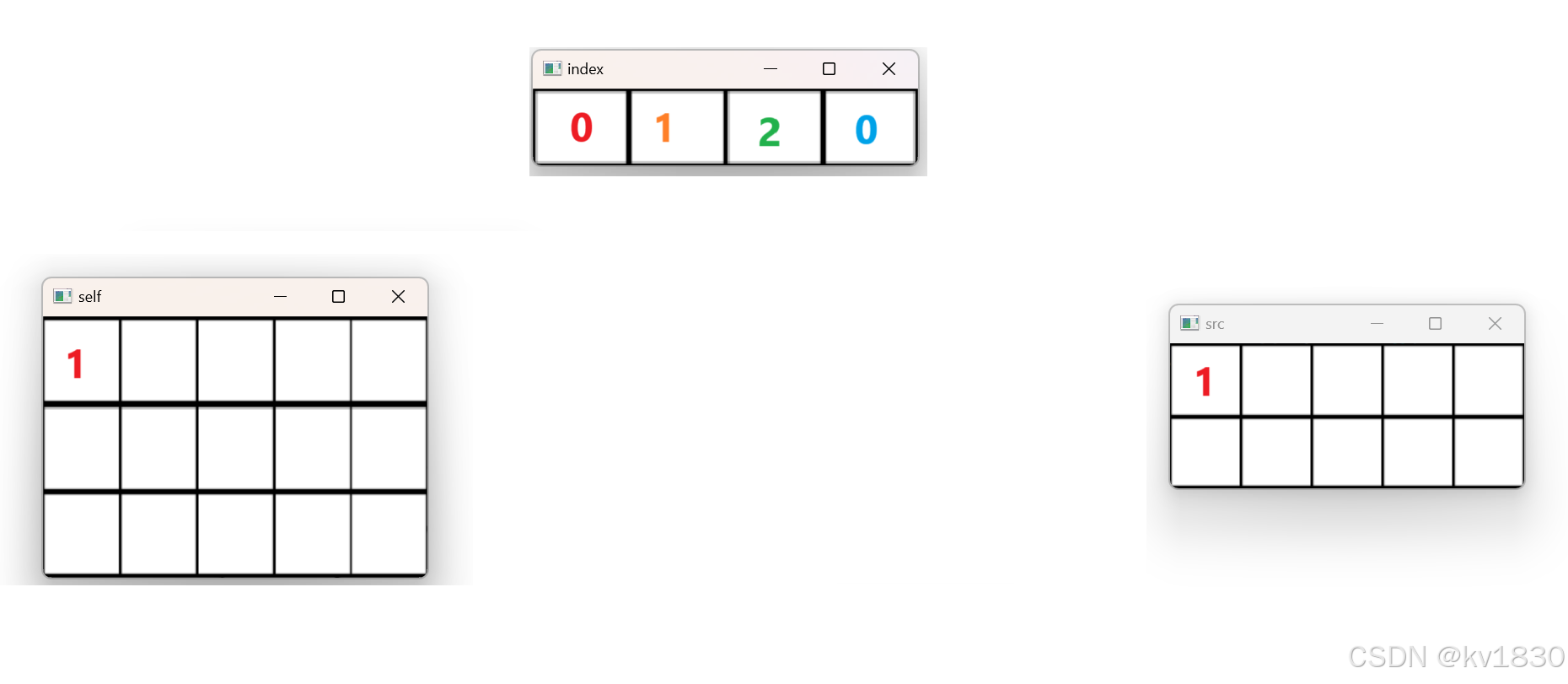
我把文档里那个式子再抄一遍,是不是就理解了!
 接下来,取src[0,1]值为2,index[0,1]值为1,所以应该撒到self[index[0,1],1]即self[1,1]
接下来,取src[0,1]值为2,index[0,1]值为1,所以应该撒到self[index[0,1],1]即self[1,1]
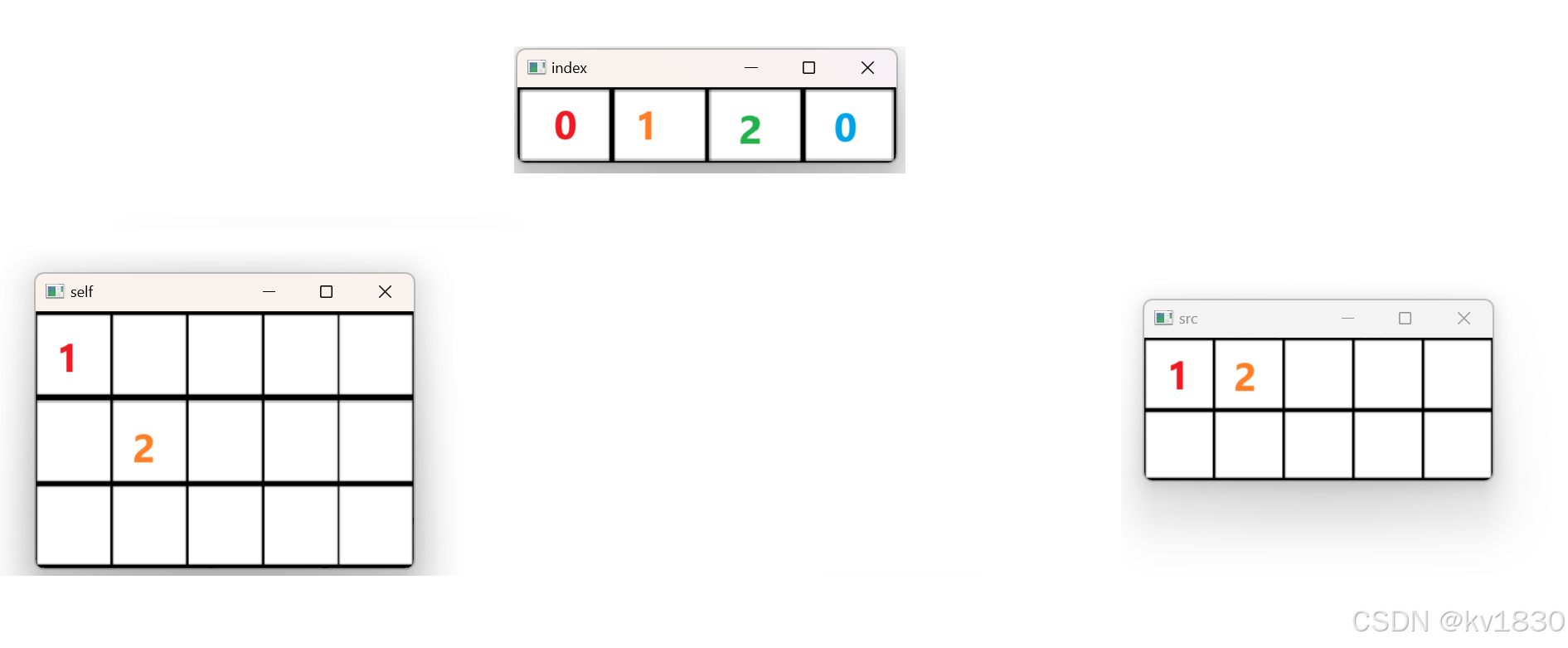
继续,src[0,2]值为3,index[0,2]值为2,故撒到self[index[0,2],2]即self[2,2]
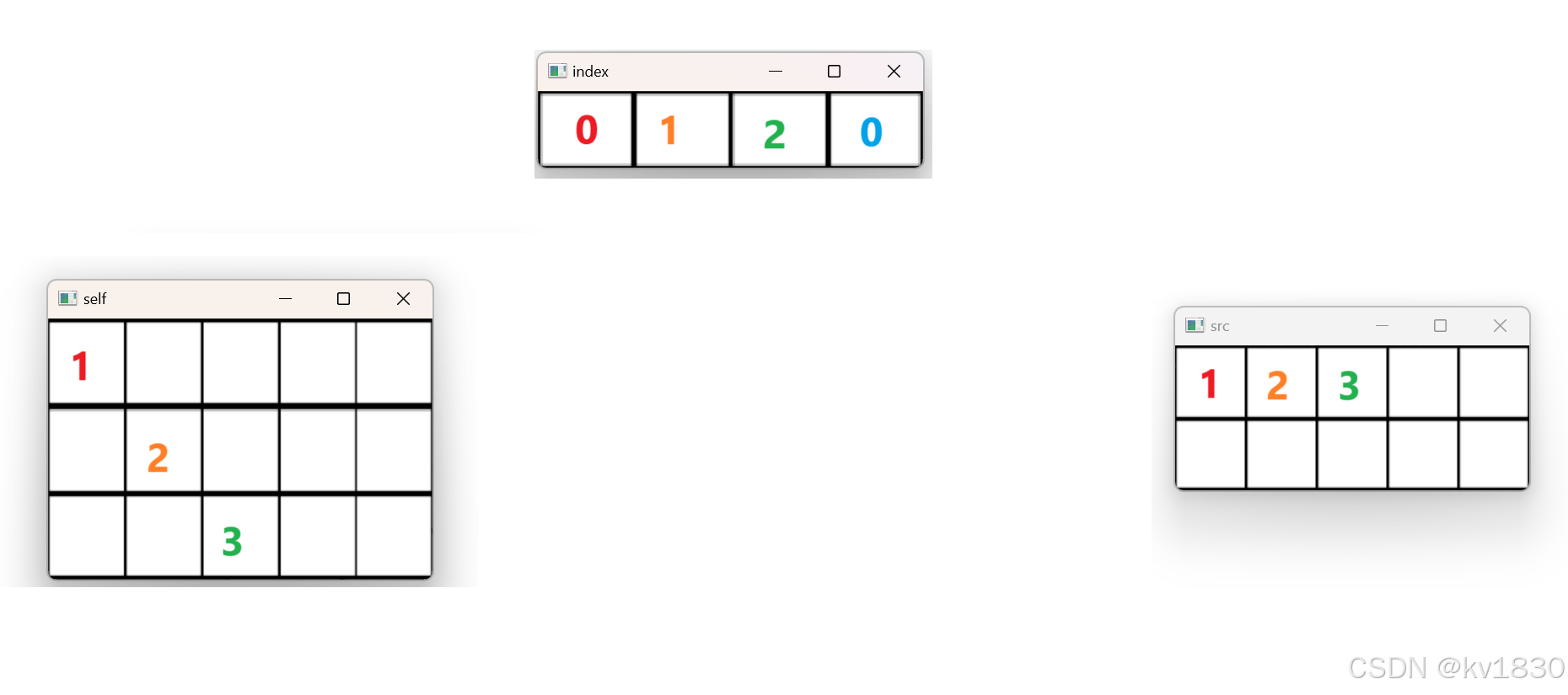
继续,src[0,3],文字略,见下图。
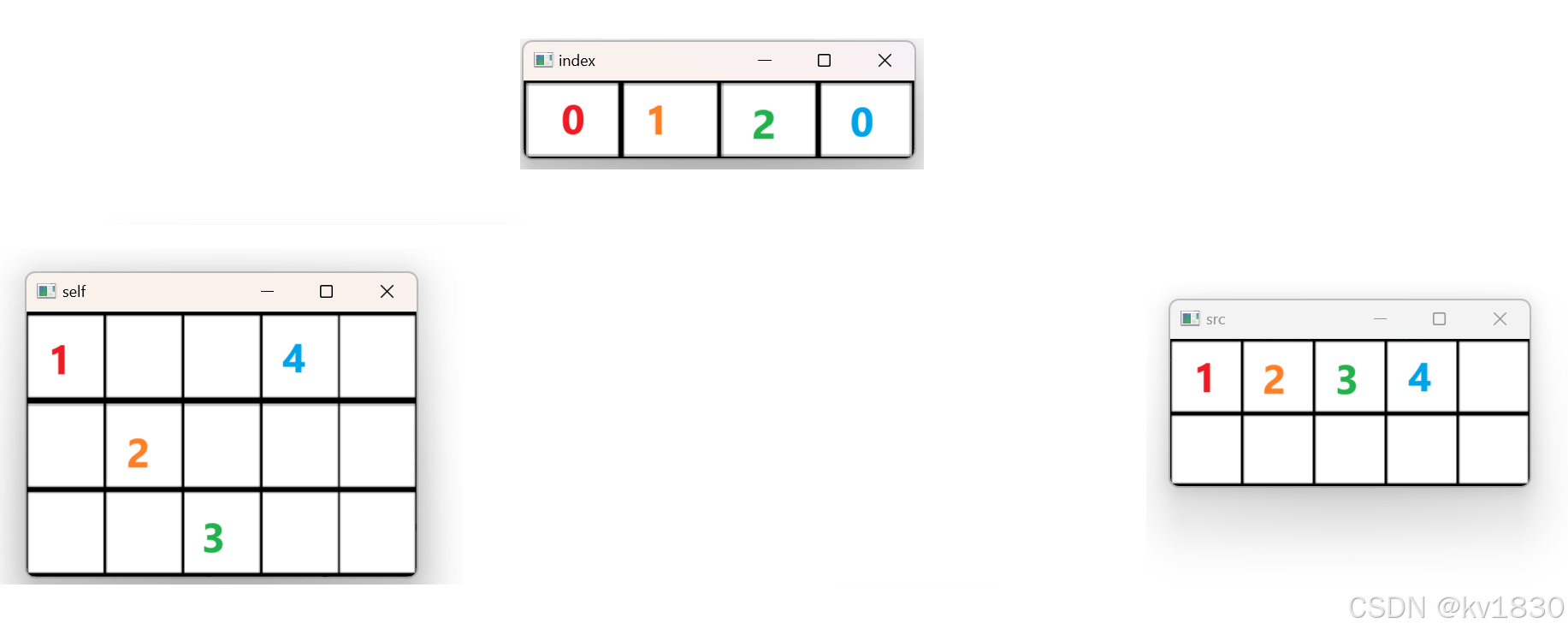
接下来,src[0,4]?没有index[0,4],所以这个不用撒。
