







文章目录
前言
End-To-End Memory Networks
端对端的记忆网络
作者:Sainbayar Sukhbaatar et al.
单位:New York University & Facebook
发表会议及时间:NIPS2015
别人的翻译
在线LaTeX公式编辑器
了解记忆网络的概念,了解RNN序列模型以及它的两种变体GRU和LSTM。
记忆网络的概念
记忆网络就是设计模块来存储序列模型的中间结果以防丢失信息。
普通的RNN模型以及其变种GRU和LSTM
最常用的序列模型就是RNN模型以及它的两种变体GRU和LSTM,希望大家了解RNN模型并比较其与记忆网络的区别。
了解记忆网络
记忆网络最先提出了2014年Facebook的Memory Networks这篇文章,希望大家了解一下这种文章提出的记忆网络。
第一课 论文导读
记忆网络简介
记忆网络:通过设计记忆模块存储序列模型的中间结果以防丢失信息。
意义:可以解决RNN中信息丢失问题。

记忆网络相关方法
传统RNN
a
(
t
)
=
b
+
W
h
t
−
1
+
U
x
(
t
)
a^{(t)}=b+Wh^{t-1}+Ux^{(t)}
a(t)=b+Wht−1+Ux(t)
h
(
t
)
=
t
a
n
h
(
a
(
t
)
)
h^{(t)}=tanh(a^{(t)})
h(t)=tanh(a(t))
o
(
t
)
=
c
+
V
h
(
t
)
o^{(t)}=c+Vh^{(t)}
o(t)=c+Vh(t)
y
^
(
t
)
=
s
o
f
t
m
a
x
(
o
(
t
)
)
\hat y^{(t)}=softmax(o^{(t)})
y^(t)=softmax(o(t))

GRU
r
t
=
σ
(
W
r
⋅
[
h
t
−
1
,
x
t
]
)
r_t=\sigma(W_r\cdot[h_{t-1},x_t])
rt=σ(Wr⋅[ht−1,xt])
z
t
=
σ
(
W
z
⋅
[
h
t
−
1
,
x
t
]
)
z_t=\sigma(W_z\cdot[h_{t-1},x_t])
zt=σ(Wz⋅[ht−1,xt])
h
~
t
=
t
a
n
h
(
W
h
~
⋅
[
r
t
∗
h
t
−
1
,
x
t
]
)
\tilde h_t=tanh(W_{\tilde h}\cdot[r_t*h_{t-1},x_t])
h~t=tanh(Wh~⋅[rt∗ht−1,xt])
h
t
=
(
1
−
z
t
)
∗
h
t
−
1
+
z
t
∗
h
t
h_t=(1-z_t)*h_{t-1}+z_t*h_t
ht=(1−zt)∗ht−1+zt∗ht
y
t
=
σ
(
W
o
⋅
h
t
)
y_t=\sigma(W_o\cdot h_t)
yt=σ(Wo⋅ht)

LSTM
f遗忘门,u更新门,o输出门
Γ
f
⟨
t
⟩
=
σ
(
W
f
[
a
⟨
t
−
1
⟩
,
x
⟨
t
⟩
]
+
b
f
)
\Gamma_f^{\left \langle t\right \rangle}=\sigma(W_f[a^{{\left \langle t-1\right \rangle}},x^{\left \langle t \right \rangle}]+b_f)
Γf⟨t⟩=σ(Wf[a⟨t−1⟩,x⟨t⟩]+bf)
Γ
u
⟨
t
⟩
=
σ
(
W
u
[
a
⟨
t
−
1
⟩
,
x
⟨
t
⟩
]
+
b
u
)
\Gamma_u^{\left \langle t\right \rangle}=\sigma(W_u[a^{{\left \langle t-1\right \rangle}},x^{\left \langle t \right \rangle}]+b_u)
Γu⟨t⟩=σ(Wu[a⟨t−1⟩,x⟨t⟩]+bu)
c
~
⟨
t
⟩
=
t
a
n
h
(
W
C
)
[
a
⟨
t
−
1
⟩
,
x
⟨
t
⟩
]
+
b
C
\tilde c^{\left \langle t\right \rangle}=tanh(W_C)[a^{{\left \langle t-1\right \rangle}},x^{\left \langle t \right \rangle}]+b_C
c~⟨t⟩=tanh(WC)[a⟨t−1⟩,x⟨t⟩]+bC
c
⟨
t
⟩
=
Γ
f
⟨
t
⟩
⋅
c
⟨
t
−
1
⟩
+
Γ
u
⟨
t
⟩
⋅
c
~
⟨
t
⟩
c^{\left \langle t\right \rangle}=\Gamma_f^{\left \langle t\right \rangle}\cdot c^{\left \langle t-1\right \rangle}+\Gamma_u^{\left \langle t\right \rangle}\cdot \tilde c^{\left \langle t\right \rangle}
c⟨t⟩=Γf⟨t⟩⋅c⟨t−1⟩+Γu⟨t⟩⋅c~⟨t⟩
Γ
o
⟨
t
⟩
=
σ
(
W
o
[
a
⟨
t
−
1
⟩
,
x
⟨
t
⟩
]
+
b
o
)
\Gamma_o^{\left \langle t\right \rangle}=\sigma(W_o[a^{{\left \langle t-1\right \rangle}},x^{\left \langle t \right \rangle}]+b_o)
Γo⟨t⟩=σ(Wo[a⟨t−1⟩,x⟨t⟩]+bo)
a
⟨
t
⟩
=
Γ
o
⟨
t
⟩
⋅
t
a
n
h
(
c
⟨
t
⟩
)
a^{\left \langle t\right \rangle}=\Gamma_o^{\left \langle t\right \rangle}\cdot tanh(c^{\left \langle t\right \rangle})
a⟨t⟩=Γo⟨t⟩⋅tanh(c⟨t⟩)

