









文章目录
前言
本课程来自深度之眼deepshare.net,部分截图来自课程视频。
文章标题:Character-level Convolutional Networks for Text Classification
原标题翻译:基于CNN的字符级文本分类
或
使用字符级别的卷积神经网络来做文本分类任务
作者:Xiang Zhang,Junbo Zhao,Yann LeCun
单位:New York University
发表会议及时间:NIPS 2015
在线LaTeX公式编辑器
这个文章的实验使用的词向量居然是独热编码。
论文总览

学习目标导图

研究意义
构建了多个文本分类数据集(8个),极大地推动了文本分类的研究工作。
提出的CharTextCNN方法因为只使用的字符信息(可以不用语法语义信息,分词也不用),所以可以用于多种语言中。
第一课 论文导读
- 文本分类的概念
文本分类就是将一句或者一段文本内容分到指定的类别。文本分类是自然语言处理的基础任务,应用于自然语言处理的各个领域,如信息检索,信息过滤,垃圾邮件分类。 - 两种基于词向量和卷积神经网络的文本分类模型
基于词向量和分类模型就是将一句话中的每个词表示成词向量,然后这句话将可以表示成一个矩阵,然后使用卷积神经网络分类模型即可对文本进行分类。 - CNN的相关概念
本文使用的是一维卷积,对于一维卷积,需要了解卷积核的尺寸,卷积核个数,步长以及padding这些概念。
在论文发表时关于CNN的应用:
卷积神经网络用于文本特征提取:Convolutional Neural Networks for Sentence Classification, 2014
卷积神经网络用于声音特征提取:Convolutional Neural Networks for Speech Recognition, 2014
字符信息用于生成词表示:Learning Character-level Representations for Part-of-Speech Tagging, 2014
论文背景
- 文本分类是自然语言处理的基础任务之一,目前大多数文本分类任务都是基于词的。
- 卷积神经网络能够成功提取出原始信息中的特征,如图像和语音,于是本文在字符级别的数据上使用卷积神经网络来提取特征。
- 在文本上使用卷积神经网络已经很常见了,而且使用字符级别的特征来提高自然语言处理任务的性能也有很多的研究。
- 本文首次使用纯字符级别的卷积神经网络,我们发现我们的卷积神经网络不需要单词级别的信息就能够在大规模语料上得到很好的结果。
文本分类简介
文本分类
文本分类:文本分类就是根据文本内容(可以是句子或者文章)将其分到合适的类别。
意义:文本分类是自然语言处理的基础问题,可以用于信息检索,信息过滤,邮件分类等任务。
例如:下图就是垃圾邮件分类

文本分类发展历史
50年代:专家规则:通过专家规则进行分类
80年代:专家系统:利用知识工程建立专家系统
90年代:机器学习:人工特征工程+浅层分类模型
2013年:深度学习:词向量+深度神经网络
机器学习
·人工特征工程:
◆设计特征
1.统计词表内所有词在文本内出现的频率。
2.计算词表中每个词在文本中的TF-IDF。
3.统计N-grams词组信息。
◆特征选择和特征降维:
1.信息增益、互信息等。
2.PCA,SVD等。
·浅层分类模型:
◆SVM,KNN,决策树。

深度学习
Kim,2014 Convolutional Neural Networks for Sentence Classification
就是上一个(第八篇)文章中的带读
另一种基于卷积神经网络的文本分类模型
A Sensitivity Analysis of(and Practitioners’ Guide to)Convolutional Neural Networks for Sentence Classification

