






目录
1、简介
对比学习的本质实际上是让两个相似(比如相同类别)的图像在特征空间内尽可能相近,不相似的图像尽可能远,这里相似的图像就是正样本,不相似的图像就是负样本。而如何区分正负样本对的方法就形成了各式各样的代理任务(pretext task)。那MoCo所用的代理任务就是个体判别了,每张图像都是单独的一类,在网络中只有原图经过数据增强后的图像属于原图的正样本,其他的图像都是负样本。
有了区分正负样本的方法后就是常规的,进入encoder提取特征,输出的特征用NCEloss进行反向传播,梯度下降。
2、MoCo
2.1、引言
无监督学习在nlp领域取得了巨大的成功,比如BERT、GPT等等,但是在cv领域还是有监督占据主流,效果更好。这可能是因为nlp天然是一个离散信号,不同的单词都可以表示为词汇表中的一类,相当于是一个分类任务。所以在nlp中,无监督学习容易去建模,优化。但是图像往往是连续,高维的信息,不想单词那样有很强的语义信息,所以不适合去tokenize建模。
MoCo把对比学习看作是一个动态字典的任务,他把锚点图像看作是一个query,将query与字典中的所有特征进行查询匹配,与正样本更加接近,与负样本远离。为了使字典中的k0,k1...与q能匹配上,字典的编码器是要一直随着锚点的编码器更新的,尽可能与锚点编码器相似,所以字典是动态的。
为了使对比学习结果更好,字典应该具有两个特性,一个是字典足够大,第二个是在训练时要保持尽可能的一致性。
(1)字典足够大才能学习到真正将正负样本区分开的特征。
(2)只有锚点的编码器和字典的编码器保持一致,才能让网络真正匹配到正样本。如果用了不同的编码器,那么q很有可能匹配到与q特征相似,但是匹配到的是负样本的情况。
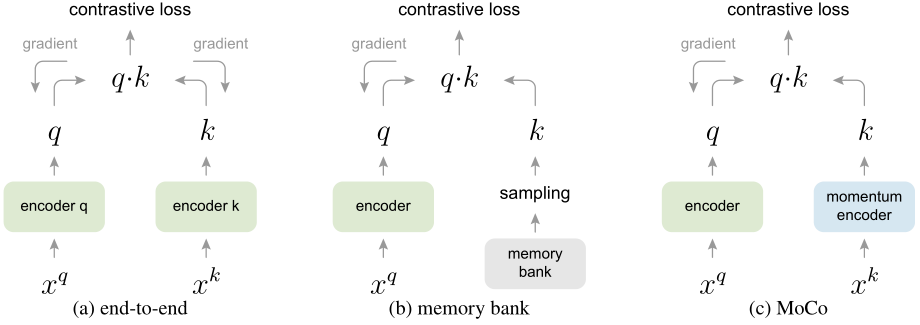
但是之前的自监督文章要么只关注字典的大小,忽略了一致性,比如Inst Disc。要么只关注一致性而忽略了字典的大小,比如SimCLR。
SimCLR如上图(a)所示,他是一个端到端的模型,所有编码器都可以通过梯度回传更新,模型直接从原始输入到最终输出,没有明确定义的中间步骤或子任务。这样可以保证所有正负样本都是从同一个编码器输出的特征,具有高度的一致性。但是缺点是负样本大小就是batchsize的大小。如果想要大的字典就需要大的batchsize,大的硬件支持,比如SimCLR的batchsize就为8192。并且大的batchsize会导致模型优化困难。
Inst Disc如上图(b)所示,他只具有一个编码器,其他所有样本的特征都存在memory bank中。Inst Disc的memory bank就包含了128万个特征,为了节省内存,每个特征是128维的。在前向过程中从memory bank中随机选取一部分作为负样本进行对比学习,然后用更新后的编码器去重新提取刚才负样本的特征放入memory bank中。但是这样会导致字典中的样本特征和q特征不一致(因为提取特征的编码器不同),导致训练结果产生偏差。
2.2、主要贡献
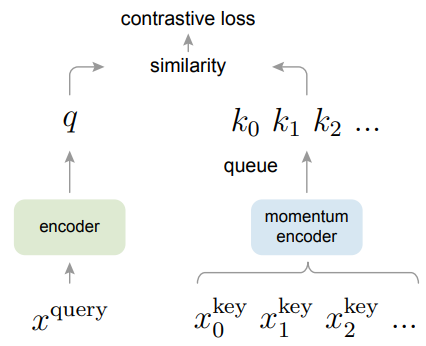
MoCo的主要改进在于做了一个动态的字典,其中包括一个队列和一个移动平均编码器,也就是动量编码器。
其中用队列表示字典,将字典的大小与batchsize大小的关系剥离开。比如你的batchsize只有32,但是你的队列就完全可以是batchsize大小的10倍大小,每次将新的特征传入字典中时,队列中最早的特征就会被踢出。因为队列不会进行梯度回传,所以队列可以放很多负样本,使字典变得很大。
![]()
动量编码器的表达式如上式所示,yt为该时刻输出,yt-1表示上一时刻输出,xt表示该时刻输入,m是动量权重,值在0~1之间。当m趋近于1时,表示该时刻输出更加依赖于上一时刻输出,趋近于0时,表示该时刻输出更依赖于该时刻输入。MoCo中,动量编码器是由锚点编码器初始化的,m选取的比较大,所以动量编码器变化的比较缓慢,目的是想让队列里的特征尽量都是由相同的编码器提取的,使特征保持一致性。
通过队列和动量编码器的设置,MoCo就可以创建一个又大又一致的字典了。
MoCo比较灵活,可以应用在很多代理任务上。在论文中主要采用了个体判别的任务,q和k是同一个图片的不同视角(不同数据增强),则认为是正样本。
2.3、相关工作
一般无监督的创新方式分为两种,一种是代理任务的创新,一种是目标函数的创新。MoCo就是目标函数的创新。
目标函数是测量模型预测的结果和固定目标之间的差异的。目标函数有生成式和判别式的。生成式就比如自编码器,重建图像,由原图作为标签,目标函数是L1loss或者L2loss。判别式就是类似分类任务,用交叉熵损失函数。
但是生成式和判别式的损失函数中,标签都是固定的值,原始图像或者类别标签。但是对比学习的目标函数的标签不是固定的。对比学习中的标签一般是正样本和负样本经过编码器提取的特征,由于编码器是不断变化的,所以特征值也是不断在变化的。
对抗性的目标函数也没有固定的值,比如GAN,衡量的是两个概率分布之间的差异。