前期知识储备
了解Memory Network
·本节讲解的记忆网络是基于facebook发表于2014年的Memory Networks这篇文章,希望大家了解一下这篇文章,参考链接:
https://arxiv.org/abs/1410.3916
https://zhuanlan.zhihu.com/p/29590286
第二课 论文精读
论文整体框架
摘要
1.介绍
2.模型
3.相关工作
4&5.实验(两个实验)
6.总结
传统/经典算法模型
记忆网络
- Convert x x x to an internal feature representation I ( x ) I(x) I(x).
- Update memories m i m_i mi given the new input: m i = G ( m i , I ( x ) , m ) , ∀ i m_i=G(m_i,I(x),m), \forall i mi=G(mi,I(x),m),∀i.
- Compute output features o o o given the new input and the memory: o = O ( I ( x ) , m ) o=O(I(x),m) o=O(I(x),m).
- Finally, decode output features
o
o
o to give the final response
:
r
=
R
(
o
)
:r=R(o)
:r=R(o).
本文的有两个实验其中一个实验是QA,将一系列句子作为输入,然后输入一个问题,要从输入的一系列句子中找到对应的答案。
上面的模型不是端对端的。因此对此进行了改进得到了端对端的记忆网络。
模型

有最左边的输入(Sentence),下面中间的Question,虚线上面中间部分的Answer几个部分。
首先将所有的Sentence(在语言模型中是一个个的词)enbedding A转化成一个个的向量,将Question用另外一个embedding B也转化为向量,将以上两个向量做内积得到一个结果p(相当于attention的方式),再用另外一个embedding C得到一个向量结果,将这个结果和p做内积后加权求和得到的结果结合上u(就是Question)一起来预测answer。以上是一次循环,还要做多次循环,因为一次循环中只是Sentence和Question进行交互,Sentence之间没有交互(忽略了Sentence之间的逻辑关系),因此这里做了迭代。
迭代过程就是上图中b的部分,每个蓝色和黄色模块就是对应上图中a的部分。具体的描述原文如下:

实验和结果
数据集
Facebook bAbl QA dataset:每条样本包含几句背景预料和一个问题,答案只有一个词。

Penn Tree Bank &Text8:两个文本预料,每个样本都是一句话。
实验结果
20种任务,第一列由于是强监督模型,不是端对端的,所以结果是最好的(错误率最低)。本文的模型对比都是是端到端模型LSTM来说效果提升是很明显的。

下面的结果表示模型可以准确预测与answer强相关的句子是哪几个(颜色越深相关性越强)
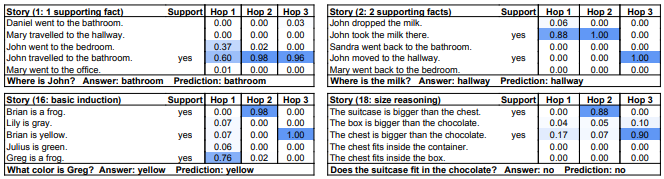
下面的结果中的hops代表模型一节中提到的迭代次数。

讨论和总结
本篇论文的主要贡献?
相对于之前的记忆网络,本篇论文提出的记忆网络是端对端模型。
本文提出的模型有何缺点?
句子与句子或者词与词之间的交互偏少。
后来的改进模型?
包含self-attention的众多模型。
主要创新:
A.提出了一种端对端的记忆网络模型。
B.基于提出的模型,设计各种巧妙的结构如position embedding。
C.在对话任务和语言模型上取得了非常好的结果。
参考文献
Jason Weston et al.Memory Networks. https://arxiv.org/pdf/1410.3916.pdf
















 6626
6626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