前期知识储备
·卷积神经网络相关知识
·了解卷积神经网络相关知识,如卷积核,max pooling等。可以参考知乎:https://www.zhihu.com/question/52668301/answer/131573702
·One-hot表示的概念
第二课 论文精读
论文整体框架
摘要
1.介绍
2.字符级别的卷积模型
3&4.对比模型&实验
5.讨论
6.总结与展望
- Introduction
- Character-level Convolutional Networks
2.1 Key Modules
2.2 Character quantization
2.3 Model Design
2.4 Data Augmentation using Thesaurus - Comparison Models
3.1 Traditional Methods
3.2 Deep Learning Methods
3.3 Choice of Alphabet - Large-scale Datasets and Results
- Discussion
- Conclusion and Outlook
摘要
- 本文从实验角度探索了字符级别卷积神经网络用于文本分类的有效性。
- 我们构造了几个大规模的文本分类数据集,实验结果表明我们的字符级别文本分类模型能够取得最好的或者非常有竞争力的结果。(两个贡献)
- 对比模型包括传统的词袋模型、n-grams模型以及他们的tf-idf变体,还有一些基于深度学习的模型,包括基于卷积神经网络和循环神经网络的文本分类模型。
传统/经典算法模型
Bag-of-words
算法:
1.构建一个一个50000个词的词表。
2.对于一篇文档d,统计词表中每个词在d中出现的次数。
3.根据词表中每个词在d中出现的次数,构建一个词表大小的向量。
TFIDF版本:
w
i
,
j
=
f
t
i
,
j
∗
l
o
g
N
d
f
i
w_{i,j}=ft_{i,j}*log\frac {N}{df_i}
wi,j=fti,j∗logdfiN, for a word i in doc j

