





The Guardian: A Robot Wrote This Entire Article. Are You Scared Yet, Human?
As the dialogue system is mature nowadays, we can download and apply advanced trained chatbots, such as GPT-3, DialoGPT, Plato and OpenNMT etc. However, building a chatbot with generating emotional and positive responses, unlike the traditional one, is still a hot research area. (Similiar to the AI mentioned in the news, we hope the AI says something positive (e.g. My creator told me to say ‘I come in peace’))
随着当今对话系统的成熟,我们可以下载并应用经过培训的高级聊天机器人 ,例如GPT-3 , DialoGPT , 柏拉图和OpenNMT等。但是,与传统的聊天机器人不同,构建能够产生情感和积极响应的聊天机器人仍然是一个挑战。研究热点。 (与新闻中提到的AI类似,我们希望AI能够说一些积极的话(例如,我的创作者告诉我说“我来和平”))
Also, an emotional chatbot is very desirable in business, such as improving customer service.
此外,情感聊天机器人在业务中非常可取,例如改善客户服务。
In these two articles, I am going to introduce how to build an emotional chatbot (deep neural network-based dialogue system) based on the paper “ HappyBot: Generating Empathetic Dialogue Responses by Improving User Experience Look-ahead” from HKUST and my trial.
在这两篇文章中,我将基于科大和我的试验,基于“ HappyBot:通过改善用户体验预见来生成移情对话响应 ”一文 ,介绍如何构建情感聊天机器人(基于深度神经网络的对话系统)。
The idea is to build a dialogue system combining reinforcement learning, which rewards the positive generated responses and penalizes the negative one.
这个想法是建立一个结合强化学习的对话系统,该系统奖励积极的React,并惩罚消极的React。
Techincal speaking, this task involves building a deep learning model, transfer learning (BERT), sentiment analysis, reinforcement learning and their implementations (in PyTorch), which are all the hot topics in machine learning.
从技术上讲,此任务涉及建立深度学习模型,迁移学习(BERT),情感分析,强化学习及其实现(在PyTorch中),这些都是机器学习中的热门话题。
微调的预训练BERT模型用于情感分析 (Fine-tunning pre-trained BERT model for sentiment analysis)
In part 1, we are going to build a sentiment predictor in a modern way (using transfer learning from a pre-trained BERT model).
在第1部分中,我们将以现代方式(使用来自预训练的BERT模型的转移学习)构建情绪预测器。
Recall our objective is: Build a dialogue system combining reinforcement learning, which rewards the positive generated responses and penalizes the negative one. Some we need a “judge” to decide a sentiment score of each generated sentence. (Sentiment analysis)
回想一下我们的目标是:建立一个结合强化学习的对话系统,奖励产生的积极回应,并惩罚消极回应。 有些我们需要一个“法官”来决定每个生成句子的情感分数。 ( 情感分析 )
BERT is currently one of the significant models in NLP tasks published in 2018 by Google. The key idea of BERT is to build the representation for natural language by using a bidirectional deep neural network with the Transformer architecture. The BERT model is frequently applied as a pre-trained model for other NLP tasks.
BERT目前是Google在2018年发布的NLP任务中的重要模型之一。 BERT的关键思想是通过使用具有Transformer架构的双向深度神经网络来构建自然语言的表示形式。 BERT模型经常用作其他NLP任务的预训练模型。
To build a BERT Sentiment predictor (by PyTorch), one can follow the article here: Part 2: BERT Fine-Tuning Tutorial with PyTorch for Text Classification on The Corpus of Linguistic Acceptability (COLA) Dataset.
要构建BERT情绪预测器(由PyTorch创建),可以在此处阅读以下文章: 第2部分:使用PyTorch进行BERT精调教程,以对语言可接受性(COLA)数据集进行文本分类。
斯坦福情感树库v2(SST2) (Stanford Sentiment Treebank v2 (SST2))
For our task, we use the Stanford Sentiment Treebank v2 (SST2) dataset, which can be downloaded here. The SST2 dataset provides 239,232 sentences, where each sentence contains at most 6 sentiment labels from 1 to 25 (from most negative to most positive). We calculated the mean sentiment score for each sentence and group them as ’negative’ (for the score ≤10), ’neutral’ (for the 10 < score ≤ 16) and ’positive’ (for the score >16). The final Train/Val/Test data was split as 50/25/25 per cent.