有监督任务都是有ground truth标签的,通过模型输出预测的结果,通过目标函数来衡量输出和标签的差异。但是当数据集没有标签的时候怎么办呢?我们就通过代理任务生成一个自监督信号,去充当ground truth标签信息,通过特定的目标函数来衡量他们之间的差异。
2.4、方法
2.4.1、损失函数
我们想让q和正样本之间的loss尽量小,和负样本之间的loss尽量大。MoCo提出了InfoNCE。
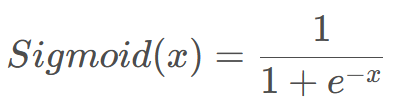
先来讲讲sigmoid函数,sigmoid函数可以看作一个二分类的结果,最后一层全连接神经元的个数为1,输出结果的取值范围是[0,1]。为什么是二分类的呢?因为只有当x=-x时,sigmoid函数相加为1。
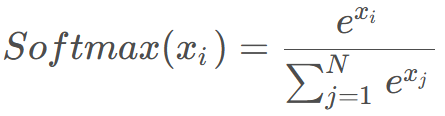
softmax是多分类的结果,每个输出值都可当成概率来理解,所有输出相加为1。
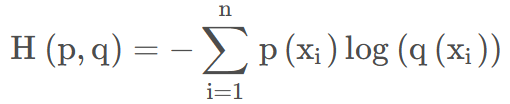
而交叉熵损失函数往往是和softmax函数一起使用的,其中p(x)表示one-hot标签,q(x)表示预测的值,范围为[0,1]。所以交叉熵损失的结果一般是-log(x),x表示输出某一类概率最大的值。
对比学习理论上来说是可以用交叉熵损失函数的,因为本质上对比学习属于一个多分类问题,字典中每一个图像都是一个类别。但是这样softmax是没法计算的,因为类别太多,还要对每个类别的输出归一化为概率,还要取指数和负对数,计算量爆炸。所以对比学习一般使用NCEloss。
NCEloss是将多分类问题转化为了二分类问题,分为数据和噪声两类。正样本就是数据类,负样本就是噪声类。并且如果对字典中每个输出都来计算二分类,计算量还是太大了,NCEloss就想在噪声类别(负样本)中进行采样,采样的结果再来计算二分类。
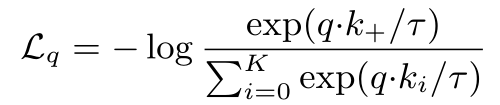
但是MoCo这篇论文认为,如果把所有负样本都看作噪声类也是不太合理的,因为负样本中也有与正样本相似的图像,所以提出了InfoNCEloss,如上式所示。分母的K表示负样本个数,i从0到K一共K+1个样本,其实这就是一个交叉熵损失函数加了一个温度系数tao。
2.4.2、队列
MoCo用队列的方式表示字典,将字典大小和batchsize大小的关系分离开,并且可以实时更新字典,使字典中的负样本特征尽量保持一致。
2.4.3、动量编码器
![]()
因为队列无法进行梯度回传,所以正负样本编码器无法更新。如果直接复制锚点编码器的话效果不太好,可能是因为这样的话队列中的特征就不一致了(因为是不同时刻编码器输出的特征)。所以MoCo采用了动量编码器,将m设为0.999,这样动量编码器变化的就非常缓慢,使队列中的特征保持一致性,效果非常好。
2.4.4、前向过程

上图是MoCo论文中前向过程的伪代码。
- 先随机初始化query编码器,然后将参数赋给key编码器。
- 从dataloader中取出mini-batch个图像,经过图像增强得到x_q和x_k,x_q作为锚点,x_k作为正样本。
- x_q和x_k经过编码器得到特征q(256*128)和k(256*128),k不进行梯度计算。
- 将q和k通过矩阵乘法计算正样本相似度l_pos(256*1)。
- 将队列中的负样本与q进行矩阵乘法得到负样本相似度l_neg(256*65536)。
- 将正负样本向量concat起来得到logits(256*65537)。
- 创建一个值为0,大小为batchsize的标签。因为concat时所有正样本都位于batch的第0个位置,所以可以直接用CEloss计算。至于详细的计算过程可以参考文章交叉熵函数Cross_EntropyLoss()的详细计算过程-CSDN博客
- 然后梯度回传,更新f_q编码器。
- 动量更新编码器f_k。
- 更新队列,将最新的mini-batch的特征放入队列,将旧的去除。
2.5、实验

MoCo实验细节如上图所示。
2.5.1、网络结构比较
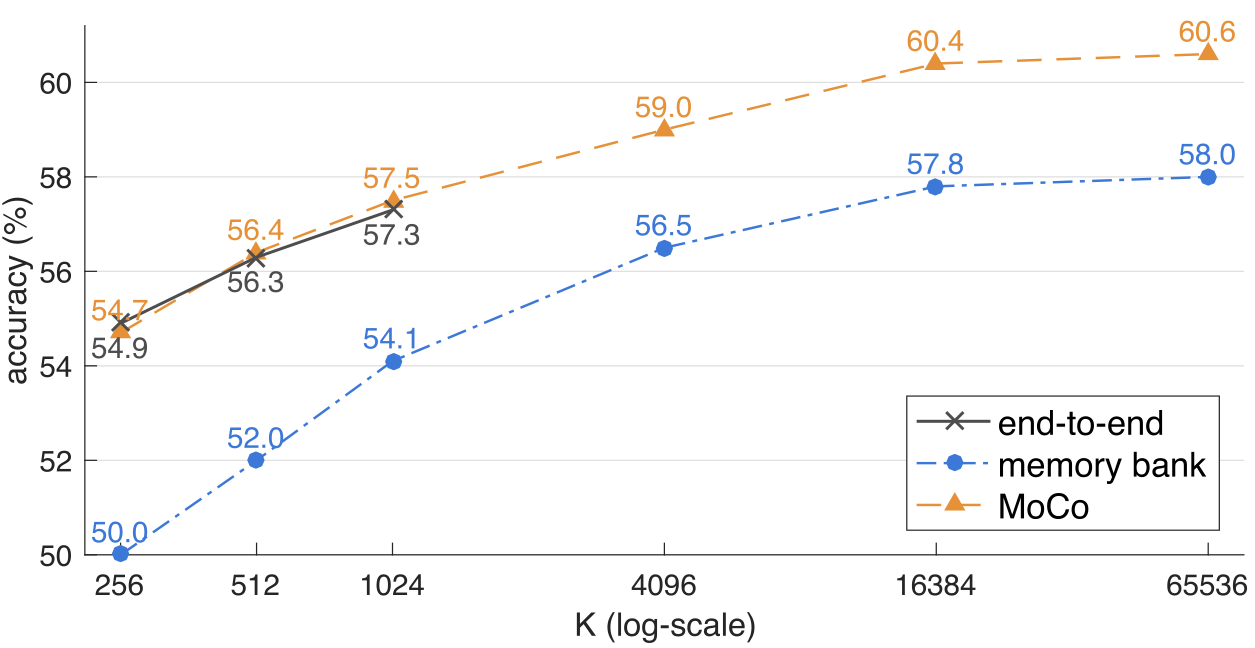
上图所示是三种自监督方法的比较,横坐标为负样本数量,纵坐标为精度。
2.5.2、动量参数m
![]()
上图证明,动量参数越大越好,动量编码器更新的越慢越好。
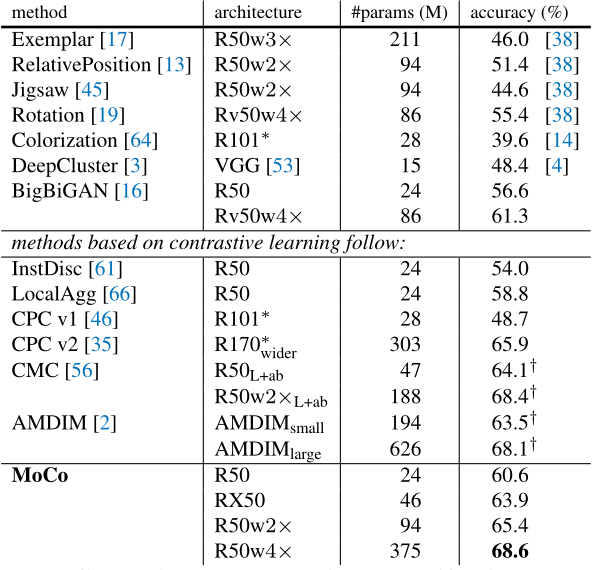
2.5.3、imageNet数据集结果
2.5.4、迁移特性
无监督学习最主要的目标就是去学习一个可以迁移的特征。是ImageNet影响力广泛最主要的原因就是在ImageNet上预训练的模型可以在下游任务上微调,从而使模型在数据集少的任务中也可以获得很好的效果。
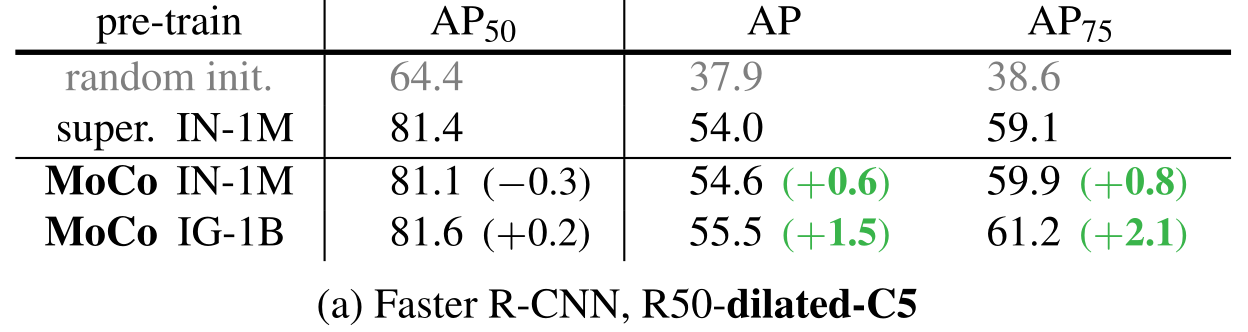
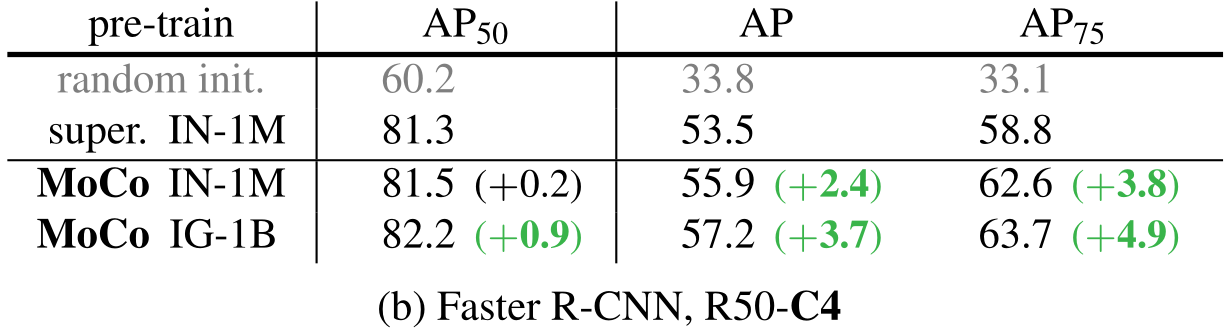
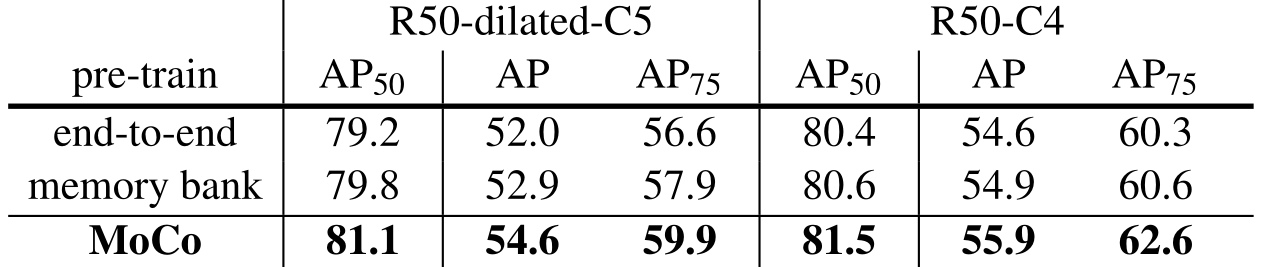
