







文章目录
介绍
本门课程是2020年李宏毅老师新课:Deep Learning for Human Language Processing(深度学习与人类语言处理)
课程网站
B站视频
公式输入请参考:在线Latex公式
如果是普通的chatbot可以直接训练一个Seq2Seq模型就可以了:
存在的问题
但是难点在于如何让模型针对不同对象给出不同的回答:
The same input can have different response.

就连training data里面都可能包含一个输入,多种回答的情况,另外,不单单是chatbot,其他任务也有类似问题,例如TTS。当然类似语音识别任务就没有这样的困扰。
下面给几个具体的例子:
Inconsistent [Li, et al., ACL’16]

从这些对话里面可以看到,模型对于单个对话的问答是没有什么问题的,例如问地点,回答是地点,但是不同的问法,但是意思是一样的时候,模型给出的答案却不一样,逻辑上是讲不通的。
因此用大量的人类对话来训练模型,就会得到一个人格分裂的模型;
另外,使用一般的训练方法得到的模型往往会趋向回答简短无聊的句子,例如:我不知道。因为在语料库中可能我不知道这四个字出现频率最高,因此在用seq2seq预测的时候很容易就把这四个字祭出来。
因此,如果可以为chatbot弄一个人设persona、心情等。

Emotional Chatting Machine[Zhou, et al., AAAI’18]

Characters [Wang, et al., EMNLP’17]

法1:Directly Fine-tune
最简单,最直觉

就是在一个已经训练好的chatbot上面用少量数据进行微调(Fine-tuning with limited data is easy to overfit.),要实现少量数据的微调要用到MAAML: initial parameters only need a few dialogue samples to adapt.[Lin, et al., ACL’19]
法2:Control by Condition
例如在训练阶段,有如下输入:
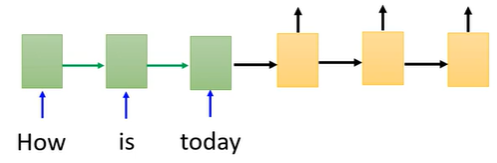
可能在语料库中有不同的回答:
Input: How is today?
Response: Today is awesome.
或者:
Input: How is today?
Response: Today is bad.
如果直接把这种语料丢给模型,模型可能在遇到同样问题的时候,可能会以50%的几率输出两个回答中的一个,因此要为语料的回答加上额外的标记:
Positive
Input: How is today?
Response: Today is awesome.
Negative
Input: How is today?
Response: Today is bad.
这个正负样例可以用另外一个模型来标记。加了标记之后的训练如下图所示:

当我们输入第一回答的时候,我们还会把正负信息也丢进模型,这里可以简单的用机器可以识别的独热编码即可。就是要模型看到How is today?的输入,且条件是1的时候,输出Today is awesome. 的几率越大越好,同理下面的例子中是要模型看到How is today?的输入,且条件是0的时候,输出Today is bad. 的几率越大越好

在test阶段,假如我们给模型吃I love you这句话,而且额外给一个条件0/1:

就会得到不同的response。
这个方法在16年有对应的文章:
Persona-based model
[Li, et al., ACL’16]

模型使用的语料是推特上爬下来的,因此每句话都有一个speaker,模型中的条件就是某个speaker,上图中很清楚的将speaker也用相应的向量进行表示,并将这个向量丢到模型中。下面是一些例子:


#代表回答有点问题。

Conditional Transformer Language model (CTRL)
[Keskar, et al., arXiv’19]
文章目的不是用来做chatbot,而是要控制模型生成序列。它使用的数据来自:

这个模型在训练时,吃不同序列,会把control code放在序列前面:
Books
w
1
w
2
w
3
⋯
\text{Books }w_1~w_2~w_3~\cdots
Books w1 w2 w3 ⋯
control code就是上面的不同的数据集的名称,如果某个序列是来自某个网页,那么就把control code设置为网址。
下面是原文的例子,给出的单词是 A knife:
Horror应该是redis论坛某个板块。

还有网址作为control code:

Corpus
这个方法对应的一个语料库叫:PERSONA-CHAT[Zhang, et al., ACL’18]
人设

带人设的对话实例

这个语料库是非死不可做的,先给出人设,然后找人按人设进行对话。
下面来看训练上面语料库的方法
TransferTransfo
[Wolf, et al., NeurIPS workshop’18]
这个模型解法非常简单粗暴,直接用BERT进行训练,可以看下图,模型直接把人设的内容作为数据,而且原文做的实验,如果有多个人设,丢进模型的顺序并不影响结果。使用不用顺序的人设句子进行训练还可以达到data augmentation的效果。
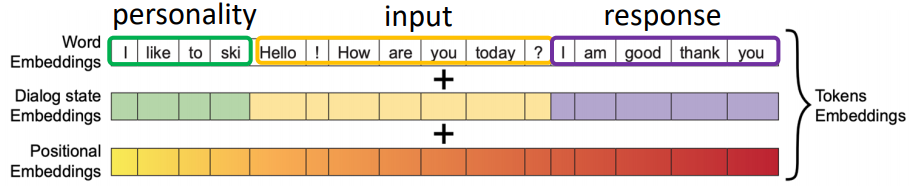
法3:Monologues Only
• The previous approaches need the dialogues with specific characteristics.
• What if we only have monologues
前面两种方法都是基于对话来进行训练的,但是很多时候有些角色很难收集到对话资料,例如,川普。但是川普的Monologues (发言,自言自语)很容易收集到,这个方法就是用Monologues来训练模型,使得模型能根据某个人的特点进行交谈:

具体做法有三种:
•Rank: selecting sentences from monologue as response限定模型输出response的时候要在指定的人设的monologue 中选择句子。
• Multiply:
Train a language model by monologue
Using the language model to influence chatbot response
monologue 没有办法训练对话,但是可以当做句子来训练LM,然后用LM来辅助chatbot做response,具体做法是在生成seq的时候用到beansearch的时候,用LM为微调search的结果。
• Pseudo Data:
这个方法有点妙~!,假如现有我们有川普的Monologue语料:
Make America great again.
I want to build a wall.
这个时候我们可以先训练一个反向chatbot,根据response预测问题:

于是得到:
What’s your goal in life?
Make America great again.
What do you want to do?
I want to build a wall.
这样就把Monologue语料变成了Dialogue语料。
然后就可以按正常的对话方法进行训练模型:

还有一个比较妙的方法:
[Luan, et al., IJCNLP’17]

这个模型上下两个部分,都是AE,下面是单独用Monologue的语料的训练的,上面就是一般的对话语料进行训练,根据颜色就可以知道,上下的Decoder是共享参数的,因此上面的AE在生成response的时候会倾向于使用下面的Monologue中的style。
再补充一个方法:(by RL or GAN)
先训练一个classifier(GAN就是相当于discriminator),可以判断一句话是否在Monologue中,这个很好训练,正样本就是Monologue语料的句子,负样本就是Monologue语料之外的句子。
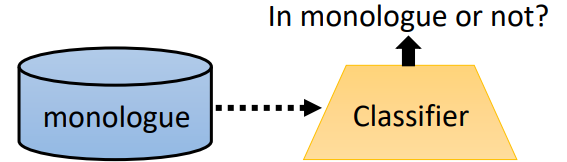
然后就可以开始训练了

这里如果是按RL的套路走,就是要把下面的Seq2Seq的输出丢到Classifier里面,Classifier会根据输入判断是否在Monologue中,如果在就会得到Reward,模型的目标就是要使得Reward越大越好。这里要注意,中间Seq2Seq的输出是discrete的,训练需要用到不可导的trick,这些在ML的课程里面有。
如果是按GAN的套路走,就是要把Classifier看做Discriminator,Seq2Seq的输出要骗过Classifier,上下两个模型都不断迭代update。
当然这里有一个问题,就是下面的Seq2Seq最后作弊,如果Monologue是川普,那么无论你的输入是什么,Seq2Seq都会输出Make America great again.这样虽然能通过上面的Classifier,但是这个回答明显是不符合逻辑的。
因此要对模型做一些限制:
• Constrain the amount of update更新不要太大
• Train a model to predict input from response额外加一个模型是的Seq2Seq输出要符合逻辑。具体可以参考CycleGAN,就是在Seq2Seq后面再接一个Encoder,使得Seq2Seq输出能够回溯原来的输入。
下面是具体的例子:原来输入:How is today,Seq2Seq得到的输出是Today is bad,但是得到classifier分数很低,要把它进行修改,由于我们有constraint,不能把Today is bad完全改掉,否则就不会符合原来句子的问答逻辑,因此模型可能会小改一个词,Today is good,这样又使得整个句子是positivie的效果,又使得原来的句子改动最小。

