




 本文深入探讨了卷积神经网络在序列到序列(Seq2Seq)学习中的应用,介绍了基于卷积的Seq2Seq模型如何克服传统RNN模型的限制,尤其是在并行处理和长距离依赖捕捉方面的优势。文章详细解析了模型结构,包括卷积操作、注意力机制以及如何进行预测。
本文深入探讨了卷积神经网络在序列到序列(Seq2Seq)学习中的应用,介绍了基于卷积的Seq2Seq模型如何克服传统RNN模型的限制,尤其是在并行处理和长距离依赖捕捉方面的优势。文章详细解析了模型结构,包括卷积操作、注意力机制以及如何进行预测。
文章目录
前言
Convolutional Sequence to Sequence Learning
基于卷积的序列到序列学习
作者:Jonas Gehring
单位:Facebook AI Research
发表会议及时间:ICML2017
在线LaTeX公式编辑器
a. Seq2seq
NLP中的一类任务就是序列生成,指的是让神经网络按序生成符合语法规则的自然语言文本。目前的序列生成任务大都基于seq2seq框架。掌握基础的seq2seq结构,以及在seq2seq中加入attention的改进版结构。
b. 卷积神经网络
卷积神经网络是基础的神经网络结构。掌握一维滤波、二维滤波的基本操作,熟悉CNN相对于RNN的优势与劣势。
第一课 论文导读
序列到序列模型
