






今日高星推荐:Immich私人相册管家!①自动备份手机照片视频,断网也能翻看缓存;②AI智能分类超贴心,搜"海边日落"秒出图;③家庭共享相册超方便,奶奶也能一键看娃照;④旅行地图模式超有趣,点开就能云游打卡地。想告别网盘会员费?自己搭个服务器,全家人的回忆保险箱就搞定啦!(公 众 号·开源热榜)
1ladybird
-
今日星标
1,712 -
总星标数
32,153 -
连续上榜
3天
C++
GitHub - LadybirdBrowser/ladybird: Truly independent web browser
Ladybird是一款基于全新引擎开发的独立网页浏览器,专注于实现现代网络标准。它采用多进程架构设计,将网页渲染、图像解码和网络请求分离到不同进程中运行,通过沙盒机制提升安全性,有效防范恶意内容攻击。目前浏览器整合了包括网页渲染引擎、JavaScript引擎、WebAssembly支持等核心模块,适合开发者体验前沿技术或参与底层开发。虽然处于早期测试阶段,但已能在Linux、macOS和Windows(通过WSL2)等主流系统运行。该项目主要面向对浏览器技术有研究兴趣的开发者,未来目标是打造能流畅支持现代网页应用的全功能浏览器。开发团队积极鼓励技术爱好者加入社区,共同参与代码优化和新特性开发。
2olmocr
-
今日星标
1,060 -
总星标数
6,385 -
连续上榜
5天
Python
GitHub - allenai/olmocr: Toolkit for linearizing PDFs for LLM datasets/training
olmOCR是一个专为处理复杂PDF文档设计的开源工具包,能高效提取适合大语言模型训练的结构化文本。它解决了扫描版PDF、图文混排文档的解析难题,支持单文件快速测试和百万级PDF分布式处理,适合学术论文、技术手册等专业资料的批量转换。工具内置智能过滤系统可自动去除SEO垃圾内容,并提供可视化对比工具检验处理效果。用户既可用本地GPU快速处理少量文件,也能通过云平台并行处理海量数据,输出结果可直接接入主流AI训练框架。该项目特别适合需要构建高质量文本数据集的研究团队或企业,帮助提升模型处理真实场景文档的能力。


3build-your-own-x

-
今日星标
1,053 -
总星标数
346,106
Markdown
这个开源项目旨在通过从零开始重建你喜爱的技术来深入掌握编程。它汇集了大量详细的教程,涵盖从3D渲染器到区块链、操作系统、游戏引擎等多个领域的项目。每个项目都提供了逐步指南,帮助开发者从底层理解这些技术的实现原理。通过动手实践,开发者可以真正掌握这些技术的核心概念。无论是初学者还是经验丰富的开发者,都能从中找到适合自己的挑战和知识。
4union
-
今日星标
919 -
总星标数
34,275 -
连续上榜
2天
Rust
Union 是一个高效的去中心化跨链协议,专注于零知识证明技术,支持消息传递、资产转移、NFT 和 DeFi 应用。它采用共识验证机制,不依赖第三方信任、预言机或多重签名,兼容 Cosmos 生态和 EVM 链(如以太坊、Arbitrum 等)。核心组件包括节点实现、零知识证明系统、跨链中继器和链索引器等,所有升级和配置均由去中心化治理控制。开发者可以使用 Nix 工具链轻松构建和开发 Union 的各个模块。项目旨在提供高安全性和抗审查能力的去中心化基础设施。
5OCRmyPDF

-
今日星标
432 -
总星标数
19,534
Python
OCRmyPDF 是一个命令行工具,能够为扫描的 PDF 文件添加可搜索的 OCR 文本层。它支持多语言识别、自动纠正页面旋转、图像去斜等功能,并生成符合 PDF/A 标准的文件。该工具在保证原始图像质量的同时,优化文件大小,适用于处理大量页面和多核并行运算。OCRmyPDF 基于 Tesseract OCR 引擎,能够处理超过 100 种语言,广泛应用于文档管理和长期存储。
6fastrtc

