







收集整理了一份《2024年最新Python全套学习资料》免费送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来
如果你需要这些资料,可以添加V无偿获取:hxbc188 (备注666)

正文
(截至2019年3月份,TIOBE的Python编程社区指数走势图)
无论是人均面邀数还是平均年薪,Python工程师都排在较高的位置上。对于不同规模的企业来说,除了未融资和不需要融资的企业,Python程序员的薪资呈企业规模越大薪资越高的趋势,各个城市的互联网公司也开始纷纷招聘Python工程师。
从薪资报告和各城市薪资数据来看,Python工程师在当下的待遇挺不错。接下来请看Python工程师工资收入水平截图:
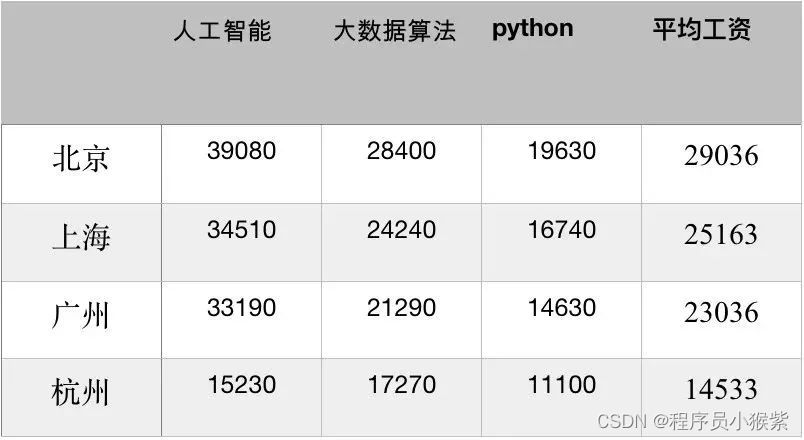
(以上为Python各方向薪资)

无论是想要升职加薪的销售、市场、运营、策划、产品、财务、法务、人事等职场人,还是想做专业数分师的毕业生或转行者,很多人都开始自发学习Python数据分析。
不言而喻,Python数据分析师可能将会是未来五年最稀缺最赚钱的职业。
Python岗位,以后端开发和架构为主,以算法和数据挖掘为辅,并有少量前端、全栈开发岗,以及运维等。

Python语言本身所具有的优势,决定了从事Python学习的开发工程师相较于其他编程语言,拥有更多岗位发展选择。
最后
作为一个IT的过来人,我自己整理了一些python学习资料,都是别人分享给我的,希望对你们有帮助。
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。
朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
如果你需要这些资料,可以添加V无偿获取:hxbc188 (备注666)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
8103)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 5910
5910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