Sequence-to-sequence(seq2seq)模型,顾名思义,其输入是一个序列,输出也是一个序列,例如输入是英文句子,输出则是翻译的中文。seq2seq 可以用在很多方面:机器翻译、QA系统、文档摘要生成、Image Captioning(图片描述生成器)。
x
=
{
x
1
,
x
2
,
.
.
.
,
x
n
x
}
x=\{x_1,x_2,...,x_{n_x}\}
x={x1,x2,...,xnx}
y
=
{
y
1
,
y
2
,
.
.
.
,
y
n
y
}
y=\{y_1,y_2,...,y_{n_y}\}
y={y1,y2,...,yny}
P
(
y
∣
x
)
=
∏
t
=
1
n
y
p
(
y
t
∣
y
1
,
y
2
,
.
.
.
,
y
t
−
1
,
x
)
P(y|x)=\prod_{t=1}^{n_y}p(y_t|y_1,y_2,...,y_{t-1},x)
P(y∣x)=t=1∏nyp(yt∣y1,y2,...,yt−1,x)
典型模型:
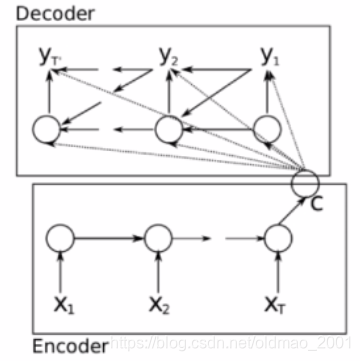
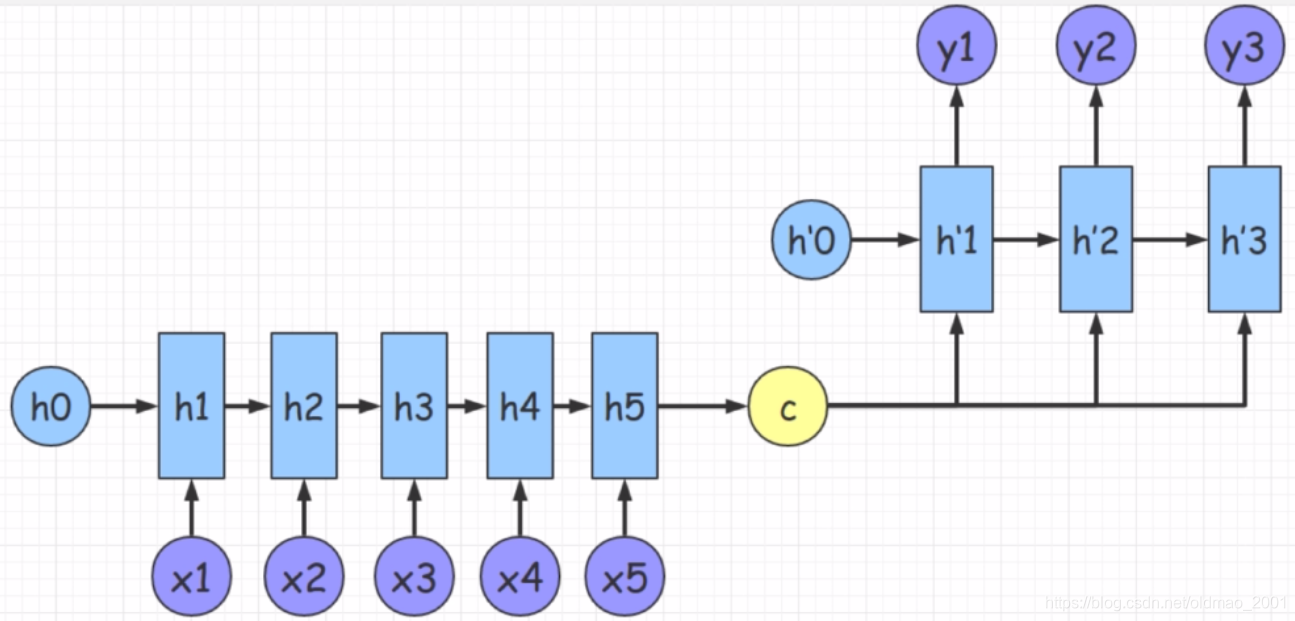
换个角度看:
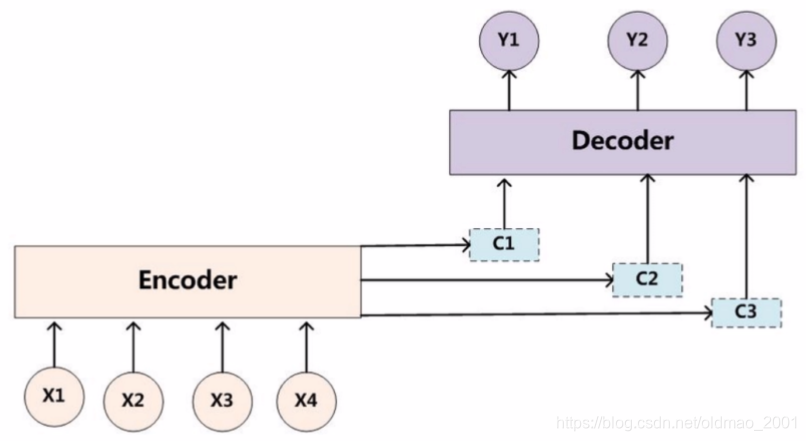