-
今日星标
384 -
总星标数
2,057 -
连续上榜
5天
Python
GitHub - freddyaboulton/fastrtc: The python library for real-time communication
FastRTC是一个让Python函数变身实时音视频流的开发神器。它能将普通代码快速转化为支持视频会议、语音聊天的交互程序,自动处理语音识别和视频传输等复杂技术细节。开发者只需专注业务逻辑,就能轻松打造智能语音助手、实时视频滤镜、在线教育系统等应用。内置网页界面和电话接口功能,可直接生成可交互的演示demo,比如与ChatGPT语音对话、实时物体检测、语音控制代码编辑等场景。无论是为AI模型增加实时交互能力,还是给传统应用添加音视频功能,都能通过简单API快速实现。
7immich

-
今日星标
340 -
总星标数
59,474 -
连续上榜
2天
TypeScript
GitHub - immich-app/immich: High performance self-hosted photo and video management solution.
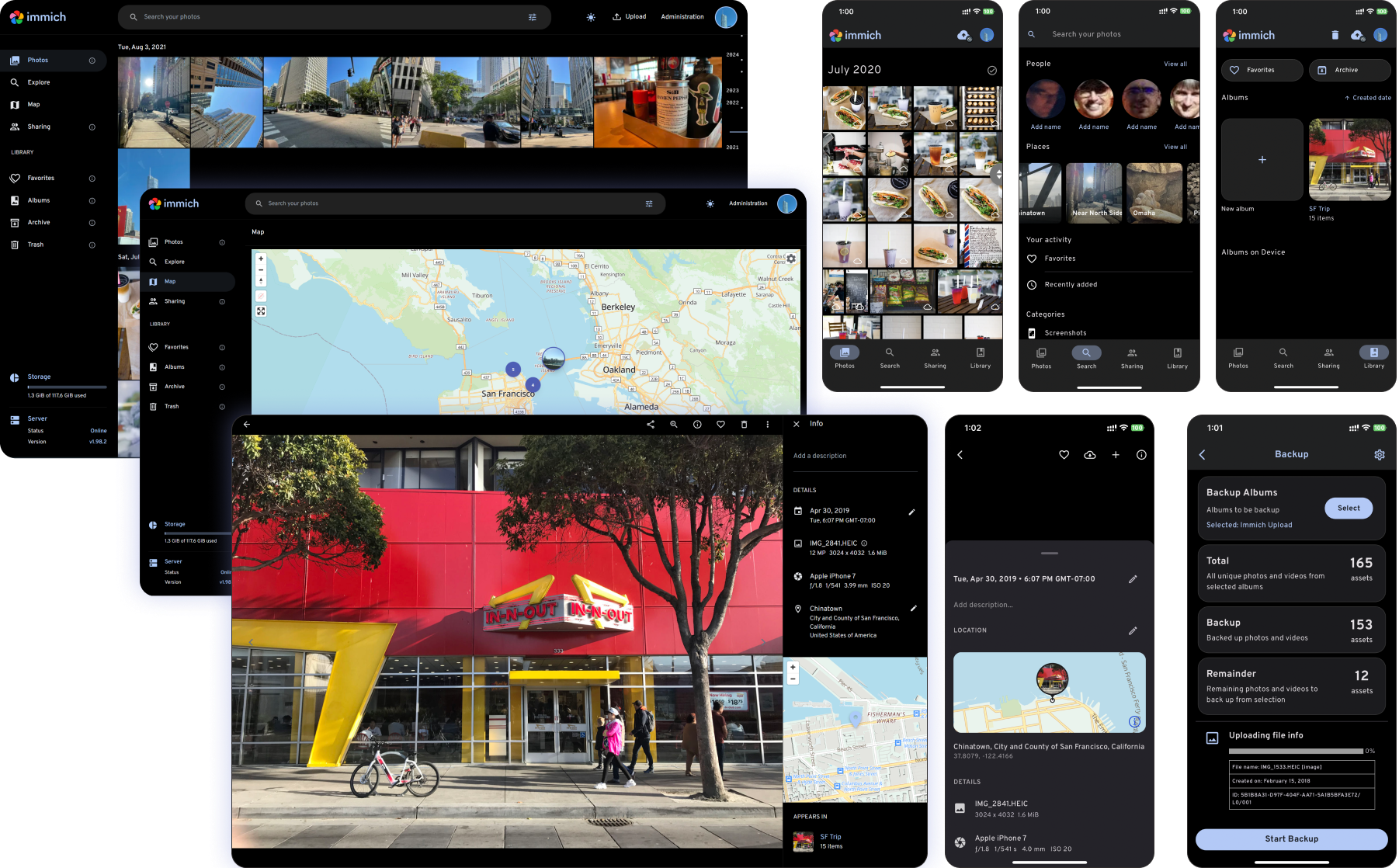
Immich 是一个专为个人和家庭设计的私有化照片视频管理平台,能像主流云服务一样自动备份手机相册并实现跨设备同步。它支持智能分类和搜索功能,通过AI识别画面内容、人脸及地点,帮你快速找到特定照片。