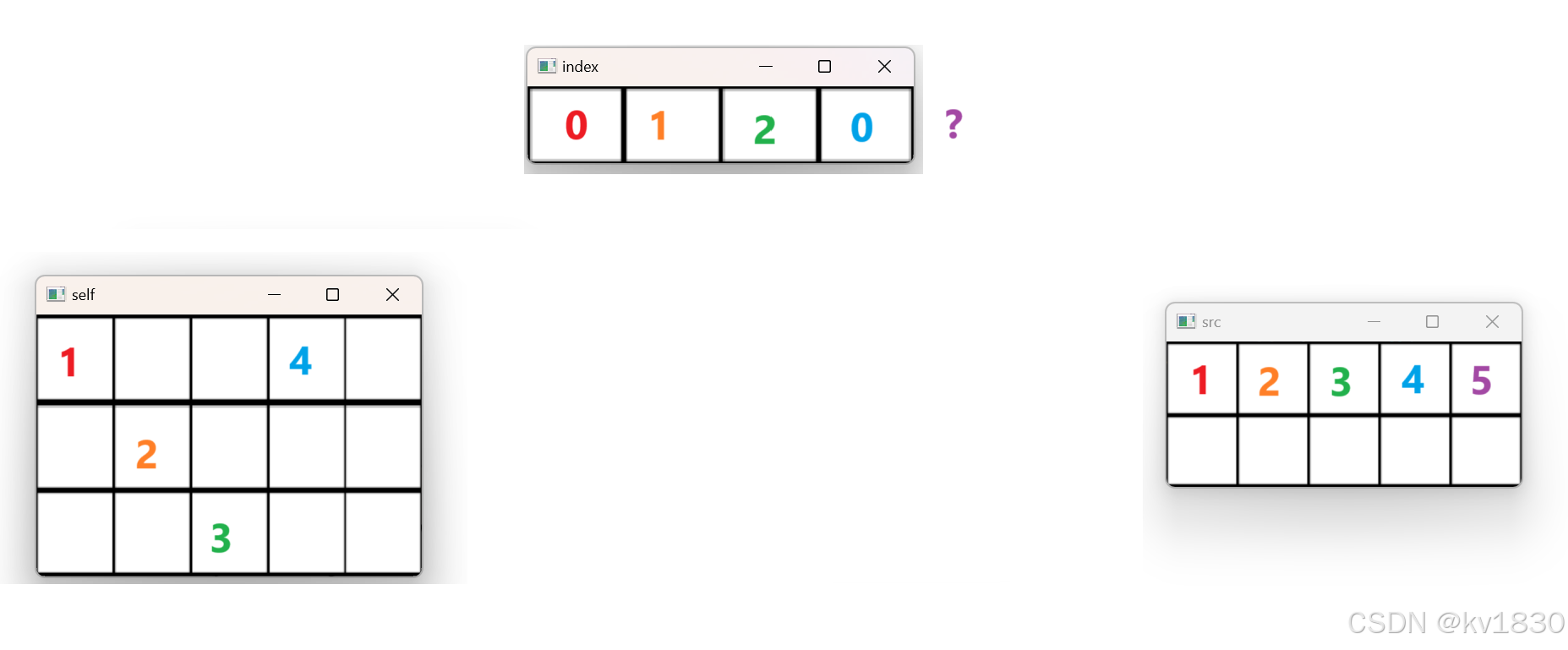
那src[1,0]?也没有index[1,0],index就没有这一行,这一行都不用再看啦,已经完全结束了。

至于例子中下面两处,红线是指定dim为1,也就是说用的是这个公式:
out[i][j][k] = input[i][index[i][j][k]][k] # if dim == 1
不再赘述了,可以自行演练一遍。
而绿线处指定了reduce策略,它就是不直接撒上去,而是和self中的元素相乘或者相加。
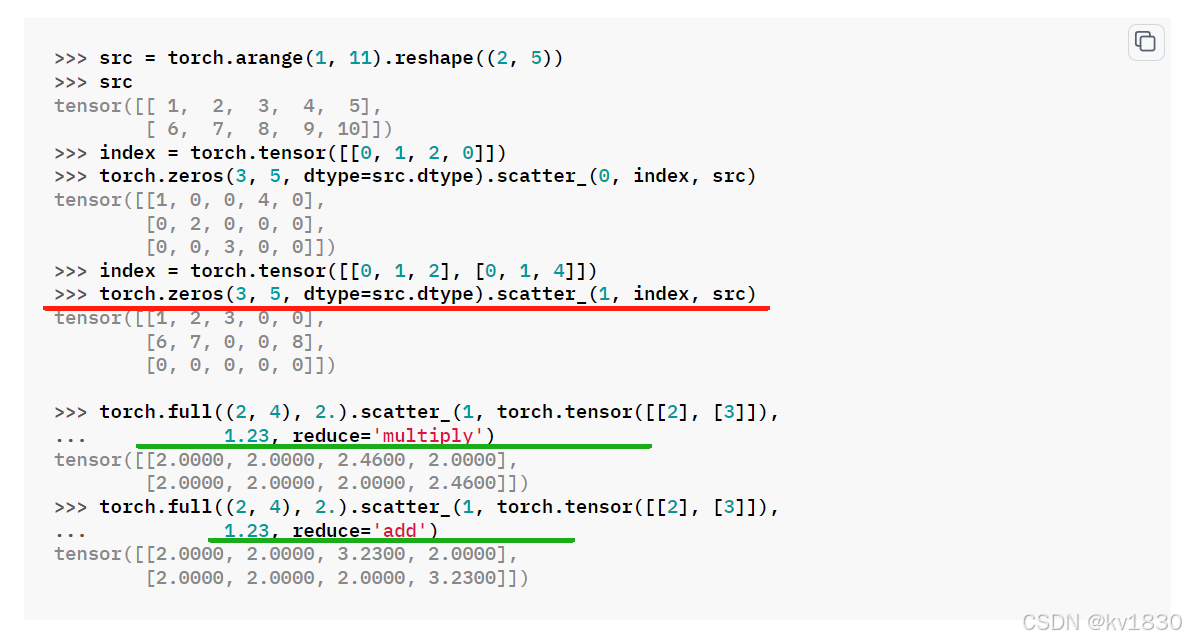
接下来我们再看一下文档中的维度约束,红线说index每一维的长度都不能超过src,这个直观理解其实也很简单,正如上面的例子所演示的,src的东西不需要都撒到self上,这由index的各维度范围来定,但是如果index某维度长度超过了src,这就没有意义了。所以从这个角度上来考虑,我们似乎遍历的并不是src,而是index,它才是主角。