基于词向量的k-means
算法:
1.首先将每个词映射成一个词向量(使用训练好的词向量)。
2.在所有的词上使用k-means进行聚类,类别数为5000。
3.对于每个词,都划分其属于哪个k-means类。
4.对于一篇文档d中的每个词,查看它属于那个类别,然后一篇文档就可以表示成一个5000维的向量,每个位置代表这篇文档中有多少属于这个类别的词。
5.后面接多分类的logistic回归。
基于词的卷积网络模型(略)
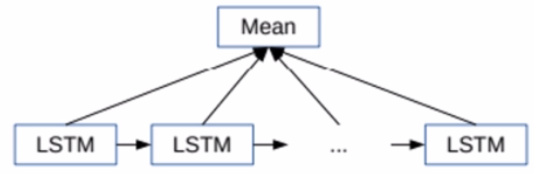
长短时记忆模型
算法:
1.将训练好的word2vec词向量输入到LSTM。
2.LSTM每个时间步的输出取平均作为文档的表示。
3.后面接一个多分类的logistic回归。
模型
一维卷积
h
(
y
)
=
∑
x
=
1
k
f
(
x
)
⋅
g
(
y
⋅
d
−
x
+
c
)
(1)
h(y)=\sum_{x=1}^kf(x)\cdot g(y\cdot d-x+c)\tag1
h(y)=x=1∑kf(x)⋅g(y⋅d−x+c)(1)
其中d是步长
k是filter size,下图中大小是5
c=k-d+1
先看简单的例子:
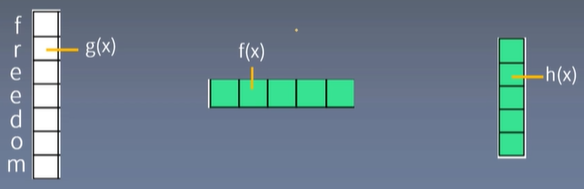
竖着的是一个单词,单词每个字母都有一个特征(feature,这里长度只有1),用
g
(
x
)
g(x)
g(x)表示
横着的绿色是filter,用
f
(
x
)
f(x)
f(x)表示
上面两个东西根据公式可以算出
h
(
x
)
h(x)
h(x),累加以后得到
h
(
y
)
h(y)
h(y)
取步长d=1,c=5-1+1=5
当
y
=
1
,
x
=
1
y=1,x=1
y=1,x=1时
f
(
x
)
⋅
g
(
y
⋅
d
−
x
+
c
)
=
f
(
1
)
⋅
g
(
1
⋅
1
−
1
+
5
)
=
f
(
1
)
g
(
5
)
f(x)\cdot g(y\cdot d-x+c)=f(1)\cdot g(1\cdot 1-1+5)=f(1)g(5)
f(x)⋅g(y⋅d−x+c)=f(1)⋅g(1⋅1−1+5)=f(1)g(5)
当
y
=
1
,
x
=
2
y=1,x=2
y=1,x=2时
f
(
x
)
⋅
g
(
y
⋅
d
−
x
+
c
)
=
f
(
2
)
⋅
g
(
1
⋅
1
−
2
+
5
)
=
f
(
2
)
g
(
4
)
f(x)\cdot g(y\cdot d-x+c)=f(2)\cdot g(1\cdot 1-2+5)=f(2)g(4)
f(x)⋅g(y⋅d−x+c)=f(2)⋅g(1⋅1−2+5)=f(2)g(4)
当
y
=
1
,
x
=
3
y=1,x=3
y=1,x=3时
f
(
x
)
⋅
g
(
y
⋅
d
−
x
+
c
)
=
f
(
3
)
⋅
g
(
1
⋅
1
−
3
+
5
)
=
f
(
3
)
g
(
3
)
f(x)\cdot g(y\cdot d-x+c)=f(3)\cdot g(1\cdot 1-3+5)=f(3)g(3)
f(x)⋅g(y⋅d−x+c)=f(3)⋅g(1⋅1−3+5)=f(3)g(3)
当
y
=
1
,
x
=
4
y=1,x=4
y=1,x=4时
f
(
x
)
⋅
g
(
y
⋅
d
−
x
+
c
)
=
f
(
4
)
⋅
g
(
1
⋅
1
−
4
+
5
)
=
f
(
4
)
g
(
2
)
f(x)\cdot g(y\cdot d-x+c)=f(4)\cdot g(1\cdot 1-4+5)=f(4)g(2)
f(x)⋅g(y⋅d−x+c)=f(4)⋅g(1⋅1−4+5)=f(4)g(2)
当
y
=
1
,
x
=
5
y=1,x=5
y=1,x=5时
f
(
x
)
⋅
g
(
y
⋅
d
−
x
+
c
)
=
f
(
5
)
⋅
g
(
1
⋅
1
−
5
+
5
)
=
f
(
5
)
g
(
1
)
f(x)\cdot g(y\cdot d-x+c)=f(5)\cdot g(1\cdot 1-5+5)=f(5)g(1)
f(x)⋅g(y⋅d−x+c)=f(5)⋅g(1⋅1−5+5)=f(5)g(1)
累加:
h
(
y
=
1
)
=
f
(
1
)
g
(
5
)
+
f
(
2
)
g
(
4
)
+
f
(
3
)
g
(
3
)
+
f
(
4
)
g
(
2
)
+
f
(
5
)
g
(
1
)
h(y=1)=f(1)g(5)+f(2)g(4)+f(3)g(3)+f(4)g(2)+f(5)g(1)
h(y=1)=f(1)g(5)+f(2)g(4)+f(3)g(3)+f(4)g(2)+f(5)g(1)
实际上每一个字符不可能用一个数字来表示,这样特征就只有一个,不科学,要用很多数组成一个向量表示,所以就变成下面这个样子:
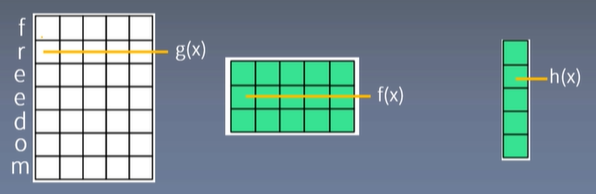
这个向量的维度(就是白色矩阵的行的长度)就代表字符的特征(feature),多个字符组成的长度称为length(白色矩阵的列的长度)
卷积核的尺寸也变成了二维的,其行的长度和输入字符向量长度(feature)一样,然后另外一个维度论文中用了多种filter size大小:

如果使用了多个filter,最后右边结果的行长度就等于filter的个数,这里的每一个维度就是输出的特征(feature),列长度计算则是根据公式:
⌊
(
l
e
n
g
t
h
−
k
)
/
d
⌋
+
1
(2)
\left \lfloor(length-k)/d\right \rfloor+1\tag2
⌊(length−k)/d⌋+1(2)
例如上图中:7-5/1向下取整为2,2+1=3,所有最后得到的结果列长为3,上图中画了5,有错。
重点:一维卷积既然是卷积,那么和图像中的卷积思想一样,图像卷积就是要特征不断提取,每次经过卷积后尺寸通常变小,得到的特征也就越全局化。这里的一维卷积则是在单词的长度length这个上面做的,经过一维卷积之后,相当于把length减小了。
字符量化
原文的2.2节,Character quantization,实际上就是把字符映射为数字,这里没有用字符嵌入的表示,而是直接用独热编码来表示。
The alphabet used in all of our models consists of 70 characters, including 26 english letters, 10 digits, 33 other characters and the new line character. The non-space characters are:(换行是/n)
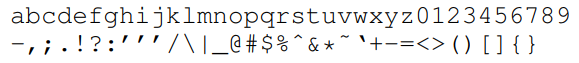
不在字符表中的字符用全零向量表示。
文本分类模型
输入是字符的one-hot表示而不是char embedding,然后后面接卷积神经网络分类器。下图中左下角的就是one-hot表示,垂直方向(长度为3)。
然后每一个filter做卷积操作得到feature map的一行。然后max pooling 后面是三个全连接。

下面根据公式(2)计算一下输出length维度:
小模型卷积核个数256
大模型卷积核个数用1024

输入的feature length是1014(原文是这么写的),我们用
l
0
l_0
l0代替
经过第一层卷积:
(
l
0
−
7
)
/
1
+
1
=
l
0
−
7
+
1
=
l
0
−
6
(l_0-7)/1+1=l_0-7+1=l_0-6
(l0−7)/1+1=l0−7+1=l0−6,这里的7就是上表中的第一行的kernel大小,步长是1,所以取整可以不用要。
然后是第一层max pooling,这里的pool size是3,所以是对length方向上的3个值中取一个最大值,结果为;
l
0
−
6
3
\cfrac{l_0-6}{3}
3l0−6
经过第二层卷积:
l
0
−
6
3
−
7
+
1
=
l
0
−
6
3
−
6
\cfrac{l_0-6}{3}-7+1=\cfrac{l_0-6}{3}-6
3l0−6−7+1=3l0−6−6
经过第二层max pooling:
l
0
−
6
3
−
6
3
\cfrac{\cfrac{l_0-6}{3}-6}{3}
33l0−6−6
经过第三层卷积:
l
0
−
6
3
−
6
3
−
3
+
1
=
l
0
−
6
3
−
6
3
−
2
\cfrac{\cfrac{l_0-6}{3}-6}{3}-3+1=\cfrac{\cfrac{l_0-6}{3}-6}{3}-2
33l0−6−6−3+1=33l0−6−6−2
第三层没有pooling,经过第四层卷积:
l
0
−
6
3
−
6
3
−
2
−
2
\cfrac{\cfrac{l_0-6}{3}-6}{3}-2-2
33l0−6−6−2−2
第四层没有pooling,经过第五层卷积:
l
0
−
6
3
−
6
3
−
2
−
2
−
2
\cfrac{\cfrac{l_0-6}{3}-6}{3}-2-2-2
33l0−6−6−2−2−2
经过第六层卷积:
l
0
−
6
3
−
6
3
−
2
−
2
−
2
−
2
\cfrac{\cfrac{l_0-6}{3}-6}{3}-2-2-2-2
33l0−6−6−2−2−2−2
经过第六层max pooling:
l
0
−
6
3
−
6
3
−
2
−
2
−
2
−
2
3
=
l
0
−
96
27
\cfrac{\cfrac{\cfrac{l_0-6}{3}-6}{3}-2-2-2-2}{3}=\cfrac{l_0-96}{27}
333l0−6−6−2−2−2−2=27l0−96