下面是参考文献中的一些DEMO:[Lee, et al., ICASSP, 2018]
Positive sentences
• Human: yeah, i’m just less interested in the how-to and more in the what and why of the things we build
• General Chat-bot: it’s not a good thing .
• Positive Chat-bot : it’s a good one
• Human: always learning and self improving is a huge turn on for me so believe me i understand
• General Chat-bot: i’m not sure if i can see you in a relationship
• Positive Chat-bot : i love you so much
另外一个例子:[Su, et al., INTERSPEECH’19]

还有用老友记的人设训练的结果:
https://adelaidehsu.github.io/Personalized-Dialogue-Response-Generation-learned-from-Monologues-demo/
Plug & Play Language Models
[Dathathri, et al., ICLR’20]

大的思想就是用小小的Attribute Model控制GPT-2的输出。

Attribute Model就是上面提到的Classifier,如上图所示,如果Attribute Model是一个情感类的模型,那么Attribute Model就会影响LM的Latents,也就是transformer你们的attention里面K和V,从而使得Attribute Model的值越大越好,如果是Positive sentiment那么语气越积极越好。下图中蓝色区域是大模型的等高线,红色箭头代表Attribute Model的值,模型最终目标是在蓝色区域中Attribute Model的值越大越好。

Next Step
当前的工作:
Control the response of chatbot
例如:

老是正面的回复有时候就变成了嘲讽了。
因此,我们想Control the response of interlocutor得到对话者正面的回复

Reference
•Yi Luan, Chris Brockett, Bill Dolan, Jianfeng Gao, Michel Galley, Multi-Task Learning for Speaker-Role Adaptation in Neural Conversation Models, IJCNLP, 2017
• Thomas Wolf, Victor Sanh, Julien Chaumond, Clement Delangue, TransferTransfo: A Transfer Learning Approach for Neural Network Based Conversational Agents, NeurIPS Workshop, 2018
• Di Wang, Nebojsa Jojic, Chris Brockett, Eric Nyberg, Steering Output Style and Topic in Neural Response Generation, EMNLP, 2017
• Zhaojiang Lin, Andrea Madotto, Chien-Sheng Wu, Pascale Fung, Personalizing Dialogue Agents via Meta-Learning, ACL, 2019
• Nitish Shirish Keskar, Bryan McCann, Lav R. Varshney, Caiming Xiong, Richard Socher, CTRL: A Conditional Transformer Language Model for Controllable Generation, arXiv, 2019
• Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, Jason Weston, Personalizing Dialogue Agents: I have a dog, do you have pets too?, ACL, 2018
• Feng-Guang Su, Aliyah Hsu, Yi-Lin Tuan and Hung-yi Lee, “Personalized Dialogue Response Generation Learned from Monologues”, INTERSPEECH, 2019 Reference
• Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, Rosanne Liu, Plug and Play Language Models: A Simple Approach to Controlled Text Generation, ICLR, 2020
• Jamin Shin, Peng Xu, Andrea Madotto, Pascale Fung, Generating Empathetic Responses by Looking Ahead the User’s Sentiment, ICASSP, 2020
• Hao Zhou, Minlie Huang, Tianyang Zhang, Xiaoyan Zhu, Bing Liu, Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memory, AAAI, 2018
• Jiwei Li, Michel Galley, Chris Brockett, Georgios Spithourakis, Jianfeng Gao, Bill Dolan, A Persona-Based Neural Conversation Model, ACL, 2016
















 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











