







GAN论文研读(一)—–GAN与cGAN
一开学就被各种杂事围攻,也没有心情写博文,不知不觉间已经四个多月没冒泡了(好吧我就是找了个借口~)。考虑到之前写的几篇博文一直没人点踩(zan),在小C同学的启发下,接下来的文章我将以专题的形式发布。
1. 引言
深度学习在图像分类、自然语言处理等领域已取得了卓越的成就。在GAN被提出之前,这些成就主要出现在判别式模型中,通过将高维特征映射为类别标签,直接对该映射过程的参数进行优化,可以在大多数问题上取得较好的效果。相对于判别模型,生成模型与深度网络直接对特征-标签映射进行建模的出发点并不一致。生成模型希望在给定随机变量X先验分布的条件下,生成随机变量Y的条件概率分布P(Y|X),如生成人脸图像、图像风格转换等,这一过程很难直接用分段的线性单元实现。为此,Goodfellow在2014年提出生成对抗网络。该模型中含有两个神经网络,一个判别器D用于判别图像真假,另一个生成器G生成图片迷惑D。实际效果显示二者在相互切磋的过程中,各自的能力会不断加强。模型最终的目的是生成器G生成的图像能够以假乱真。GAN在图像生成方面取得了巨大成功,各种变种不断出现,渐渐弥补了原始GAN模型的各种缺点。本篇博客要介绍的就是GAN的开山之作,Goodfellow在2014年投到NIPS的《Generative Adversarial Nets》以及Mirza的改进《Conditional Generative Adversarial Nets》。
2. GAN与cGAN
2.1 生成对抗网络及其缺点
GAN包含两个神经网络,一个生成网络
G
G
和一个判别网络。
D
D
接受真实图像或者生成的图像,将其映射为一个标量,该标量代表着输入图像是真图像的概率,越接近1,输入图像是真图像的概率就会越大,在此基础上,
G
G
从一个服从高斯分布的噪声开始,通过网络前向传播生成一幅图像,并希望该图像能够迷惑
D
D
,二者构成一种博弈,该博弈过程可描述成如下优化问题。
其中 X X 是从真实数据中获得的样本,为 G G 接受的噪声,服从一个先验分布, Pg P g 为生成器生成的数据分布。一方面,如果判别器 D D 能够正确区分真假图片,式(1)第一项的输出应该是全1的向量,第二项 D(G(Z)) D ( G ( Z ) ) 应该是0向量,整个式子达到最大值。另一方面,对于 G G ,最优的情况是G完全迷惑住,让它认为 G G 生成的图像是真图像,则上式将会达到最小值,求解该最大最小问题貌似能够让生成逼真的图像。
那么,优化该目标是否真的能够让生成器生成的图像概率分布依概率收敛到真实图片的概率分布?答案是肯定的,这一点可以在GAN的求解过程中得到证明。
求解该问题可分为两步,首先固定 G G ,更新的权重,则式(1)变为关于 D D 的泛函。容易求出固定时目标函数的导数:
将其置为0,求解
D
D
可得的表达式为:
将式(3)带入式(1),可以得到:
上式中, KL(∙) K L ( • ) 即KL散度, JSD(∙) J S D ( • ) 为Jensen-Shannon散度,与KL散度具有相似的性质,这里只介绍KL散度。KL散度是一个与输入分布 P P 和有关的泛函。可用于衡量两个分布的相似性:
当两个分布 P P 、一致时,KL散度取得最小值0。此时有
即该问题的最优解满足式6,G生成的图片将会依概率收敛到真实图片的像素分布。至此,我们可以画出GAN的训练算法流程图:

可以想象, D D 不断地接受真假图片并试图区分,不断地生成图片迷惑 D D ,二者不断竞争,最终,接受 G G 生成的图像时,会输出0.5(可以结合公式3和6来看)。
在Goodfellow原始论文中,D网络是基于简单的多层感知机实现的[1]。这种全连接网络简单有效,能够在CIFAR10和MNIST数据集上生成较为逼真的图片。
GAN虽取得巨大的成功,却有几个尚未解决的问题:
1. 训练结果不稳定,常常生成“诡异”图像
尽管有一定理论基础,但GAN在实际生成图片时,往往会出现较为诡异的现象,这主要体现在生成的图片出现畸形或者生成的图片根本就没有意义。这种不稳定性使得GAN模型的训练显得十分神秘。
2. 生成目标不明确,可控性不强
就当前的GAN模型而言,我们能够根据人脸数据集生成人脸,根据车辆数据集生成车辆,但是我们并不能生成具有特定性质的图片,例如生成女人的脸或者法拉利图片。这极大地限制了GAN的推广。
3. G、D之间的训练如何均衡?
考虑一种极端情况,如果只训练使得 D D 的分辨能力十分强,即G生成的任何图片它都能非常准确地识别出这是假的,那么不会学到任何东西。如何在出现这种情况时还能获得有效的梯度用于更新模型将是一个值得探讨的问题。
2.2 特定条件下的图片生成—Conditional GAN
针对原始GAN不能生成具有特定属性的图片的问题,Mehdi Mirza等人[2]提出了cGAN,其核心在于将属性信息
y
y
融入生成器和判别器
D
D
中,属性可以是任何标签信息,例如图像的类别、人脸图像的面部表情等。在此大方向的指导下,下图给出了cGAN的网络拓扑结构。
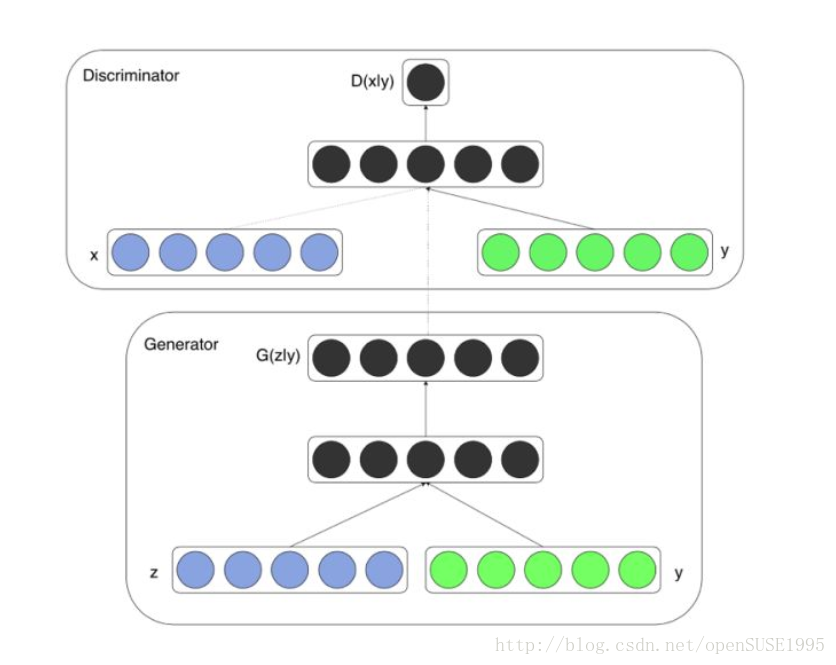
属性信息首先通过One-hot编码映射成由0和1构成的属性向量
y
y
,举例来说,对于某个离散的属性特征,如果他有个可能的取值,One-hot编码就将它映射为
m
m
个二元特征,这些特征互斥,仅在属性特征的取值处为1,如下图所示,所有属性取值的One-hot编码拼接后即得到。该操作解决了离散型属性数据不好处理的问题,同时也拓充了特征。

对生成器
G
G
,cGAN首先使用全连接层将输入的噪声向量 和属性向量分别映射为200维和1000维,并在输入
G
G
前拼接为1200维向量,最后通过前向传播和sigmoid函数激活生成图片。判别器也使用相似的处理方法将真实图像与属性向量
y
y
<script type="math/tex" id="MathJax-Element-117">y</script>进行融合。作者在MNIST数据集上使用mini-batch梯度下降法进行训练,得到了如下结果:

cGAN生成的图像虽有很多缺陷,譬如图像边缘模糊,生成的图像分辨率太低等,但是它为后面的Cycle-GAN和Star GAN开拓了道路,这两个模型转换图像风格时对属性特征的处理方法均受cGAN启发。
经过两篇文章的共同努力,GAN的基本框架已被搭建起来,但GAN仍面临着生成的图像不稳定,可训练性不好等问题。下篇博客将介绍在网络可训练性做出较大贡献的DCGAN。
参考文献:
[1] Goodfellow I. J., Pouget-Abadie J., Mirza M, et.al. Generative Adversarial Nets[C]. NIPS, 2014.
[2] Mirza M. Conditional Generative Adversarial Nets[C]. NIPS, 2014.















 2745
2745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