实验证明,在下游任务上,MoCo全面领先。
2.6、MoCo代码
官方代码链接:https://github.com/facebookresearch/moco
3、MoCov2
借鉴SimCLR加入了两个改进,一个是在Encoder后加入MLP层,一个是更加多样的数据增强。
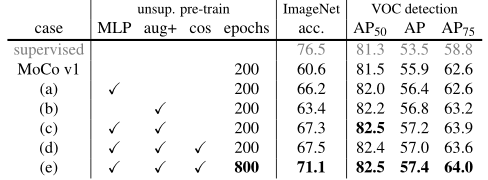
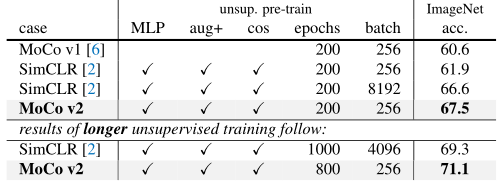
可以发现加入了MLP层之后,模型在ImageNet上的精度提升了将近6个点,效果非常显著。
4、MoCov3
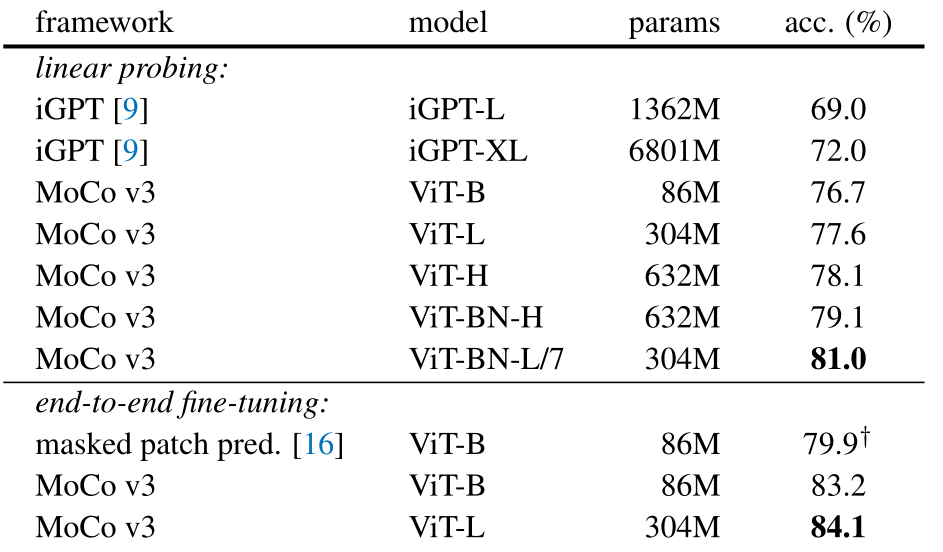
主要就是将baseline换成了ViT。然后针对训练不稳定的问题(训练曲线突然下降),提出了冻结patch projection层不训练,即我们使用固定的随机patch projection 层。
5、MoCov2训练代码
官方代码为GitHub - facebookresearch/moco: PyTorch implementation of MoCo: https://arxiv.org/abs/1911.05722
因为MoCo训练默认是单机多卡的训练方式,所以需要更改一些参数,使用单GPU训练自己的数据集。需要修改main_lincls.py、main_moco.py和moco文件下的builder.py。
5.1、builder.py
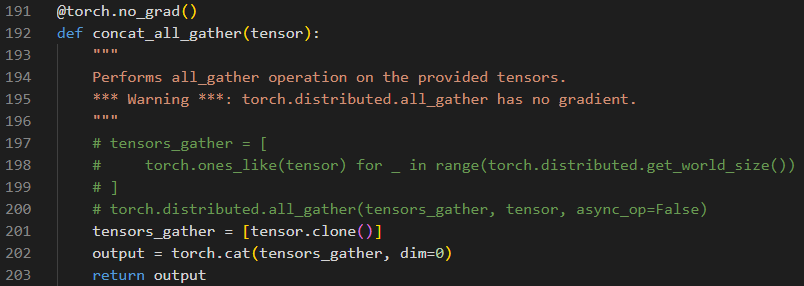
注释掉keys = concat_all_gather(keys)
注释掉im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k) 和 k = self._batch_unshuffle_ddp(k, idx_unshuffle)
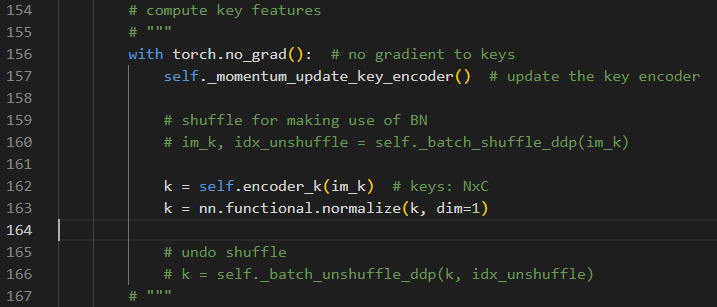
注释掉tensors_gather和torch.distributed.all_gather
5.2、main_moco.py
main_moco.py文件是自监督训练文件,输出一个预训练好的模型权重文件。如果需要改成单GPU训练可以更改以下地方。
(1)gpu的defult可以改为0。
![]()
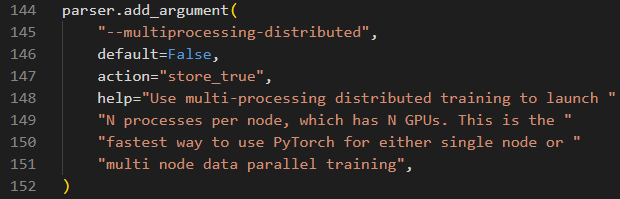
(2)分布式参数加入一个defult=False
(3)每个节点的GPU数改为1
![]()
(4)注释掉这句警告
![]()
5.3、main_lincls.py
main_lincls.py是利用自监督训练好的模型在下游任务上进行微调的代码。
(1)和上面一样改gpu
![]()
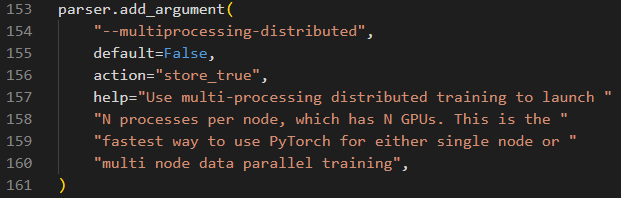
(2)改分布式的默认值
(3)改每个节点gpu数
![]()
5.4、注释后的代码
builder.py
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
import torch
import torch.nn as nn
class MoCo(nn.Module):
"""
Build a MoCo model with: a query encoder, a key encoder, and a queue
https://arxiv.org/abs/1911.05722
"""
def __init__(self, base_encoder, dim=128, K=65536, m=0.999, T=0.07, mlp=False):
"""
dim: feature dimension (default: 128)
K: queue size; number of negative keys (default: 65536)
m: moco momentum of updating key encoder (default: 0.999)
T: softmax temperature (default: 0.07)
"""
super(MoCo, self).__init__()
self.K = K
self.m = m
self.T = T
# create the encoders
# num_classes is the output fc dimension
# 两个编码器
self.encoder_q = base_encoder(num_classes=dim)
self.encoder_k = base_encoder(num_classes=dim)
# MoCov2有mlp层
if mlp: # hack: brute-force replacement
dim_mlp = self.encoder_q.fc.weight.shape[1]
self.encoder_q.fc = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_q.fc