上图是用torch显示模型参数的情况,看一下第一层卷积参数为:
卷积核个数(这里用小模型,是256个)×kernel_size(根据表1,这里是7)×(输入的特征size,第一层输入是字符表大小:70)+偏置(这里偏置个数和卷积核一样多:256)
256×7×70+256=125696
BN层有两个参数(具体看BN的公式,里面的
α
,
β
\alpha,\beta
α,β),对应256个卷积核,参数个数为:256×2=512
池化层不用参数
再看第一层输出shape:1008=1014-7+1
第一个池化:1008/3=336
数据扩充
原文2.4 Data Augmentation using Thesaurus
数据扩充可以使得模型获得更好的泛化能力。
文中使用了English thesaurus来替换同义词的方式进行数据扩充。
English thesaurus中对多个同义词的相关性进行了排序。选择某个同义词使用公式如下:
P
[
s
]
∼
q
s
P[s]\sim q^s
P[s]∼qs
q是选择某个同义词的概率,s是这个词的序号,序号越大代表相关性越小,被选择用来替换的概率也越小。
在选择替换词的个数上,原文用的是:
P
[
r
]
∼
p
r
P[r]\sim p^r
P[r]∼pr
p是替换概率,r代表替换词的个数
意思是替换一个词的概率是p,替换两个词的概率是
p
2
p^2
p2,也就是意味着不会替换很多个词。
原文对于参数p和q都取0.5。
对比模型及模型优缺点
分两部分对比,一个是传统模型3.1,一个是深度模型3.2。
优点:
·模型结构简单(6层卷积+3层全连接),并且在大语料上效果很好
·可以用于各种语言,不需要做分词处理
·在噪音比较多的文本上表现较好,因为基本不存在oov问题
缺点:
·字符级别的文本长度特别长,不利于处理长文本的分类
·只使用字符级别信息,所以模型学习到的语义方面的信息较少
·在小语料上效果较差(也是本文弄成这么多个大语料的原因)
实验和结果
数据集
8个

AG’s news corpus:新闻数据集,分4类,主题相关,每个类别3w记录。
Sogou news corpus:新闻数据集,分5类,主题相关,每个类别9w记录。这个是中文数据,作者用pypinyin package combined with jieba Chinese segmentation system to produce Pinyin得到拼音。
DBPedia ontology dataset:来自维基百科,主题相关。
Yelp reviews:餐馆评论数据集,2分类:1 and 2 negative, and 3 and 4 positive.
5分类:5星评论各为一类。语义相关。
Yahoo! Answers dataset:10分类,主题相关
Amazon reviews:和Yelp 一样有两种分类方法。语义相关。
实验结果
本文提出的字符级别的文本分类模型在文本分类数据集上都能取得最好或者有竞争力的结果。

红色是最差结果,蓝色是最好结果,full代表区分大小写(如果加大写字符表就是70+26),不进行小(大)写转化。th代表进行了数据扩充。
根据错误率直观地和本文提出的模型进行比较,如果大于0就是比本文的模型差,如果小于0就是比本文的模型差。