 绿线处是说index各维度长度也不能超过self,但是dim指定的那个维度除外!前半句好理解,跟index不超过src是一样的道理,或者说某维度src==index>self,并且这个维度不是dim,那在self上不就越界了吗。那等于dim的那一维,为什么能超过self呢?我暂时想到一个没啥意义的例子:
绿线处是说index各维度长度也不能超过self,但是dim指定的那个维度除外!前半句好理解,跟index不超过src是一样的道理,或者说某维度src==index>self,并且这个维度不是dim,那在self上不就越界了吗。那等于dim的那一维,为什么能超过self呢?我暂时想到一个没啥意义的例子:
import torch
if __name__ == '__main__':
src = torch.arange(1, 9).reshape((4, 2))
index = torch.tensor([[0, 0], [0, 0], [1, 1], [1, 1]])
a = torch.zeros((2, 2), dtype=src.dtype)
print(a.scatter_(0, index, src))运行结果是:
tensor([[3, 4],
[7, 8]])
撒播路径如下图,但是这其实既没意义,又有问题。。。,因为我不是真的只撒了4个值,我8个直都撒了,只不过1,2,5,6被覆盖了而已。
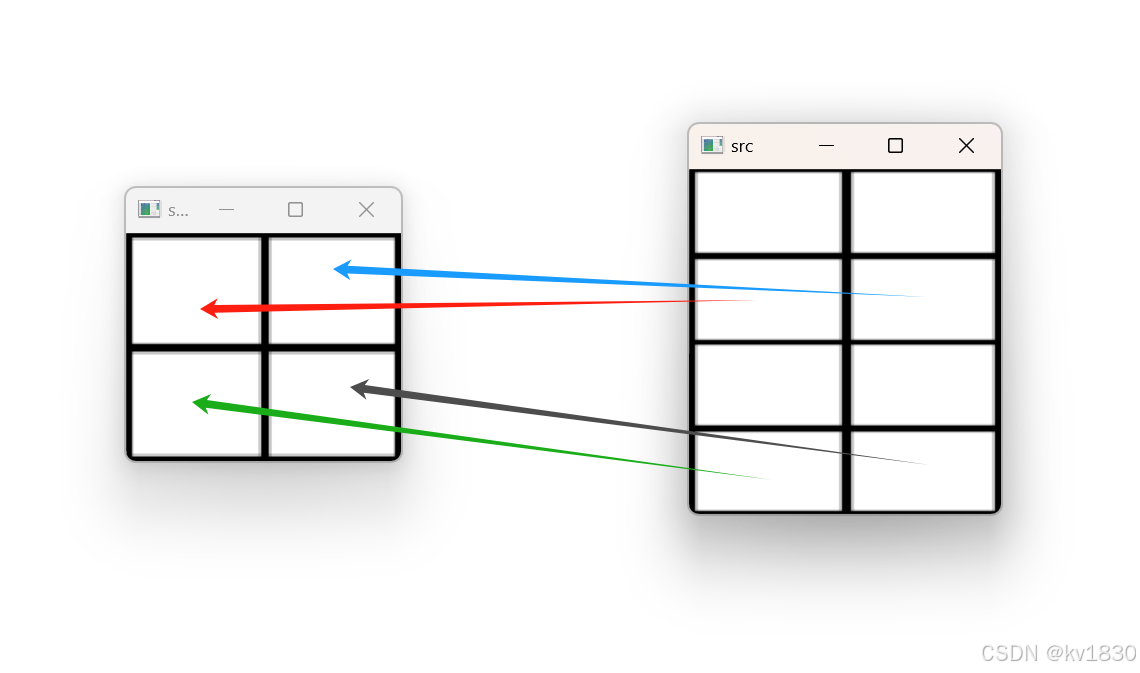
正好这里再提一下文档中的警告,别把多个值撒到同一处!其结果不是不确定的,并且梯度计算也会出错。另外,只有在src和index的形状完全相同时,才能进行正确的梯度计算。
 那问题来了,我如下想像下面这样撒,scatter好像做不到啊?其实这根本不是个问题,因为所谓撒,哪有越撒越集中的~~,你这个不是撒,是收集、聚集,所以应该用gather!
那问题来了,我如下想像下面这样撒,scatter好像做不到啊?其实这根本不是个问题,因为所谓撒,哪有越撒越集中的~~,你这个不是撒,是收集、聚集,所以应该用gather!