)
self.encoder_k.fc = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_k.fc
)
# 将encoder_q的参数赋给encoder_k,并且encoder_k不进行反向传播
for param_q, param_k in zip(
self.encoder_q.parameters(), self.encoder_k.parameters()
):
param_k.data.copy_(param_q.data) # initialize
param_k.requires_grad = False # not update by gradient
# create the queue
# 创造队列字典
# dim为特征长度,k为队列长度
self.register_buffer("queue", torch.randn(dim, K))
self.queue = nn.functional.normalize(self.queue, dim=0)
# 创建一个队列指针
self.register_buffer("queue_ptr", torch.zeros(1, dtype=torch.long))
@torch.no_grad()
# 动量编码器的更新
def _momentum_update_key_encoder(self):
"""
Momentum update of the key encoder
"""
for param_q, param_k in zip(
self.encoder_q.parameters(), self.encoder_k.parameters()
):
param_k.data = param_k.data * self.m + param_q.data * (1.0 - self.m)
@torch.no_grad()
# 队列的特征添加与删除,用替换和指针实现
def _dequeue_and_enqueue(self, keys):
# gather keys before updating queue
# keys = concat_all_gather(keys)
batch_size = keys.shape[0]
ptr = int(self.queue_ptr)
assert self.K % batch_size == 0 # for simplicity
# replace the keys at ptr (dequeue and enqueue)
# 将队列前batchsize的特征替换成新特征
self.queue[:, ptr : ptr + batch_size] = keys.T
# 将队列指针移动到添加的新特征的尾部
ptr = (ptr + batch_size) % self.K # move pointer
# 更新指针位置,保证下一次替换的是最老的特征
self.queue_ptr[0] = ptr
@torch.no_grad()
# 打乱batch,防止网络由于BN操作学习到的全部样本的特征而走捷径
# 仅适用于单机多卡
def _batch_shuffle_ddp(self, x):
"""
Batch shuffle, for making use of BatchNorm.
*** Only support DistributedDataParallel (DDP) model. ***
"""
# gather from all gpus
batch_size_this = x.shape[0]
x_gather = concat_all_gather(x)
batch_size_all = x_gather.shape[0]
num_gpus = batch_size_all // batch_size_this
# random shuffle index
idx_shuffle = torch.randperm(batch_size_all).cuda()
# broadcast to all gpus
torch.distributed.broadcast(idx_shuffle, src=0)
# index for restoring
idx_unshuffle = torch.argsort(idx_shuffle)
# shuffled index for this gpu
gpu_idx = torch.distributed.get_rank()
idx_this = idx_shuffle.view(num_gpus, -1)[gpu_idx]
return x_gather[idx_this], idx_unshuffle
@torch.no_grad()
# 反打乱
def _batch_unshuffle_ddp(self, x, idx_unshuffle):
"""
Undo batch shuffle.