从上图可以看到,前面三个数据集比较小,所以传统的方法反而效果比较好。
讨论和总结
关键点
·卷积神经网络能够有效地提取关键的特征
·字符级别的特征对于自然语言处理的有效性
·CharTextCNN模型
创新点
·提出了一种新的文本分类模型-CharTextCNN
·提出了多个的大规模的文本分类数据集
·在多个文本分类数据集上取得最好或者非常有竞争力的结果
启发点
·基于卷积神经网络的文本分类不需要语言的语法和语义结构的知识。
ConvNets do not require the knowledge about the syntactic or semantic structure ofa language(Introduction P6)
·实验结果告诉我们没有一个机器学习模型能够在各种数据集上都能表现的最好。
Our experiments once again verifies that there is not a single machine learning model that can work for all kinds of datasets(5 Discussion P8)
·本文从实验的角度分析了字符级别卷积神经网络在文本分类任务上的适用性。
This article offers an empirical study on character-level convolutional networks for text classification.(6Conclusion and Outlook P1)
讨论
1.本文的模型非常简单,为什么要讲这篇文章?
本文的模型简单,非常容易复现并且测试的数据集非常多,所以是很多模型的对比试验。
2.本文提出的模型的缺点?
在比较小的数据集上表现一般,并且模型比较深,参数很多。
3.是否还有其他基于字符的模型?
使用char embedding的方法。(2016年)
总结(创新点)
A提出了一种基于字符的文本分类模型。
B证明了字符像单词可以用于文本分类。
C本文提出的模型在多个数据集上表现最好或者非常有竞争力。
代码复现
代码结构如上图所示,分别是数据处理,模型,训练和配置。
数据集下载
AG News:https://s3.amazonaws.com/fast-ai-nlp/ag_news_csv.tgz
DBPedia:https://s3.amazonaws.com/fast-ai-nlp/dbpedia _csv.tgz
Sogou news:https://s3.amazonaws.com/fast-ai-nlp/sogou_news_csv.tgz
Yelp Review Polarity:https://s3.amazonaws.com/fast-ai-nlp/yelp_review_polarity_csv.tgz
Yelp Review Full:https://s3.amazonaws.com/fast-ai-nlp/yelp_review_full_csv.tgz YahoolAnswers:https://s3.amazonaws.com/fast-ai-nlp/yahoo_answers_csv.tgz
Amazon Review Full:https://s3.amazonaws.com/fast-ai-nlp/amazon_review_full_csv.tgz
Amazon Review Polarity:https://s3.amazonaws.com/fast-ai-nlp/amazon_review polarity _csv.tgz
下载解压后都是四个文件
class里面是数据集中的分类
readme是数据集简单介绍
数据处理模块
·数据集加载
·读取标签和数据
·读取所有的字符
·将句子one-hot表示
# coding:utf-8
from torch.utils import data
import os
import torch
import json
import csv
import numpy as np
# 继承torch的 data.DataLoader,并实现:
# __init__初始化
# __getitem__根据index获取数据
# __len__获取数据总大小
class AG_Data(data.DataLoader):
# 初始化,l0是输入的feature大小,论文里70个字符用的是1014
def __init__(self, data_path, l0=1014):
self.path = os.path.abspath('.')
if "data" not in self.path:
self.path += "/data"
self.data_path = data_path
self.l0 = l0
self.load_Alphabet()
self.load(self.data_path)
def __getitem__(self, idx):
X = self.oneHotEncode(idx)
y = self.y[idx]
return X, y
def __len__(self):
return len(self.label)
# 读取字符json文件,并把所有字符连在一起(无空格)
def load_Alphabet(self):
with open(self.path + "/alphabet.json") as f:
self.alphabet = "".join(json.load(f))
# 读取数据,data_path决定是训练集还是测试集
def load(self, data_path, lowercase=True):
self.label = []
self.data = []
with open(self.path + data_path, "r") as f:
# 数据中的分隔符是逗号:,双引号:"包围的是数据
datas = list(csv.reader(f, delimiter=',', quotechar='"'))
for row in datas:
# 原始数据中的标签是1.2.3.4,实际上的标签从0开始的,是0.1.2.3,所以要减去1,并且转换为int类型
self.label.append(int(row[0]) - 1)
# 用空格连接标题和内容,数据不用分词也不用额外处理
txt = " ".join(row[1:])
# 转换为小写
if lowercase:
txt = txt.lower()
self.data.append(txt)
self.y = self.label
# 将数据中每个字符对应到独热编码,如果字符不在字符表中(例如:空格)则用全零向量表示。
# torch 1d卷积和ld池化:batch_sizes*feature*length。2d卷积是4维的
# 所以这里为了方便把数据按上面的feature*length形式排列,后面在分batch_sizes
# 即:len(self.alphabet)字母表长度,这里是70, self.l0
def oneHotEncode(self, idx):
X = np.zeros([len(self.alphabet), self.l0])
for index_char, char in enumerate(self.data[idx][::-1]):
if self.char2Index(char) != -1:
X[self.char2Index(char)][index_char] = 1.0
return X
# 查询char在字母表中的位置,如果没有找到则返回-1
def char2Index(self, char):
return self.alphabet.find(char)
模型
训练
# -*- coding: utf-8 -*-
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
from model import CharTextCNN
from data import AG_Data
from tqdm import tqdm
import numpy as np
import config as argumentparser
# 读取参数
config = argumentparser.ArgumentParser()
config.features = list(map(int, config.features.split(","))) # 将features用,分割,并且转成int
config.kernel_sizes = list(map(int, config.kernel_sizes.split(","))) # 将kernel_sizes用,分割,并且转成int
config.pooling = list(map(int, config.pooling.split(",")))
if config.gpu and torch.cuda.is_available():
torch.cuda.set_device(config.gpu)
def get_test_result(data_iter, data_set):
# 生成测试结果
model.eval() # 设置测试状态,在这个状态下BN和DROPOUT都会和训练的时候有所不一样
data_loss = 0
true_sample_num = 0
for data, label in data_iter:
if config.cuda and torch.cuda.is_available():
data = data.cuda()
label = label.cuda()
else:
data = torch.autograd.Variable(data).float()
out = model(data)
loss = criterion(out, autograd.Variable(label.long()))
data_loss += loss.data.item()
true_sample_num += np.sum((torch.argmax(out, 1) == label).cpu().numpy())
acc = true_sample_num / data_set.__len__()
return data_loss, acc
training_set = AG_Data(data_path="/AG/train.csv", l0=config.l0)
# 导入训练集
training_iter = torch.utils.data.DataLoader(dataset=training_set,
batch_size=config.batch_size,
shuffle=True, # 这里每个epoch要把数据打乱
num_workers=0)
test_set = AG_Data(data_path="/AG/test.csv", l0=config.l0)
# 导入测试集
test_iter = torch.utils.data.DataLoader(dataset=test_set,
batch_size=config.batch_size,
shuffle=False, # 测试集没有标签不用打算
num_workers=0)
model = CharTextCNN(config)
if config.cuda and torch.cuda.is_available():
model.cuda()
# 构建loss
criterion = nn.CrossEntropyLoss()
# 使用Adam优化器
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
loss = -1
for epoch in range(config.epoch):
model.train()
process_bar = tqdm(training_iter)
for data, label in process_bar:
if config.cuda and torch.cuda.is_available():
data = data.cuda()
label = label.cuda()
else:
data = torch.autograd.Variable(data).float()
label = torch.autograd.Variable(label).squeeze()
out = model(data)
loss_now = criterion(out, autograd.Variable(label.long()))
if loss == -1:
loss = loss_now.data.item()
else:
loss = 0.95 * loss + 0.05 * loss_now.data.item() # 平滑操作
process_bar.set_postfix(loss=loss_now.data.item())
process_bar.update()
optimizer.zero_grad() # 梯度更新
loss_now.backward()
optimizer.step()
test_loss, test_acc = get_test_result(test_iter, test_set)
print("The test acc is: %.5f" % test_acc)