第一个模型和这个一样,c参与后面每个状态的解码,这样的好处是能够捕获每个时刻的语义信息,但是这里输入输出长度不一样
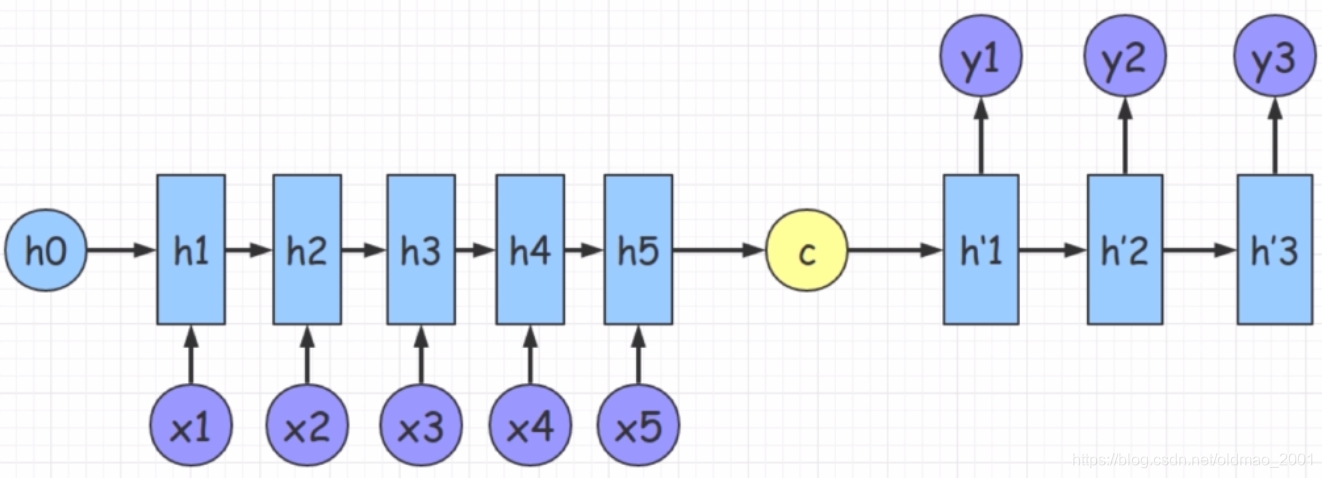
这里的和模型的c不参与后面的解码,只是作为解码的初始状态传入解码器。
加入注意力的序列到序列
虽然c参与到每个时刻的语义预测计算,但是每个词的重要程度对于预测结果是不一样的,因此引入了注意力(也就是输入x和c的相似度来度量重要性)
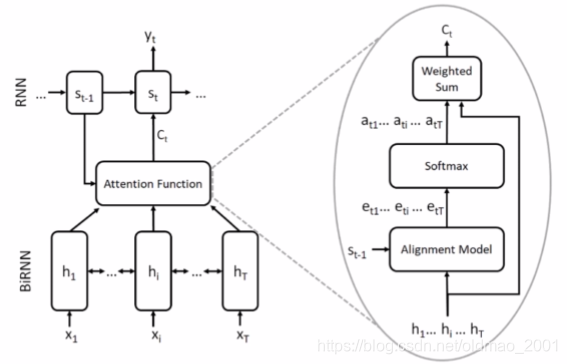
上述过程用数学来描述就是:
(
h
1
,
.
.
.
,
h
T
)
=
B
i
R
N
N
(
x
1
,
.
.
.
,
x
T
)
(h_1,...,h_T)=BiRNN(x_1,...,x_T)
(h1,...,hT)=BiRNN(x1,...,xT)
p
(
y
t
∣
x
1
,
.
.
.
,
x
T
,
y
1
,
.
.
.
,
y
t
−
1
)
=
R
N
N
(
s
t
−
1
,
c
t
)
p(y_t|x_1,...,x_T,y_1,...,y_{t-1})=RNN(s_{t-1},c_t)
p(yt∣x1,...,xT,y1,...,yt−1)=RNN(st−1,ct)
e
t
i
=
f
(
s
t
−
1
,
h
i
)
e_{ti}=f(s_{t-1},h_i)
eti=f(st−1,hi)
