






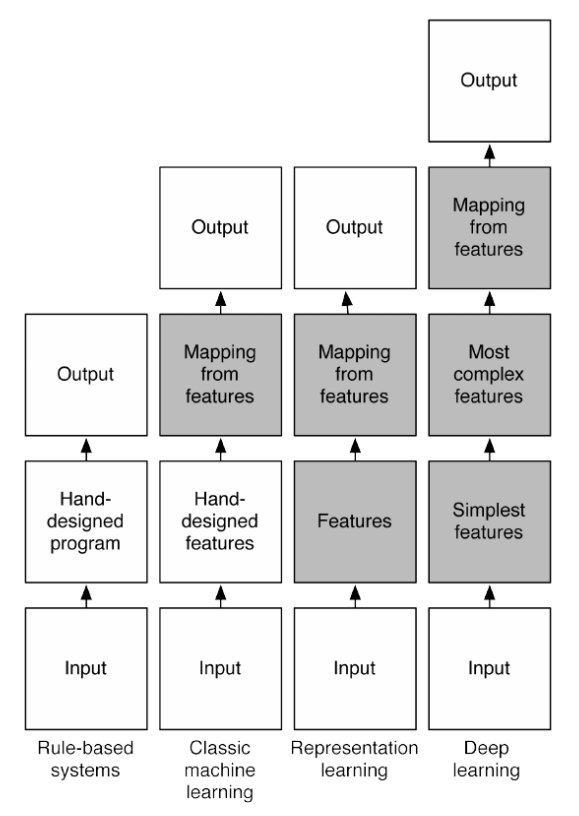
经典机器学习方式是以人类的先验知识将raw数据预处理成feature,然后对feature进行分类。分类结果十分取决于feature的好坏。
传统机器学习专家将大部分时间花费在设计feature上。那时的机器学习有个更合适的名字叫feature engineering 。
后来人们发现,利用神经网络,让网络自己学习如何抓取feature效果更佳。于是兴起了representation learning。这种方式对数据的拟合更加灵活。 网络进一步加深,多层次概念的representation learning将识别率达到了另一个新高度。
Deep learning 指多层次的特征提取器与识别器统一训练和预测的网络。
end to end的好处:通过缩减人工预处理和后续处理,尽可能使模型从原始输入到最终输出,给模型更多可以根据数据自动调节的空间,增加模型的整体契合度。
拿语音识别为具体实例。普遍方法是将语音信号转成频域信号,并可以进一步加工成符合人耳特点的MFCC进行编码(encode)。也可以选择Convolutional layers对频谱图进行特征抓取。这样可在encode的部分更接近end to end 中的第一个end。 但识别出的结果并不可以告诉我们这段语音到底是什么。DNN-HMM混合模型还需要将DNN识别出的结果通过HMM来解码(decode)。而RNN-CTC就将HMM的对齐工作交给了网络的output layer来实现。在decode的部分更接近end to end 中的第二个end。















 1684
1684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