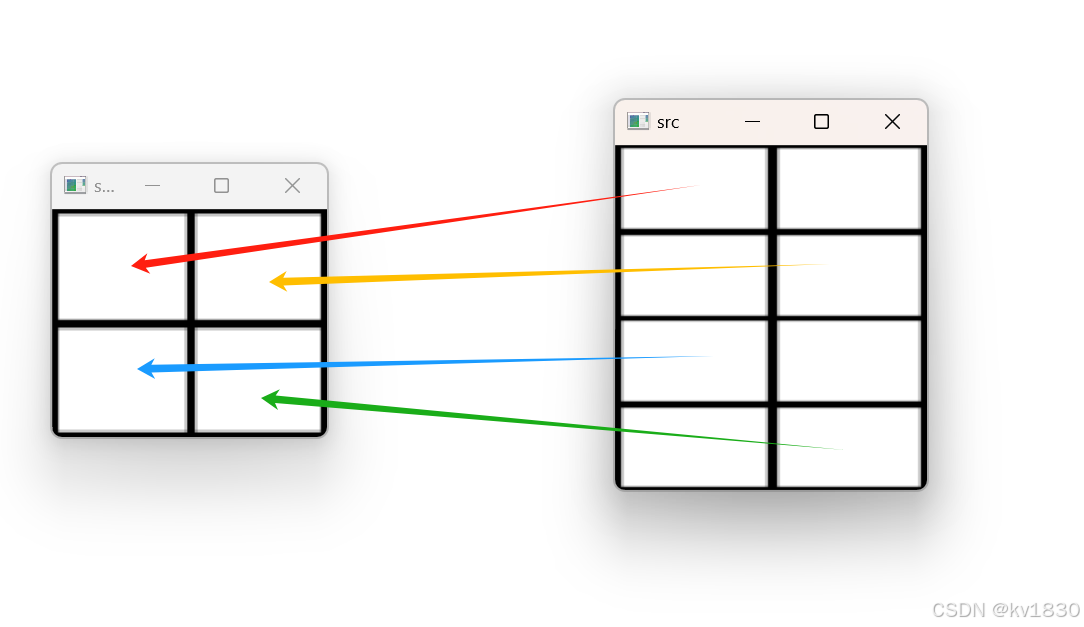
在说gather之前,scatter还有一种形式,如下:
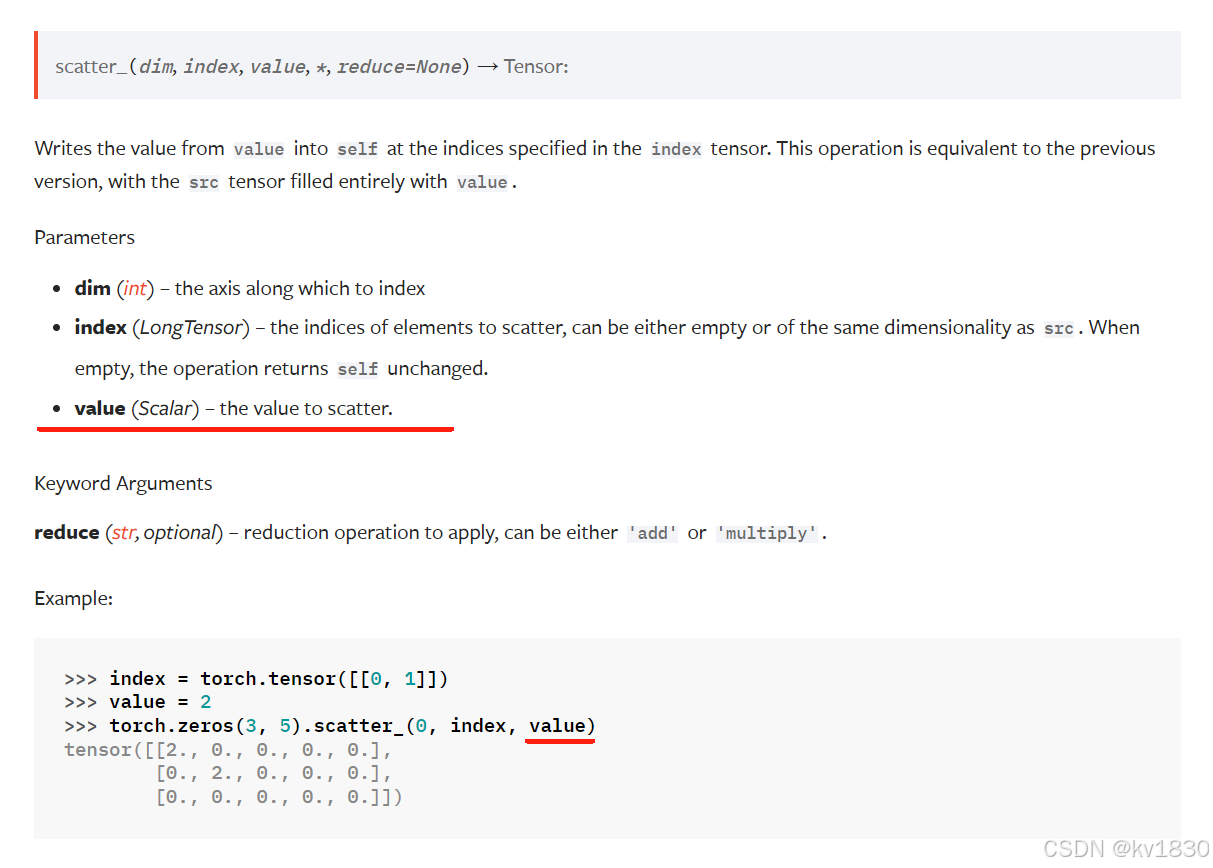 不再用src那个张量,而是改成了一个标量value,其实跟原来是一个道理,你可以认为有一个跟index形状完全相同的张量,每个元素都是value。而且从这个形式上来看,遍历的主角就是index。
不再用src那个张量,而是改成了一个标量value,其实跟原来是一个道理,你可以认为有一个跟index形状完全相同的张量,每个元素都是value。而且从这个形式上来看,遍历的主角就是index。
2.torch.gather
也有两种形式:
Tensor.gather(dim, index) → Tensor
torch.gather(input, dim, index, *, sparse_grad=False, out=None) → Tensor