a
t
i
=
e
x
p
(
e
t
i
)
∑
j
=
1
T
e
x
p
(
e
t
j
)
a_{ti}=\frac{exp(e_{ti})}{\sum_{j=1}^Texp(e_{tj})}
ati=∑j=1Texp(etj)exp(eti)
上面是归一化操作,这里原文好像用的
α
\alpha
α
c
t
=
∑
i
a
t
i
h
i
c_t=\sum_ia_{ti}h_i
ct=i∑atihi
Seq2Seq发展历史
趋势:
更好地建模x和y间的依存关系
更快、更并行化
更深的层次,更大的数据
基于LSTM的seq2seq–>加入attention–>使用conv -->Transformer
Seq2Seq类型
RNN
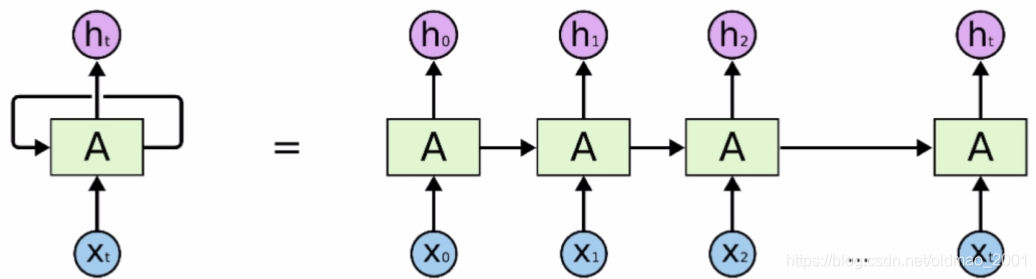
是一种自回归模型,展开后有很多种变体。
n VS 1
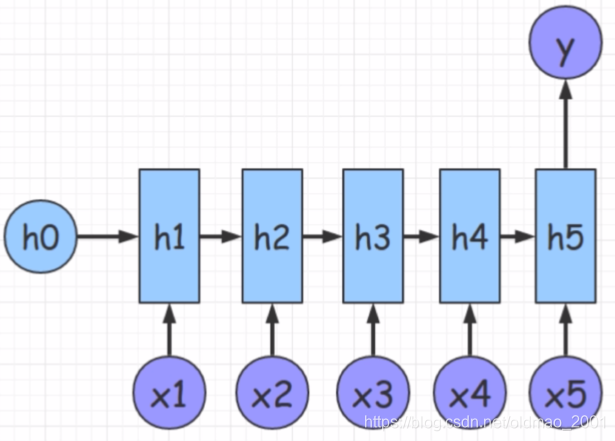
1 VS n
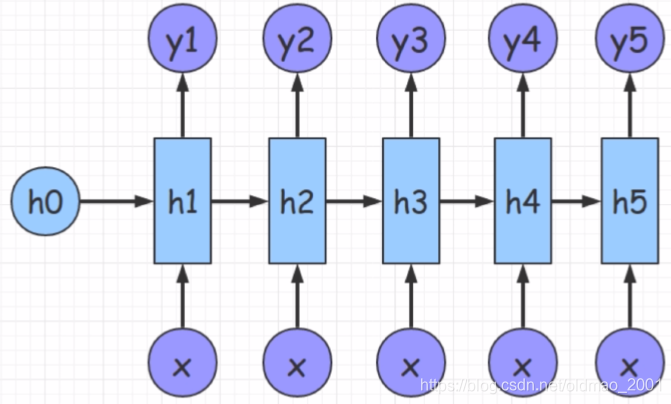
n VS m
这里n和m可以不等,是典型的seq2seq网络。
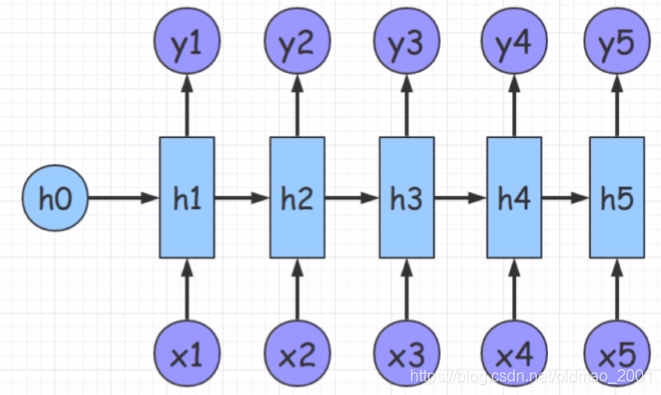
1.基于recurrent结构,不能并行
2.RNN不能很深,梯度爆炸
3.能否利用卷积?