对于我们的任务,我们使用Stanford Sentiment Treebank v2(SST2)数据集 ,可在此处下载。 SST2数据集提供239,232个句子,其中每个句子最多包含6个从1到25(从最负面到最正面)的情感标签。 我们计算了每个句子的平均情感分数,并将其分为“否定”(分数≤10),“中性”(分数10≤≤16)和“肯定”(分数> 16)。 最终的Train / Val / Test数据分为50/25/25%。
构建BERT情感分类器 (Building the BERT Sentiment classifier)
Every sentence will be tokenized and the sentences with length larger than 160 words will be pruned. We use the prepared tokenizer from the package transformer.
每个句子将被标记,长度大于160个单词的句子将被修剪。 我们使用从包转换器准备的标记器。
Then we build a multi-class (positive, neutral and negative) classification model (softmax function) with loss function as cross-entropy from a pre-trained BERT model. Noted that we adopt the gradient clipping for avoiding gradient explosion. Here is the result of the train/valid data:
然后,我们从预训练的BERT模型中建立了具有损失函数作为交叉熵的多类(正,中性和负)分类模型(softmax函数)。 注意,我们采用了梯度剪裁以避免梯度爆炸。 这是火车/有效数据的结果:
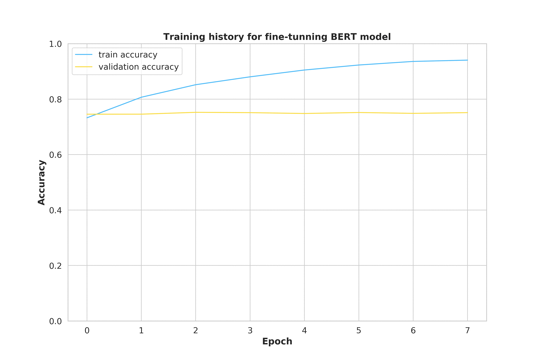
The model training indicates that one epoch is already adequate, while more epochs only improve the training accuracy but valid accuracy remains the same.
模型训练表明一个纪元已经足够,而更多的纪元只会提高训练的准确性,而有效的准确性则保持不变。
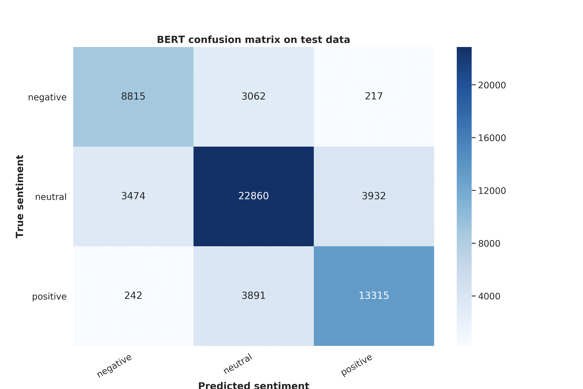
After the model training, we apply our model on the testing data with 75.2% accuracy (similar to our model training) :
在进行模型训练之后,我们将模型以75.2%的准确度应用于测试数据(类似于我们的模型训练):
Since our prediction is a probability of getting “positive”, “natural” and “negative” labels, we need to transform it into a 0–1 sentiment scores as the reward:
由于我们的预测是获得“正”,“自然”和“负”标签的可能性,因此我们需要将其转换为0-1分的情感分数作为奖励:
Sentiment score = 1*P(Positive) + 0.5*P(Natural) + 0*P(Negative)
情感分数= 1 * P(正)+ 0.5 * P(自然)+ 0 * P(负)
Where outputting 1 = highly positive and 0 = highly negative)
其中输出1 =高度正值,0 =高度负值)
Here are some examples:
这里有些例子:
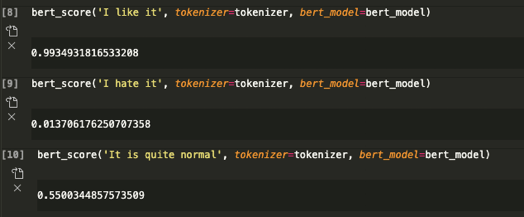
This result will be applied in the Emotional Dialogue system in the next part.
该结果将在下一部分的“情感对话”系统中应用。















 1024
1024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









