







 本文通过对上海二手房数据的分析,展示了数据清洗、特征工程和模型训练的过程。数据包括Region、House_area、Room、Floor、Levels和Year等特征。通过分析,发现区域、面积、房间数、楼层和建造年份对房价有显著影响。模型使用随机森林回归,得到约75%的解释度,面积是最重要的特征。
本文通过对上海二手房数据的分析,展示了数据清洗、特征工程和模型训练的过程。数据包括Region、House_area、Room、Floor、Levels和Year等特征。通过分析,发现区域、面积、房间数、楼层和建造年份对房价有显著影响。模型使用随机森林回归,得到约75%的解释度,面积是最重要的特征。
目的:本篇给大家介绍一个数据分析的初级项目,目的是通过项目了解如何使用Python进行简单的数据分析。
数据源:博主通过爬虫采集的安X客上海二手房数据,由于能力问题,只获取了2160条数据。
数据初探
首先导入要使用的科学计算包numpy,pandas,可视化matplotlib,seaborn
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
然后导入数据,并进行初步的观察,这些观察包括了解数据特征的缺失值,异常值,以及大概的描述性统计。
#coding:utf8
data=pd.read_csv('house_anjuke.csv',encoding='gbk')
data.head()
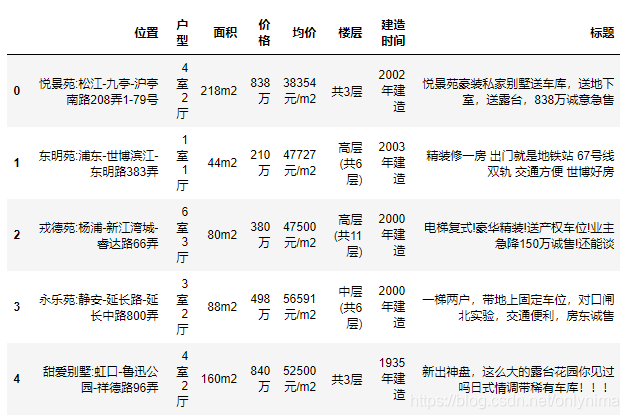
初步观察到一共有7个特征变量,价格在这里是我们的目标变量,然后我们继续深入观察一下。
检查缺失值:
data.info()
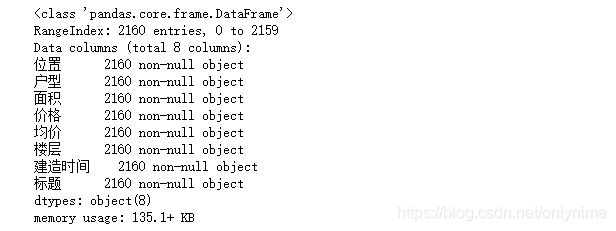
发现有2160条数据,没有缺失值。
提取有效信息:
data['region']=data['位置'].str.split(':').str[1].str.split('-').str[0]
data['district']=data['位置'].str.split(':').str[1].str.split('-').str[1].str.split('-').str[0]
data['name']=data['位置'].str.split(':').str[0]
data['house_area']=data['面积'].str.split('m').str[0]
data['room']=data['户型']
data['year']=data['建造时间'].str[:4]
data['floor']=data['楼层'].str.split("(").str[1].str.split(")").str[0]
data['levels']=data['楼层'].str.split("(").str[0]
data['house_price']=data['价格'].str[:-1]
data['per_square_price']=data['均价'].str[:-4]
这时候查看缺失值:
data.info()
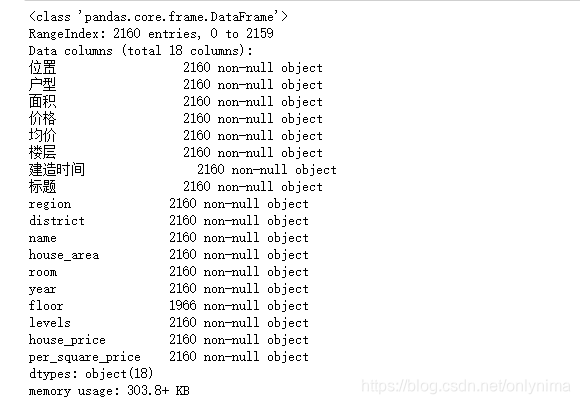
发现floor有很多缺失值,我们先用levels填充一下。
data['floor']=data['floor'].fillna(data['levels'])
清除脏数据:
del data['户型']
del data['位置']
del data['面积']
del data['价格']
del data['均价']
del data 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1918
1918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