用户可以创建共享相册与家人协作,也能在地图上回顾旅行足迹。所有数据存储在自有服务器上,无需依赖第三方云服务,特别适合注重隐私安全的用户。系统提供网页端和移动端双平台访问,即使断网也能浏览本地缓存内容。其轻量化设计对家用设备友好,是搭建私人媒体库的理想选择。
8vision-agent
![]()
-
今日星标
242 -
总星标数
3,755 -
连续上榜
4天
Python
GitHub - landing-ai/vision-agent: Vision agent
VisionAgent是一个帮助开发者利用代理框架生成代码来解决视觉任务的库。它提供了工具和功能,可以用于图像中物体的检测、计数和可视化,还支持视频文件的处理。通过简单的代码调用,开发者可以快速生成并执行视觉任务相关的代码。VisionAgent支持多种大型语言模型(LLM),并提供了灵活配置选项。最便捷的使用方式是通过其提供的Web应用进行快速测试。
9clay
-
今日星标
242 -
总星标数
11,376
C
GitHub - nicbarker/clay: High performance UI layout library in C.
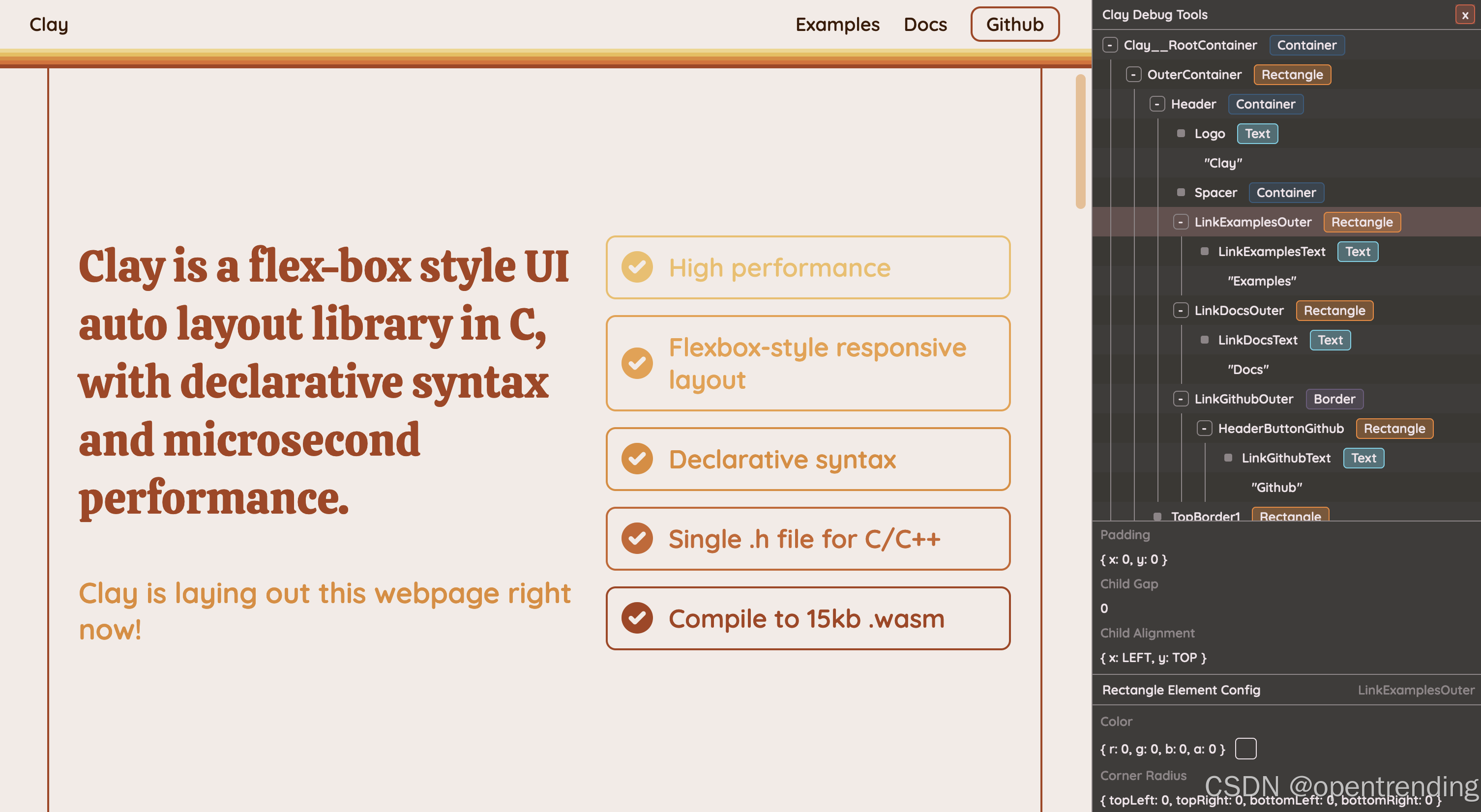