卷积神经网络
这里不会讲很细,点几个CNN中重要的概念:
滤波器:[-1,0,1]
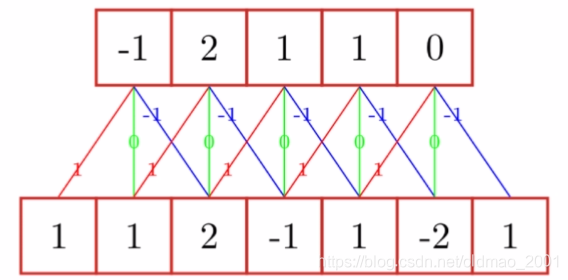
二维卷积:
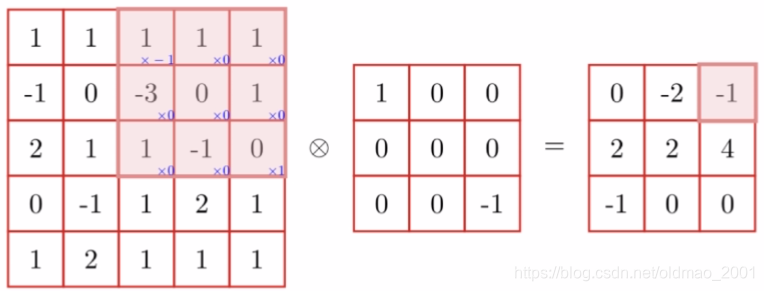
多组滤波器
CNN感受野
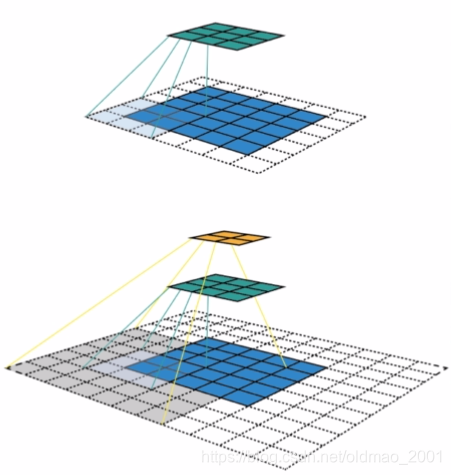
由于LSTM是自回归,所以LSTM的感受野要比CNN小很多。(这里是第一次听到LSTM有感受野的概念)
吾同学的解答:
自回归指只能从左向右或者从右向左 以从左向右为例 在lstm看到t3时刻时 lstm只能含有t1和t2时刻的信息 而没有t4及其以后的信息 所以感受视野就小很多;而cnn不同 不同的卷积核叠加起来多层 比如conv1d 一个filter如果大小为dim * 5 能够感受到,那么一次性能感受到5个token的信息 如果网上叠加层的话感受视野会更大
前期知识储备
seq2seq:掌握seq2seq框架的思想及主要应用场景
Attentive seq2seq:了解在sea2seq中加入注意力机制的动机
卷积:掌握卷积神经网络的计算方式及应用(如分类)
作业:
为了使用CNN作为Decoder,作者进行了哪些改进?
能否Encoder使用RNN、Decoder使用CNN?查阅相关资料,并尝试设计模型
第二课 论文精读
动机
之前的seq2seq模型都是基于RNN的,前面也讨论了基于RNN的seq2seq模型有一些不足:
1.不能并行
2.不能重复利用
3.梯度消失与爆炸
而基于CNN来构建seq2seq的优势:
1.可以并行
2.可以有很大的感受野,在处理长文的时候有优势
模型
模型看上去很复杂,箭头没截图出来,总体分三部分:左下是Decoder Context,右上是Source Encoder,右下是Decoder输出。
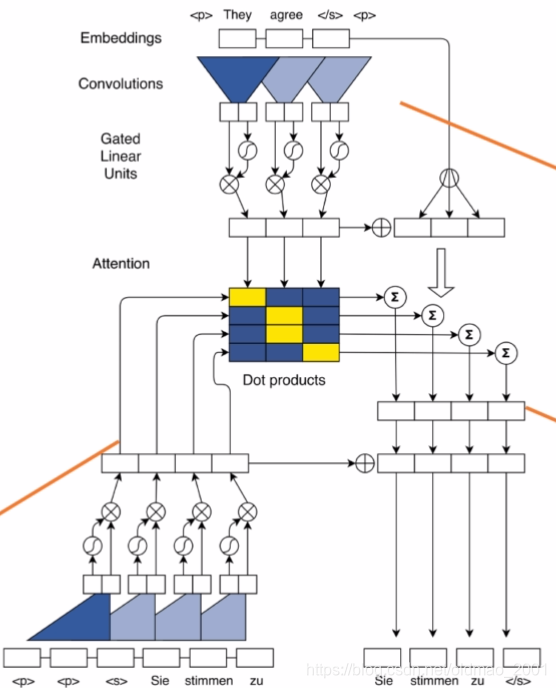
老师有讲这里CNN的并行是在训练阶段,由于训练阶段能够知道ground truth。
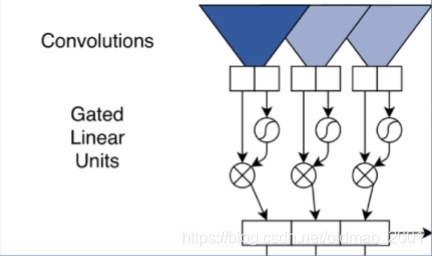
卷积结构
为了使得卷积结构能够处理seq的时候能够保持语序信息,在embedding的时候加入了词的position信息。最新的bert也有类似的处理。
Encoder第l层
z
l
=
(
z
1
l
,
z
2
l
,
.