*** Only support DistributedDataParallel (DDP) model. ***
"""
# gather from all gpus
batch_size_this = x.shape[0]
x_gather = concat_all_gather(x)
batch_size_all = x_gather.shape[0]
num_gpus = batch_size_all // batch_size_this
# restored index for this gpu
gpu_idx = torch.distributed.get_rank()
idx_this = idx_unshuffle.view(num_gpus, -1)[gpu_idx]
return x_gather[idx_this]
# 前向过程
def forward(self, im_q, im_k):
"""
Input:
im_q: a batch of query images
im_k: a batch of key images
Output:
logits, targets
"""
# compute query features
q = self.encoder_q(im_q) # queries: NxC
q = nn.functional.normalize(q, dim=1)
# compute key features
# """
with torch.no_grad(): # no gradient to keys
self._momentum_update_key_encoder() # update the key encoder
# shuffle for making use of BN
# im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)
k = self.encoder_k(im_k) # keys: NxC
k = nn.functional.normalize(k, dim=1)
# undo shuffle
# k = self._batch_unshuffle_ddp(k, idx_unshuffle)
# """
# compute logits
# Einstein sum is more intuitive
# positive logits: Nx1
l_pos = torch.einsum("nc,nc->n", [q, k]).unsqueeze(-1)
# negative logits: NxK
l_neg = torch.einsum("nc,ck->nk", [q, self.queue.clone().detach()])
# logits: Nx(1+K)
logits = torch.cat([l_pos, l_neg], dim=1)
# apply temperature
logits /= self.T
# labels: positive key indicators
labels = torch.zeros(logits.shape[0], dtype=torch.long).cuda()
# dequeue and enqueue
self._dequeue_and_enqueue(k)
return logits, labels
# utils
@torch.no_grad()
def concat_all_gather(tensor):
"""
Performs all_gather operation on the provided tensors.
*** Warning ***: torch.distributed.all_gather has no gradient.
"""
# tensors_gather = [
# torch.ones_like(tensor) for _ in range(torch.distributed.get_world_size())
# ]
# torch.distributed.all_gather(tensors_gather, tensor, async_op=False)
tensors_gather = [tensor.clone()]
output = torch.cat(tensors_gather, dim=0)
return output
main_moco.py
#!/usr/bin/env python
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
import argparse
import builtins
import math
import os
import random
import shutil
import time
import warnings
import moco.builder
import moco.loader
import torch
import torch.backends.cudnn as cudnn
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.nn.parallel
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.datasets as datasets
import torchvision.models as models
import torchvision.transforms as transforms
model_names = sorted(
name
for name in models.__dict__
if name.islower() and not name.startswith("__") and callable(models.__dict__[name])
)
parser = argparse.ArgumentParser(description="PyTorch ImageNet Training")
parser.add_argument("--data", metavar="DIR", help="path to dataset")
parser.add_argument(
"-a",
"--arch",
metavar="ARCH",
default="resnet50",
choices=model_names,
help="model architecture: " + " | ".join(model_names) + " (default: resnet50)",
)
parser.add_argument(
"-j",
"--workers",
default=32,
type=int,
metavar="N",
help="number of data loading workers (default: 32)",
)
parser.add_argument(
"--epochs", default=200, type=int, metavar="N", help="number of total epochs to run"
)
parser.add_argument(
"--start-epoch",
default=0,
type=int,
metavar="N",
help="manual epoch number (useful on restarts)",
)
parser.add_argument(
"-b",
"--batch-size",
default=256,
type=int,
metavar="N",
help="mini-batch size (default: 256), this is the total "
"batch size of all GPUs on the current node when "
"using Data Parallel or Distributed Data Parallel",
)
parser.add_argument(
"--lr",
"--learning-rate",
default=0.03,
type=float,
metavar="LR",
help="initial learning rate",
dest="lr",
)
parser.add_argument(
"--schedule",
default=[120, 160],
nargs="*",
type=int,
help="learning rate schedule (when to drop lr by 10x)",
)
parser.add_argument(
"--momentum", default=0.9, type=float, metavar="M", help="momentum of SGD solver"
)
parser.add_argument(
"--wd",
"--weight-decay",
default=1e-4,
type=float,
metavar="W",
help="weight decay (default: 1e-4)",
dest="weight_decay",
)
parser.add_argument(
"-p",
"--print-freq",
default=10,
type=int,
metavar="N",
help="print frequency (default: 10)",
)
parser.add_argument(
"--resume",
default="",
type=str,
metavar="PATH",
help="path to latest checkpoint (default: none)",
)
parser.add_argument(
"--world-size",
default=-1,
type=int,
help="number of nodes for distributed training",
)
parser.add_argument(
"--rank", default=-1, type=int, help="node rank for distributed training"
)
parser.add_argument(
"--dist-url",
default="tcp://224.66.41.62:23456",
type=str,
help="url used to set up distributed training",
)
parser.add_argument(
"--dist-backend", default="nccl", type=str, help="distributed backend"
)
parser.add_argument(
"--seed", default=None, type=int, help="seed for initializing training. "
)
# parser.add_argument("--gpu", default=None, type=int, help="GPU id to use.")
parser.add_argument("--gpu", default=0, type=int, help="GPU id to use.")
parser.add_argument(
"--multiprocessing-distributed",
default=False,
action="store_true",
help="Use multi-processing distributed training to launch "
"N processes per node, which has N GPUs. This is the "
"fastest way to use PyTorch for either single node or "
"multi node data parallel training",
)
# moco specific configs:
# 提取的特征维度
parser.add_argument(
"--moco-dim", default=128, type=int, help="feature dimension (default: 128)"
)
# 队列字典大小
parser.add_argument(
"--moco-k",
default=65536,
type=int,
help="queue size; number of negative keys (default: 65536)",
)
# 动量编码器的动量参数设置
parser.add_argument(
"--moco-m",
default=0.999,
type=float,
help="moco momentum of updating key encoder (default: 0.999)",
)
# 损失函数温度设置
parser.add_argument(
"--moco-t", default=0.07, type=float, help="softmax temperature (default: 0.07)"
)
# options for moco v2
# MoCo中添加了mlp层、数据增强和余弦学习率
parser.add_argument("--mlp", action="store_true", help="use mlp head")
parser.add_argument(
"--aug-plus", action="store_true", help="use moco v2 data augmentation"
)
parser.add_argument("--cos", action="store_true", help="use cosine lr schedule")
def main():
args = parser.parse_args()
if args.seed is not None:
random.seed(args.seed)
torch.manual_seed(args.seed)
cudnn.deterministic = True
warnings.warn(
"You have chosen to seed training. "
"This will turn on the CUDNN deterministic setting, "
"which can slow down your training considerably! "
"You may see unexpected behavior when restarting "
"from checkpoints."
)
if args.gpu is not None:
warnings.warn(
"You have chosen a specific GPU. This will completely "
"disable data parallelism."
)
if args.dist_url == "env://" and args.world_size == -1:
args.world_size = int(os.environ["WORLD_SIZE"])
args.distributed = args.world_size > 1 or args.multiprocessing_distributed
# ngpus_per_node = torch.cuda.device_count()
ngpus_per_node = 1
if args.multiprocessing_distributed:
# Since we have ngpus_per_node processes per node, the total world_size
# needs to be adjusted accordingly
args.world_size = ngpus_per_node * args.world_size
# Use torch.multiprocessing.spawn to launch distributed processes: the
# main_worker process function
mp.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, args))
else:
# Simply call main_worker function
main_worker(args.gpu, ngpus_per_node, args)
def main_worker(gpu, ngpus_per_node, args):
args.gpu = gpu
# suppress printing if not master
if args.multiprocessing_distributed and args.gpu != 0:
def print_pass(*args):
pass
builtins.print = print_pass
if args.gpu is not None:
print("Use GPU: {} for training".format(args.gpu))
if args.distributed:
if args.dist_url == "env://" and args.rank == -1:
args.rank = int(os.environ["RANK"])
if args.multiprocessing_distributed:
# For multiprocessing distributed training, rank needs to be the
# global rank among all the processes
args.rank = args.rank * ngpus_per_node + gpu
dist.init_process_group(
backend=args.dist_backend,
init_method=args.dist_url,
world_size=args.world_size,
rank=args.rank,
)
# create model
print("=> creating model '{}'".format(args.arch))
model = moco.builder.MoCo(
models.__dict__[args.arch],
args.moco_dim,
args.moco_k,
args.moco_m,
args.moco_t,
args.mlp,
)
print(model)
if args.distributed:
# For multiprocessing distributed, DistributedDataParallel constructor
# should always set the single device scope, otherwise,
# DistributedDataParallel will use all available devices.
if args.gpu is not None:
torch.cuda.set_device(args.gpu)
model.cuda(args.gpu)
# When using a single GPU per process and per
# DistributedDataParallel, we need to divide the batch size
# ourselves based on the total number of GPUs we have
args.batch_size = int(args.batch_size / ngpus_per_node)
args.workers = int((args.workers + ngpus_per_node - 1) / ngpus_per_node)
model = torch.nn.parallel.DistributedDataParallel(
model, device_ids=[args.gpu]
)
else:
model.cuda()
# DistributedDataParallel will divide and allocate batch_size to all
# available GPUs if device_ids are not set
model = torch.nn.parallel.DistributedDataParallel(model)
elif args.gpu is not None:
torch.cuda.set_device(args.gpu)
model = model.cuda(args.gpu)
# comment out the following line for debugging
# raise NotImplementedError("Only DistributedDataParallel is supported.")
else:
# AllGather implementation (batch shuffle, queue update, etc.) in
# this code only supports DistributedDataParallel.
raise NotImplementedError("Only DistributedDataParallel is supported.")
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(args.gpu)
optimizer = torch.optim.SGD(
model.parameters(),
args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay,
)
# optionally resume from a checkpoint
if args.resume:
if os.path.isfile(args.resume):
print("=> loading checkpoint '{}'".format(args.resume))
if args.gpu is None:
checkpoint = torch.load(args.resume)
else:
# Map model to be loaded to specified single gpu.
loc = "cuda:{}".format(args.gpu)
checkpoint = torch.load(args.resume, map_location=loc)
args.start_epoch = checkpoint["epoch"]
model.load_state_dict(checkpoint["state_dict"])
optimizer.load_state_dict(checkpoint["optimizer"])
print(
"=> loaded checkpoint '{}' (epoch {})".format(
args.resume, checkpoint["epoch"]
)
)
else:
print("=> no checkpoint found at '{}'".format(args.resume))
cudnn.benchmark = True
# Data loading code
traindir = os.path.join(args.data, "train")
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
)
if args.aug_plus:
# MoCo v2's aug: similar to SimCLR https://arxiv.org/abs/2002.05709
augmentation = [
transforms.RandomResizedCrop(224, scale=(0.2, 1.0)),
transforms.RandomApply(
[transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)], p=0.8 # not strengthened
),
transforms.RandomGrayscale(p=0.2),
transforms.RandomApply([moco.loader.GaussianBlur([0.1, 2.0])], p=0.5),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]
else:
# MoCo v1's aug: the same as InstDisc https://arxiv.org/abs/1805.01978
augmentation = [
transforms.RandomResizedCrop(224, scale=(0.2, 1.0)),
transforms.RandomGrayscale(p=0.2),
transforms.ColorJitter(0.4, 0.4, 0.4, 0.4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]
train_dataset = datasets.ImageFolder(
traindir, moco.loader.TwoCropsTransform(transforms.Compose(augmentation))
)
if args.distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
else:
train_sampler = None
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=args.batch_size,
shuffle=(train_sampler is None),
num_workers=args.workers,
pin_memory=True,
sampler=train_sampler,
drop_last=True,
)
for epoch in range(args.start_epoch, args.epochs):
if args.distributed:
train_sampler.set_epoch(epoch)
adjust_learning_rate(optimizer, epoch, args)
# train for one epoch
train(train_loader, model, criterion, optimizer, epoch, args)
if not args.multiprocessing_distributed or (
args.multiprocessing_distributed and args.rank % ngpus_per_node == 0
):
save_checkpoint(
{
"epoch": epoch + 1,
"arch": args.arch,
"state_dict": model.state_dict(),
"optimizer": optimizer.state_dict(),
},
is_best=False,
filename="checkpoint_{:04d}.pth.tar".format(epoch),
)
def train(train_loader, model, criterion, optimizer, epoch, args):
batch_time = AverageMeter("Time", ":6.3f")
data_time = AverageMeter("Data", ":6.3f")
losses = AverageMeter("Loss", ":.4e")
top1 = AverageMeter("Acc@1", ":6.2f")
top5 = AverageMeter("Acc@5", ":6.2f")
progress = ProgressMeter(
len(train_loader),
[batch_time, data_time, losses, top1, top5],
prefix="Epoch: [{}]".format(epoch),
)
# switch to train mode
model.train()
end = time.time()
for i, (images, _) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
if args.gpu is not None:
images[0] = images[0].cuda(args.gpu, non_blocking=True)
images[1] = images[1].cuda(args.gpu, non_blocking=True)
# compute output
output, target = model(im_q=images[0], im_k=images[1])
loss = criterion(output, target)
# acc1/acc5 are (K+1)-way contrast classifier accuracy
# measure accuracy and record loss
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), images[0].size(0))
top1.update(acc1[0], images[0].size(0))
top5.update(acc5[0], images[0].size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
progress.display(i)
def save_checkpoint(state, is_best, filename="checkpoint.pth.tar"):
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, "model_best.pth.tar")
class AverageMeter:
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=":f"):
self.name = name
self.fmt = fmt
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def __str__(self):
fmtstr = "{name} {val" + self.fmt + "} ({avg" + self.fmt + "})"
return fmtstr.format(**self.__dict__)
class ProgressMeter:
def __init__(self, num_batches, meters, prefix=""):
self.batch_fmtstr = self._get_batch_fmtstr(num_batches)
self.meters = meters
self.prefix = prefix
def display(self, batch):
entries = [self.prefix + self.batch_fmtstr.format(batch)]
entries += [str(meter) for meter in self.meters]
print("\t".join(entries))
def _get_batch_fmtstr(self, num_batches):
num_digits = len(str(num_batches // 1))
fmt = "{:" + str(num_digits) + "d}"
return "[" + fmt + "/" + fmt.format(num_batches) + "]"
def adjust_learning_rate(optimizer, epoch, args):
"""Decay the learning rate based on schedule"""
lr = args.lr
if args.cos: # cosine lr schedule
lr *= 0.5 * (1.0 + math.cos(math.pi * epoch / args.epochs))
else: # stepwise lr schedule
for milestone in args.schedule:
lr *= 0.1 if epoch >= milestone else 1.0
for param_group in optimizer.param_groups:
param_group["lr"] = lr
def accuracy(output, target, topk=(1,)):
"""Computes the accuracy over the k top predictions for the specified values of k"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
if __name__ == "__main__":
main()
main_lincls.py
#!/usr/bin/env python
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
import argparse
import builtins
import os
import random
import shutil
import time
import warnings
import torch
import torch.backends.cudnn as cudnn
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.nn.parallel
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.datasets as datasets
import torchvision.models as models
import torchvision.transforms as transforms
model_names = sorted(
name
for name in models.__dict__
if name.islower() and not name.startswith("__") and callable(models.__dict__[name])
)
parser = argparse.ArgumentParser(description="PyTorch ImageNet Training")
# 数据集路径
parser.add_argument("--data", default="D:\\experiments\\experiment\\dataset\\air_resize_split", metavar="DIR", help="path to dataset")
# 选择模型,默认resnet50
parser.add_argument(
"-a",
"--arch",
metavar="ARCH",
default="resnet50",
choices=model_names,
help="model architecture: " + " | ".join(model_names) + " (default: resnet50)",
)
parser.add_argument(
"-j",
"--workers",
default=1,
type=int,
metavar="N",
help="number of data loading workers (default: 32)",
)
parser.add_argument(