Clay 是一个用 C 语言编写的高性能 UI 布局库,专为需要快速响应的界面设计而生。它通过类似 Flexbox 的布局模型,能轻松实现复杂自适应界面,支持文本换行、滚动容器和比例缩放等功能。这个库仅需单个 2000 行代码的头文件即可使用,无需任何外部依赖,甚至能编译成 15KB 的 WebAssembly 在浏览器运行。其独特的静态内存管理方式避免了动态内存分配,特别适合嵌入式设备和游戏等资源受限的场景。开发者可以用类似 React 的嵌套声明式语法构建界面,最终输出通用的渲染指令集,方便接入各种渲染引擎或直接生成网页。无论是桌面应用、移动端界面还是网页可视化项目,都能通过 Clay 实现毫秒级布局计算。
10generative-ai-for-beginners
-
今日星标
94 -
总星标数
71,761
Jupyter Notebook
这个开源项目是微软推出的生成式AI入门课程,专为零基础学习者设计。课程包含21节实战教程,覆盖从基础概念到应用开发的全流程,帮助用户快速掌握聊天机器人、文本生成、图像创作等AI应用的搭建技巧。每节课结合理论讲解与Python、TypeScript代码示例,支持Azure和OpenAI等多种开发平台。内容包含提示词工程、AI伦理、数据搜索优化等实用技能,特别适合想用AI提升工作效率的开发者。课程还提供扩展学习资源和开发者社区支持,学完后能独立开发智能写作助手、个性化推荐系统等创新应用。项目通过低代码工具和开源模型降低了学习门槛,让没有机器学习背景的人也能上手实践。

















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