.
.
,
z
n
l
)
z^l=(z^l_1,z^l_2,...,z^l_n)
zl=(z1l,z2l,...,znl)
Decoder第l层
h
l
=
(
h
1
l
,
h
2
l
,
.
.
.
,
h
m
l
)
h^l=(h^l_1,h^l_2,...,h^l_m)
hl=(h1l,h2l,...,hml)
W
∈
ℜ
2
d
×
k
d
W\in\real^{2d×kd}
W∈ℜ2d×kd
b
∈
ℜ
2
d
b\in \real^{2d}
b∈ℜ2d
Y
=
W
X
+
b
∈
ℜ
2
d
=
[
A
;
B
]
Y=WX+b\in\real^{2d}=[A;B]
Y=WX+b∈ℜ2d=[A;B]
X是输入,这里的维度讲解有点没跟上,暂时先记下来。
输入是d维,输出是2d维,其中前d维是真正的输出记为A,后d维是gate的输出结果记为B,用于控制信息的流动
v
(
[
A
;
B
]
)
=
A
⊗
σ
(
B
)
v([A;B])=A\otimes \sigma(B)
v([A;B])=A⊗σ(B)
这里就是门的计算了,定义一个函数v,后面是门常规操作。最后结果的d维的
z
i
l
=
v
(
W
l
[
z
i
−
k
2
l
−
1
;
.
.
.
;
z
i
+
k
2
l
−
1
]
+
b
l
)
+
z
i
l
−
1
z_i^l=v\left(W^l[z^{l-1}_{i-\frac{k}{2}};...;z^{l-1}_{i+\frac{k}{2}}]+b^l\right)+z_i^{l-1}
zil=v(Wl[zi−2kl−1;...;zi+2kl−1]+bl)+zil−1
用v来表示整体的卷积操作,假设当前位置是i,卷积窗口是k,则当前位置的卷积核对应的是从i往左k/2个位置和i往右k/2个位置的这样一个范围。将这个范围内的向量拼接成为kd维的,然后再乘上
W
l
W^l
Wl,再加上
b
l
b^l
bl输出一个2d维的向量,然后再通过v函数,得到d维的向量,
z
i
l
−
1
z_i^{l-1}
zil−1是残差信息,这个玩意的作用是能够把前面的信息保留过来。
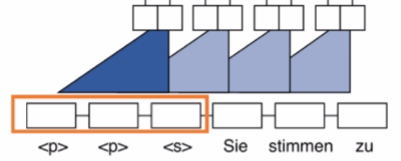
卷积的padding
Encoder:由于信息都是知道的,所以可以在前面和后面做padding。
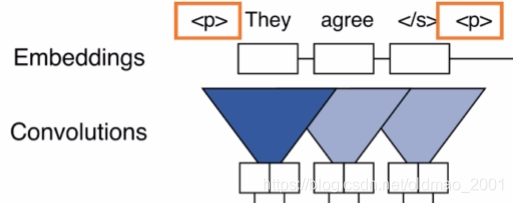
Decoder:由于不能预知未来信息,所以只能在前面做padding
预测
通过decoder最后一层得到当前时刻的一个表示,然后接到全连接层(词表大小*d),然后过softmax,得到词表里面的词出现的概率(维度=词表大小)。
P
(
y
i
+
1
∣
y
1
,
.
.
.