"--epochs", default=100, type=int, metavar="N", help="number of total epochs to run"
)
parser.add_argument(
"--start-epoch",
default=0,
type=int,
metavar="N",
help="manual epoch number (useful on restarts)",
)
parser.add_argument(
"-b",
"--batch-size",
default=32,
type=int,
metavar="N",
help="mini-batch size (default: 256), this is the total "
"batch size of all GPUs on the current node when "
"using Data Parallel or Distributed Data Parallel",
)
parser.add_argument(
"--lr",
"--learning-rate",
default=30.0,
type=float,
metavar="LR",
help="initial learning rate",
dest="lr",
)
# 设置降低学习率的时机
parser.add_argument(
"--schedule",
default=[60, 80],
nargs="*",
type=int,
help="learning rate schedule (when to drop lr by a ratio)",
)
# 动量
parser.add_argument("--momentum", default=0.9, type=float, metavar="M", help="momentum")
parser.add_argument(
"--wd",
"--weight-decay",
default=0.0,
type=float,
metavar="W",
help="weight decay (default: 0.)",
dest="weight_decay",
)
parser.add_argument(
"-p",
"--print-freq",
default=10,
type=int,
metavar="N",
help="print frequency (default: 10)",
)
parser.add_argument(
"--resume",
default="",
type=str,
metavar="PATH",
help="path to latest checkpoint (default: none)",
)
parser.add_argument(
"-e",
"--evaluate",
dest="evaluate",
action="store_true",
help="evaluate model on validation set",
)
# 分布式训练的节点数
parser.add_argument(
"--world-size",
default=-1,
type=int,
help="number of nodes for distributed training",
)
# 分布式训练的节点等级
parser.add_argument(
"--rank", default=-1, type=int, help="node rank for distributed training"
)
# 用于设置分布式培训的网址gpu
parser.add_argument(
"--dist-url",
default="tcp://224.66.41.62:23456",
type=str,
help="url used to set up distributed training",
)
# distributed backend
parser.add_argument(
"--dist-backend", default="nccl", type=str, help="distributed backend"
)
parser.add_argument(
"--seed", default=None, type=int, help="seed for initializing training. "
)
# parser.add_argument("--gpu", default=None, type=int, help="GPU id to use.")
parser.add_argument("--gpu", default=0, type=int, help="GPU id to use.")
parser.add_argument(
"--multiprocessing-distributed",
default=False,
action="store_true",
help="Use multi-processing distributed training to launch "
"N processes per node, which has N GPUs. This is the "
"fastest way to use PyTorch for either single node or "
"multi node data parallel training",
)
# 预训练模型路径
parser.add_argument(
"--pretrained", default="D:\\experiments\\experiment\\pretrain_weights\\moco_v2_800ep_pretrain.pth.tar", type=str, help="path to moco pretrained checkpoint"
)
best_acc1 = 0
def main():
args = parser.parse_args()
if args.seed is not None:
random.seed(args.seed)
torch.manual_seed(args.seed)
# 设置 CuDNN 的确定性行为,相同的输入和相同的参数,CuDNN 将产生相同的输出。
cudnn.deterministic = True
warnings.warn(
"You have chosen to seed training. "
"This will turn on the CUDNN deterministic setting, "
"which can slow down your training considerably! "
"You may see unexpected behavior when restarting "
"from checkpoints."
)
if args.gpu is not None:
warnings.warn(
"You have chosen a specific GPU. This will completely "
"disable data parallelism."
)
if args.dist_url == "env://" and args.world_size == -1:
args.world_size = int(os.environ["WORLD_SIZE"])
# 分布式训练
args.distributed = args.world_size > 1 or args.multiprocessing_distributed
# 获取GPU数量(即每个节点的GPU数量)
# ngpus_per_node = torch.cuda.device_count()
ngpus_per_node = 0
if args.multiprocessing_distributed:
# Since we have ngpus_per_node processes per node, the total world_size
# needs to be adjusted accordingly
args.world_size = ngpus_per_node * args.world_size
# Use torch.multiprocessing.spawn to launch distributed processes: the
# main_worker process function
mp.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, args))
else:
# Simply call main_worker function
main_worker(args.gpu, ngpus_per_node, args)
def main_worker(gpu, ngpus_per_node, args):
global best_acc1
args.gpu = gpu
# suppress printing if not master
if args.multiprocessing_distributed and args.gpu != 0:
def print_pass(*args):
pass
builtins.print = print_pass
if args.gpu is not None:
print("Use GPU: {} for training".format(args.gpu))
if args.distributed:
if args.dist_url == "env://" and args.rank == -1:
args.rank = int(os.environ["RANK"])
if args.multiprocessing_distributed:
# For multiprocessing distributed training, rank needs to be the
# global rank among all the processes
args.rank = args.rank * ngpus_per_node + gpu
dist.init_process_group(
backend=args.dist_backend,
init_method=args.dist_url,
world_size=args.world_size,
rank=args.rank,
)
# create model
print("=> creating model '{}'".format(args.arch))
model = models.__dict__[args.arch]()
# freeze all layers but the last fc
for name, param in model.named_parameters():
if name not in ["fc.weight", "fc.bias"]:
param.requires_grad = False
# init the fc layer
model.fc.weight.data.normal_(mean=0.0, std=0.01)
model.fc.bias.data.zero_()
# load from pre-trained, before DistributedDataParallel constructor
if args.pretrained:
if os.path.isfile(args.pretrained):
print("=> loading checkpoint '{}'".format(args.pretrained))
checkpoint = torch.load(args.pretrained, map_location="cpu")
# rename moco pre-trained keys
state_dict = checkpoint["state_dict"]
for k in list(state_dict.keys()):
# retain only encoder_q up to before the embedding layer
if k.startswith("module.encoder_q") and not k.startswith(
"module.encoder_q.fc"
):
# remove prefix
# 修改后的代码
state_dict[k[len("module.encoder_q.") :]] = state_dict[k]
# delete renamed or unused k
del state_dict[k]
args.start_epoch = 0
msg = model.load_state_dict(state_dict, strict=False)
# .missing_keys返回的是被删除的键或元素
assert set(msg.missing_keys) == {"fc.weight", "fc.bias"}
print("=> loaded pre-trained model '{}'".format(args.pretrained))
else:
print("=> no checkpoint found at '{}'".format(args.pretrained))
# 初始化CUDA
torch.cuda.init()
if args.distributed:
# For multiprocessing distributed, DistributedDataParallel constructor
# should always set the single device scope, otherwise,
# DistributedDataParallel will use all available devices.
if args.gpu is not None:
torch.cuda.set_device(args.gpu)
model.cuda(args.gpu)
# When using a single GPU per process and per
# DistributedDataParallel, we need to divide the batch size
# ourselves based on the total number of GPUs we have
args.batch_size = int(args.batch_size / ngpus_per_node)
args.workers = int((args.workers + ngpus_per_node - 1) / ngpus_per_node)
model = torch.nn.parallel.DistributedDataParallel(
model, device_ids=[args.gpu]
)
else:
model.cuda()
# DistributedDataParallel will divide and allocate batch_size to all
# available GPUs if device_ids are not set
model = torch.nn.parallel.DistributedDataParallel(model)
elif args.gpu is not None:
torch.cuda.set_device(args.gpu)
model = model.cuda(args.gpu)
else:
# DataParallel will divide and allocate batch_size to all available GPUs
if args.arch.startswith("alexnet") or args.arch.startswith("vgg"):
model.features = torch.nn.DataParallel(model.features)
model.cuda()
else:
model = torch.nn.DataParallel(model).cuda()
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(args.gpu)
# optimize only the linear classifier
parameters = list(filter(lambda p: p.requires_grad, model.parameters()))
assert len(parameters) == 2 # fc.weight, fc.bias
optimizer = torch.optim.SGD(
parameters, args.lr, momentum=args.momentum, weight_decay=args.weight_decay
)
# optionally resume from a checkpoint
if args.resume:
if os.path.isfile(args.resume):
print("=> loading checkpoint '{}'".format(args.resume))
if args.gpu is None:
checkpoint = torch.load(args.resume)
else:
