







 本文介绍了对MomentumContrastiveLearning(MoCo)的两个关键改进:使用非线性投影层和模糊增强,分别提升了模型精度。与SimCLR相比,MoCov2在ImageNet上的表现更优,尤其是在小批量训练和计算效率方面。
本文介绍了对MomentumContrastiveLearning(MoCo)的两个关键改进:使用非线性投影层和模糊增强,分别提升了模型精度。与SimCLR相比,MoCov2在ImageNet上的表现更优,尤其是在小批量训练和计算效率方面。
paper:Improved Baselines with Momentum Contrastive Learning
official implementation:https://github.com/facebookresearch/moco
这篇文章的内容只有2页,不能称之为paper,作者本人也称之为note。主要内容就是将SimCLR中的两点改进直接拿来用,作者发现它们和MoCo框架是“orthogonal”的关系,可以改进MoCo的效果并取得比SimCLR更好的精度。
第一个改进就是增加一个nonlinear projection layer,即将原始的全连接层用一个2层的MLP head替代,其中hidden layer的维度为2048,加一个ReLU层。改进后在默认的温度 \(\tau=0.07\) 下准确率从60.6%提升到了62.9%,切换到MLP最优的温度值 \(\tau=0.2\) 后,准确率进一步提升到了66.2%。

第二个改进是扩展增强方法,引入SimCLR中的模糊增强。如表1(b)所示,不用MLP,只增加blur增强将MoCo baseline在ImageNet上的精度提高了2.8%达到63.4%。有趣的是,单独添加模糊增强比单独添加MLP的检测精度要高,即表1(b) vs. 表1(a),AP 56.8% vs. 56.4%,但线性分类精度要低得多63.4% vs. 66.2%。这表明线性分类精度和迁移到检测中的性能不是单调相关的关系。组合MLP和模糊增强,将ImageNet的精度提高到了67.3%。

Comparison with SimCLR. 表2比较了SimCLR和MoCo v2的结果。为了公平比较,作者还研究了SimCLR使用余弦学习率策略的下过,见表1(d, e)。batch size采用256并训练200个epoch,MoCo v2在ImageNet上取得了67.5%的准确率,这比使用相同batch size并训练相同epoch的SimCLR高了5.6%,并比SimCLR采用大batch size的结果66.6%要高。当训练800个epoch时,MoCo v2达到了71.1%,高于SimCLR训练1000个epoch达到的69.3%。

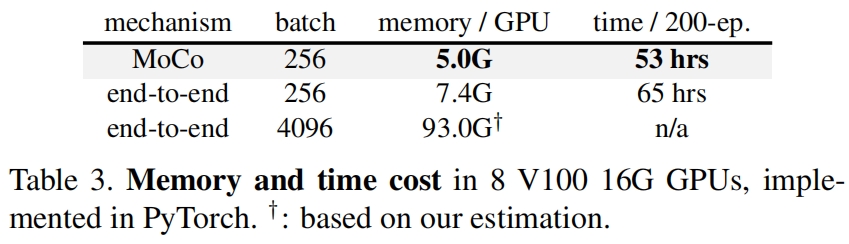
Computation cost. 表3展示了MoCo v2的内存和时间成本。end-to-end版本反映的是SimCLR在GPU上的成本,而不是原文在TPU上的。即使在高端的8-GPU机器上,4K的batch size也很难处理。在相同的256 batch size下,SimCLR的内存和时间成本也都更高,因为它同时反向传播到 \(q\) 和 \(k\) encoder,而MoCo只反向传播到 \(q\) encoder。
















 1217
1217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