但是这两种都是out-of-place的,前者自己就是input,返回一个gather后的新张量。
文档全部内容如下:
torch.gather — PyTorch 2.5 documentation
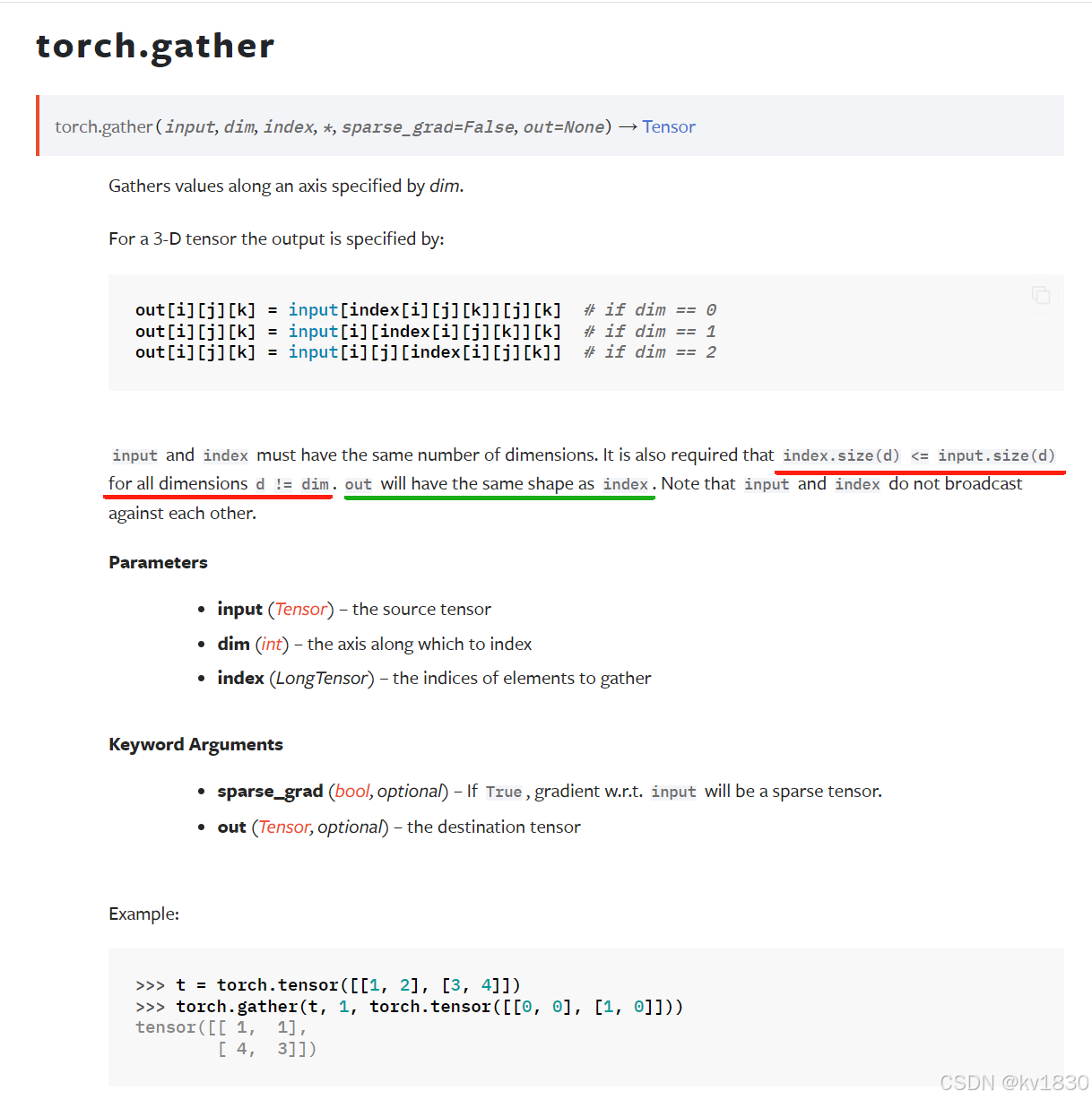
其实gather就是scatter的逆操作 ,我们就以torch.gather(input, dim, index)这个形式为例,它返回的新张量假设为output,它其实就是由index指示,把input上的元素收集到output上。
我们先把最初的scatter例图再看一下:
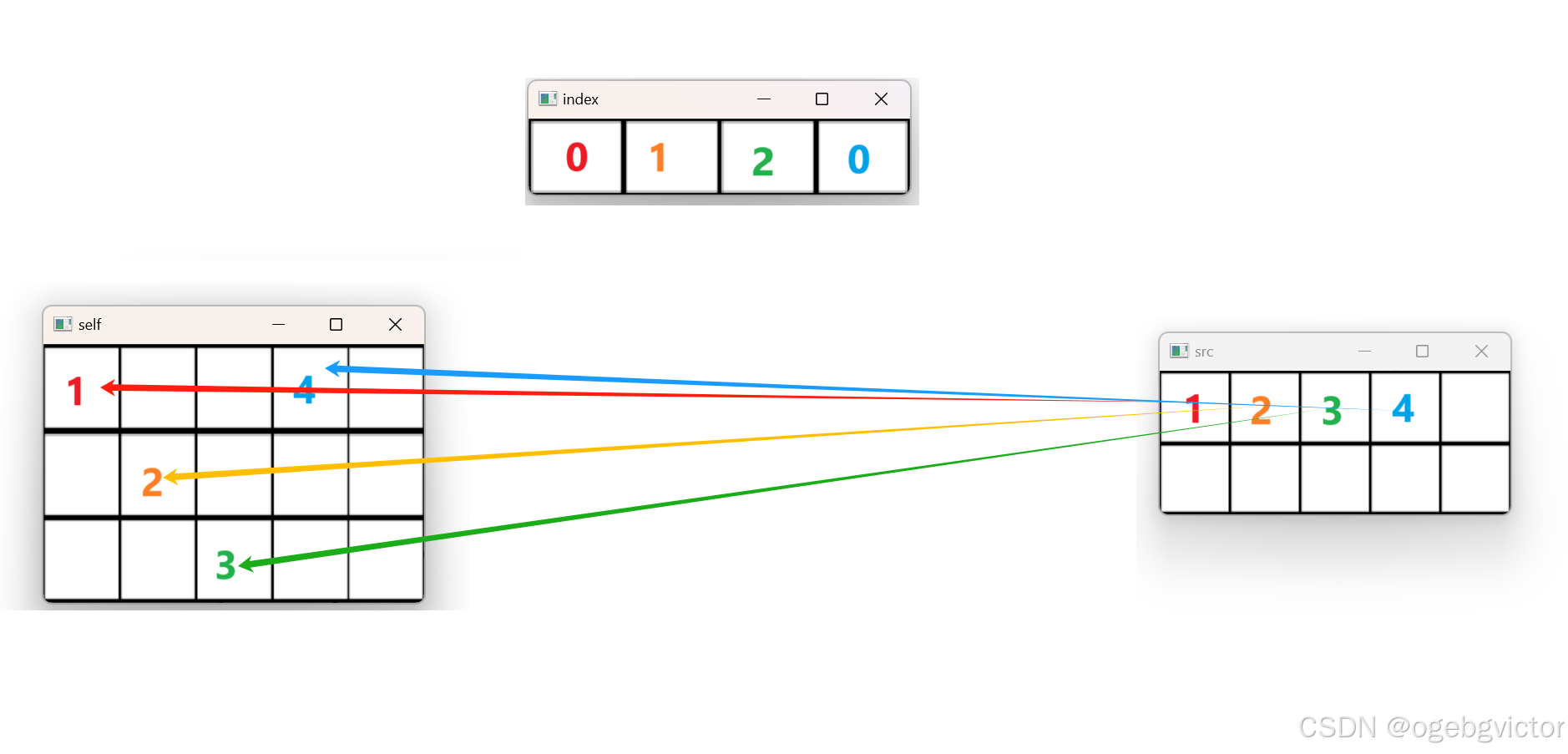
如果把这个操作反转,就是gather,input就是之前的self(当然喽,gather没有in-place操作,torch.scatter的input就是现在的input,它们是