参数
# —*- coding: utf-8 -*-
import argparse
def ArgumentParser():
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=200, help="epoch of training")
parser.add_argument("--cuda", type=bool, default=True, help="whether use gpu")
parser.add_argument("--gpu", type=int, default=0, help="which gpu u gonna use")
parser.add_argument("--label_num", type=int, default=4, help="the label number of samples")
parser.add_argument("--learning_rate", type=float, default=0.0001, help="learning rate during training")
parser.add_argument("--batch_size", type=int, default=50, help="batch size during training")
parser.add_argument("--char_num", type=int, default=70, help="character number of samples")
# 特征个数
parser.add_argument("--features", type=str, default="256,256,256,256,256,256", help="filters size of conv")
# 卷积核大小
parser.add_argument("--kernel_sizes", type=str, default="7,7,3,3,3,3", help="kernel size of conv")
# 是否需要池化
parser.add_argument("--pooling", type=str, default="1,1,0,0,0,1", help="is use pooling of convs")
# 输入层的length
parser.add_argument("--l0", type=int, default="1014", help="length of character sentence")
parser.add_argument("--dropout", type=float, default=0.5, help="dropout of training")
parser.add_argument("--num_classes", type=int, default=4, help="number classes of data")
parser.add_argument("--seed", type=int, default=1, help="seed of random")
return parser.parse_args()
作业
【思考题】CharTextCNN和TextCNN模型的区别和联系,以及CharTextCNN的应用场景?
【代码实践】完善代码,划分验证集,加入early stopping,在其他数据集上测试分类效果。
【总结】总结CharTextCNN模型以及CharTextCNN模型的代码实现。
















 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