,
y
i
)
=
s
o
f
t
m
a
x
(
W
o
h
i
l
+
b
o
)
P(y_{i+1}|y_1,...,y_i)=softmax(W_oh_i^l+b_o)
P(yi+1∣y1,...,yi)=softmax(Wohil+bo)
注意力机制
d
i
l
=
W
d
l
h
i
l
+
b
d
l
+
g
i
d_i^l=W_d^lh_i^l+b_d^l+g_i
dil=Wdlhil+bdl+gi
d
i
l
d_i^l
dil是当前时刻的表示
h
i
l
h_i^l
hil经过一个全连接之后加上一个偏置
b
d
l
b_d^l
bdl,在加上前一个时刻的输入词的embedding:
g
i
g_i
gi
a
i
j
l
=
e
x
p
(
d
i
l
⋅
z
j
u
)
∑
t
=
1
n
e
x
p
(
d
i
l
⋅
z
t
u
)
a^l_{ij}=\frac{exp(d_i^l\cdot z_{j}^u)}{\sum_{t=1}^nexp(d_i^l\cdot z_{t}^u)}
aijl=∑t=1nexp(dil⋅ztu)exp(dil⋅zju)
c
t
l
=
∑
t
=
1
n
a
i
j
l
(
z
j
u
+
e
j
)
c^l_t=\sum_{t=1}^na_{ij}^l(z_j^u+e_j)
ctl=t=1∑naijl(zju+ej)
这里的注意力机制是Multi-step Attention,也就是这里的注意力不止用一次,而是每次往上叠的时候都用,每一层就是一个step,多层就是multistep。下面应该是动图的,先这样。
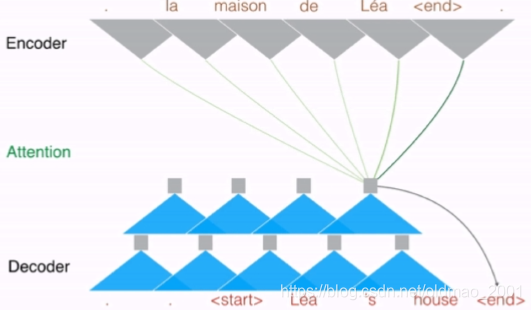
实验结果
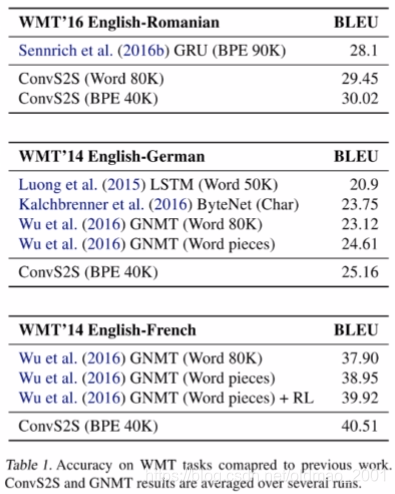
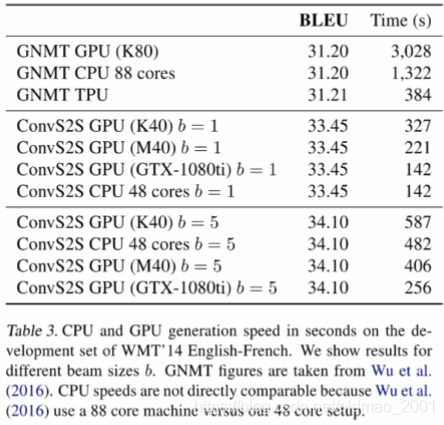
下面的图表明本文的模型在cpu消耗上要少很多。
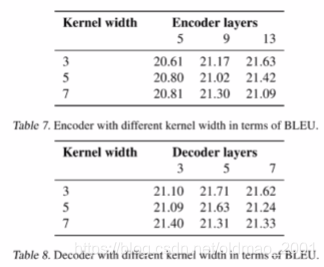
不同kernel和加解码层数对结果影响:
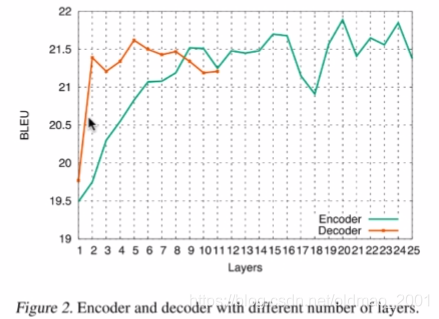
encoder的层数增加影响较大。
讨论和总结
A .提出一种新的seq2seq方法
1.用卷积做序列到序列学习
2.Multi-step attention
B.证明了卷积也可以用来做生成式任务
C.对后续工作有很大启发
实验分析十分详尽


















 1121
1121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