同一个角色),ouput就是之前的src,但是output由于是自动返回的新张量,所以形状不由我们指定,它的形状跟index相同。
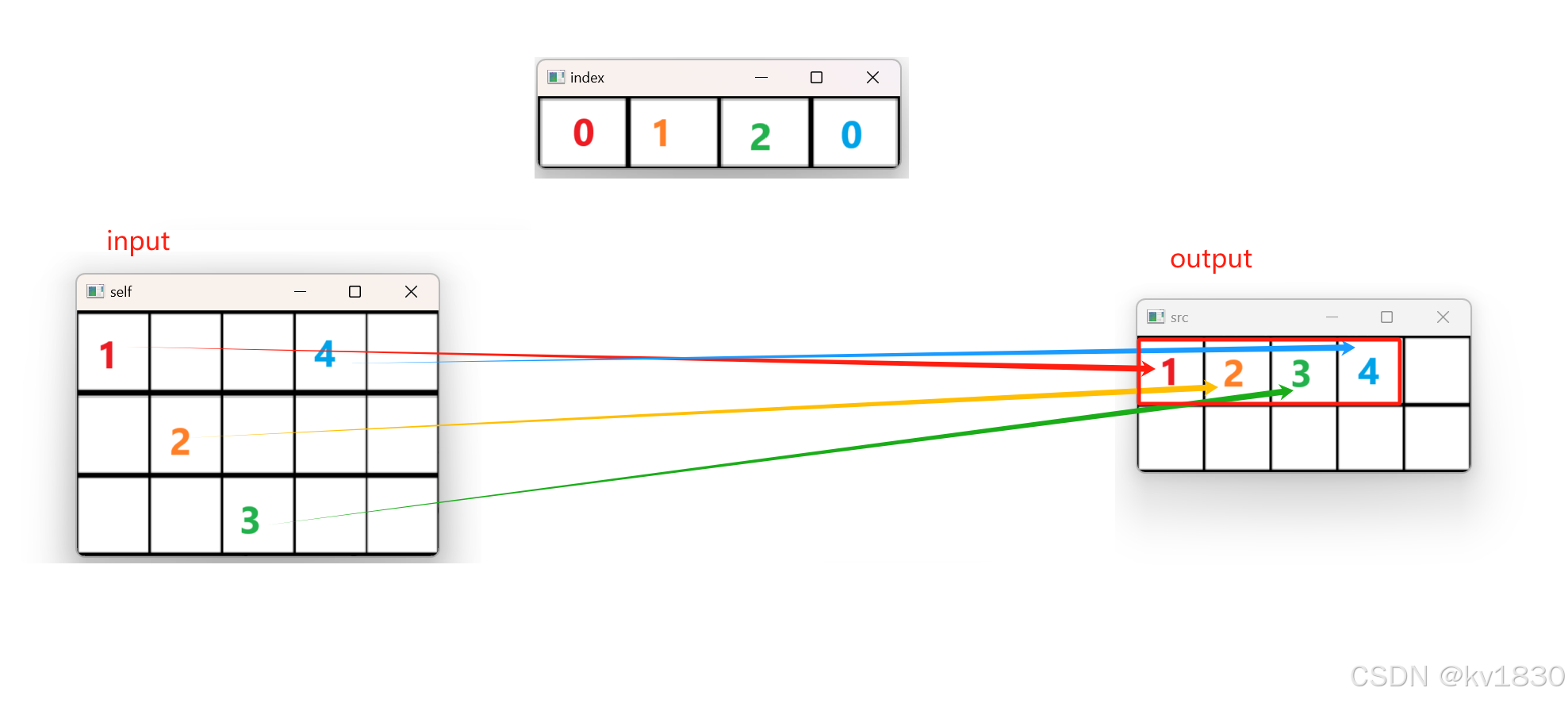
所以gather的操作过程(以上图为例,dim==0),就是遍历index[i,j],将input[index[i,j],j]的值赋给output[i,j]。具体过程就不再像scatter那样演示一遍了,只要理解“逆操作”就能明白了。
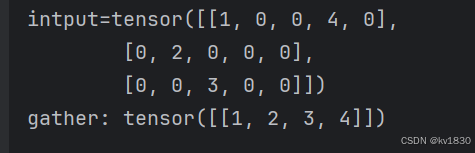
直接放上如上例子的代码,最后一行就是gather操作。
import torch
if __name__ == '__main__':
src = torch.arange(1, 11).reshape((2, 5))
index = torch.tensor([[0, 1, 2, 0]])
intput = torch.zeros(3, 5, dtype=src.dtype)
intput.scatter_(0, index, src)
print(f'intput={intput}')
print(f'gather: {torch.gather(intput, 0, index)}')
结果如下:
之前试图在scatter完成不了的操作如下图,现在用gather完成
import torch
if __name__ == '__main__':
intput = torch.arange(1, 9).reshape((4, 2))
index = torch.tensor([[0, 1], [2, 3]])
print(torch.gather(intput, 0, index))
结果如下:
tensor([[1, 4],
[5, 8]])

















 196
196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