# Map model to be loaded to specified single gpu.
loc = "cuda:{}".format(args.gpu)
checkpoint = torch.load(args.resume, map_location=loc)
args.start_epoch = checkpoint["epoch"]
best_acc1 = checkpoint["best_acc1"]
if args.gpu is not None:
# best_acc1 may be from a checkpoint from a different GPU
best_acc1 = best_acc1.to(args.gpu)
model.load_state_dict(checkpoint["state_dict"])
optimizer.load_state_dict(checkpoint["optimizer"])
print(
"=> loaded checkpoint '{}' (epoch {})".format(
args.resume, checkpoint["epoch"]
)
)
else:
print("=> no checkpoint found at '{}'".format(args.resume))
cudnn.benchmark = True
# Data loading code
traindir = os.path.join(args.data, "train")
valdir = os.path.join(args.data, "val")
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
)
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]
),
)
if args.distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
else:
train_sampler = None
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=args.batch_size,
shuffle=(train_sampler is None),
num_workers=args.workers,
pin_memory=True,
sampler=train_sampler,
)
val_loader = torch.utils.data.DataLoader(
datasets.ImageFolder(
valdir,
transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]
),
),
batch_size=args.batch_size,
shuffle=False,
num_workers=args.workers,
pin_memory=True,
)
if args.evaluate:
validate(val_loader, model, criterion, args)
return
for epoch in range(args.start_epoch, args.epochs):
if args.distributed:
train_sampler.set_epoch(epoch)
adjust_learning_rate(optimizer, epoch, args)
# train for one epoch
train(train_loader, model, criterion, optimizer, epoch, args)
# evaluate on validation set
acc1 = validate(val_loader, model, criterion, args)
# remember best acc@1 and save checkpoint
is_best = acc1 > best_acc1
best_acc1 = max(acc1, best_acc1)
if not args.multiprocessing_distributed or (
args.multiprocessing_distributed and args.rank % ngpus_per_node == 0
):
save_checkpoint(
{
"epoch": epoch + 1,
"arch": args.arch,
"state_dict": model.state_dict(),
"best_acc1": best_acc1,
"optimizer": optimizer.state_dict(),
},
is_best,
)
if epoch == args.start_epoch:
sanity_check(model.state_dict(), args.pretrained)
def train(train_loader, model, criterion, optimizer, epoch, args):
batch_time = AverageMeter("Time", ":6.3f")
data_time = AverageMeter("Data", ":6.3f")
losses = AverageMeter("Loss", ":.4e")
top1 = AverageMeter("Acc@1", ":6.2f")
top5 = AverageMeter("Acc@5", ":6.2f")
progress = ProgressMeter(
len(train_loader),
[batch_time, data_time, losses, top1, top5],
prefix="Epoch: [{}]".format(epoch),
)
"""
Switch to eval mode:
Under the protocol of linear classification on frozen features/models,
it is not legitimate to change any part of the pre-trained model.
BatchNorm in train mode may revise running mean/std (even if it receives
no gradient), which are part of the model parameters too.
"""
model.eval()
end = time.time()
for i, (images, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
if args.gpu is not None:
images = images.cuda(args.gpu, non_blocking=True)
target = target.cuda(args.gpu, non_blocking=True)
# compute output
output = model(images)
loss = criterion(output, target)
# measure accuracy and record loss
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), images.size(0))
top1.update(acc1[0], images.size(0))
top5.update(acc5[0], images.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
progress.display(i)
def validate(val_loader, model, criterion, args):
batch_time = AverageMeter("Time", ":6.3f")
losses = AverageMeter("Loss", ":.4e")
top1 = AverageMeter("Acc@1", ":6.2f")
top5 = AverageMeter("Acc@5", ":6.2f")
progress = ProgressMeter(
len(val_loader), [batch_time, losses, top1, top5], prefix="Test: "
)
# switch to evaluate mode
model.eval()
with torch.no_grad():
end = time.time()
for i, (images, target) in enumerate(val_loader):
if args.gpu is not None:
images = images.cuda(args.gpu, non_blocking=True)
target = target.cuda(args.gpu, non_blocking=True)
# compute output
output = model(images)
loss = criterion(output, target)
# measure accuracy and record loss
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), images.size(0))
top1.update(acc1[0], images.size(0))
top5.update(acc5[0], images.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
progress.display(i)
# TODO: this should also be done with the ProgressMeter
print(
" * Acc@1 {top1.avg:.3f} Acc@5 {top5.avg:.3f}".format(top1=top1, top5=top5)
)
return top1.avg
def save_checkpoint(state, is_best, filename="checkpoint.pth.tar"):
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, "model_best.pth.tar")
def sanity_check(state_dict, pretrained_weights):
"""
Linear classifier should not change any weights other than the linear layer.
This sanity check asserts nothing wrong happens (e.g., BN stats updated).
"""
print("=> loading '{}' for sanity check".format(pretrained_weights))
checkpoint = torch.load(pretrained_weights, map_location="cpu")
state_dict_pre = checkpoint["state_dict"]
for k in list(state_dict.keys()):
# only ignore fc layer
if "fc.weight" in k or "fc.bias" in k:
continue
# name in pretrained model
k_pre = (
"module.encoder_q." + k[len("module.") :]
if k.startswith("module.")
else "module.encoder_q." + k
)
assert (
state_dict[k].cpu() == state_dict_pre[k_pre]
).all(), "{} is changed in linear classifier training.".format(k)
print("=> sanity check passed.")
class AverageMeter:
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=":f"):
self.name = name
self.fmt = fmt
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def __str__(self):
fmtstr = "{name} {val" + self.fmt + "} ({avg" + self.fmt + "})"
return fmtstr.format(**self.__dict__)
class ProgressMeter:
def __init__(self, num_batches, meters, prefix=""):
self.batch_fmtstr = self._get_batch_fmtstr(num_batches)
self.meters = meters
self.prefix = prefix
def display(self, batch):
entries = [self.prefix + self.batch_fmtstr.format(batch)]
entries += [str(meter) for meter in self.meters]
print("\t".join(entries))
def _get_batch_fmtstr(self, num_batches):
num_digits = len(str(num_batches // 1))
fmt = "{:" + str(num_digits) + "d}"
return "[" + fmt + "/" + fmt.format(num_batches) + "]"
def adjust_learning_rate(optimizer, epoch, args):
"""Decay the learning rate based on schedule"""
lr = args.lr
for milestone in args.schedule:
lr *= 0.1 if epoch >= milestone else 1.0
for param_group in optimizer.param_groups:
param_group["lr"] = lr
def accuracy(output, target, topk=(1,)):
"""Computes the accuracy over the k top predictions for the specified values of k"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k]
correct_k = correct_k.reshape(-1)
correct_k = correct_k.float()
correct_k = correct_k.sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
if __name__ == "__main__":
main()


















 916
916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









