






Crawl4AI这款智能爬虫可太能打了!今日怒涨525星,总星数直逼3.6万,堪称程序员们的网页收割机。三大亮点够吸睛:①智能解析网页核心内容,像开了透视眼般自动过滤广告,转手生成清爽Markdown;②支持动态加载和反爬绕行,电商盯竞品价格、研究员扒论文数据都能一键搞定;③专为AI大模型而生,智能客服更新知识库、AI助手实时充电,用它当数据粮仓准没错!
1awesome-mcp-servers
-
今日星标
3,280 -
总星标数
27,998
https://github.com/punkpeye/awesome-mcp-servers
这是一个专门为AI模型设计的资源连接工具库,能帮助开发者快速搭建智能应用场景。它汇集了上百种开箱即用的服务模块,让AI模型可以直接操作浏览器访问网页、读取本地文件、连接数据库,甚至控制智能家居设备。无论是需要让AI助手自动整理电子表格、分析销售数据,还是实现网页内容自动抓取和翻译,都能找到现成的解决方案。项目覆盖办公自动化、金融分析、学术研究等数十个实用领域,支持Python、TypeScript等多种编程语言开发的模块,既能部署在本地电脑也能运行在云端服务器。开发者通过简单配置就能组合不同功能模块,大幅降低AI应用开发门槛,特别适合需要将AI能力快速落地到实际业务场景的技术团队。
2youtube-music
-
今日星标
1,534 -
总星标数
16,481 -
连续上榜
4天 -
主要语言
TypeScript
https://github.com/th-ch/youtube-music
这是一个基于YouTube Music的增强版桌面播放器,自带广告拦截和音乐下载功能。它能像本地播放器一样运行,支持安装多种实用插件:可屏蔽所有广告、自动下载MP3、显示实时滚动歌词,还能根据专辑封面自动切换界面配色。用户能自由定制可视化效果、全局快捷键操作,甚至实现多人同步听歌的互动功能。应用内置音频压缩和淡入淡出效果,支持Windows/Mac/Linux多平台,特别适合想无广告畅听音乐、需要离线播放以及追求个性化视听体验的用户。
3build-your-own-x

-
今日星标
785 -
总星标数
366,943 -
主要语言
Markdown
https://github.com/codecrafters-io/build-your-own-x
这个开源项目旨在通过从零开始重建你喜爱的技术来深入掌握编程。它汇集了大量详细的教程,涵盖从3D渲染器到区块链、操作系统、游戏引擎等多个领域的项目。每个项目都提供了逐步指南,帮助开发者从底层理解这些技术的实现原理。通过动手实践,开发者可以真正掌握这些技术的核心概念。无论是初学者还是经验丰富的开发者,都能从中找到适合自己的挑战和知识。
4crawl4ai
-
今日星标
525 -
总星标数
35,838 -
连续上榜
3天 -
主要语言
Python
https://github.com/unclecode/crawl4ai
Crawl4AI是一款专为AI大模型设计的智能网页爬虫工具,能像人类浏览网页一样快速抓取并整理内容。它特别适合需要实时获取网络信息的场景,比如为智能客服收集最新资料、帮AI助手自动更新知识库,或是为数据分析师批量采集结构化数据。工具能自动识别网页核心内容,过滤广告等干扰信息,将杂乱网页转化为简洁的Markdown格式,大幅提升AI处理效率。开发者可以用它轻松搭建行业资讯监控系统,研究人员能快速收集论文数据,电商团队也能用它追踪竞品价格变动。无论是处理动态加载的复杂页面,还是需要绕过反爬机制,它都提供了开箱即用的解决方案。
5koreader

-
今日星标
310 -
总星标数
19,523 -
主要语言
Lua
https://github.com/koreader/koreader
KOReader 是一款专为电子墨水屏设备设计的全能电子书阅读器,支持 PDF、EPUB、MOBI 等二十余种常见格式。它能流畅运行在 Kindle、文石、Kobo 等电子书阅读器和安卓设备上,为不同品牌设备用户提供统一的高质量阅读体验。软件提供深度排版自定义功能,可自由调节页边距、行间距,支持外接字体和多种语言的分词词典,特别适合学术文献和外文书籍阅读。内置翻译工具、维基百科查询和 Calibre 无线传书功能,让阅读更智能便捷。针对电子墨水屏特性优化了操作界面和翻页速度,在老旧设备上也能快速响应。通过插件系统还能扩展 RSS 订阅、FTP 传输等实用功能,满足进阶用户的多样化需求。
6inbox-zero

-
今日星标
288 -
总星标数
4,110 -
主要语言
TypeScript
https://github.com/elie222/inbox-zero
这是一个帮你高效管理邮件的开源AI助手。它能自动处理邮件分类、智能回复、归档和标记垃圾信息,像真人秘书一样帮你减轻负担。特别适合每天被大量邮件淹没的商务人士,内置的批量退订功能能一键清理无用订阅,冷邮件拦截帮你隔绝骚扰。通过智能分类和回复追踪,你可以快速跟进重要邮件,避免遗漏关键信息。系统还会生成邮件数据分析报告,帮你优化处理邮件的习惯。所有操作都围绕快速清空收件箱设计,支持本地部署保障隐私安全。
7open-webui
-
今日星标
257 -
总星标数
86,897 -
主要语言
JavaScript
https://github.com/open-webui/open-webui
Open WebUI 是一个功能丰富且用户友好的自托管 AI 平台,支持多种 LLM 运行器,包括 Ollama 和 OpenAI 兼容的 API。它提供了本地 RAG 集成、多模型对话、角色访问控制等强大功能,适用于各种设备和离线环境。通过 Docker 或 Python 可以快速部署,并支持 GPU 加速和 OpenAI API 使用。其模块化设计和插件支持使其具有高度的扩展性和灵活性。Open WebUI 致力于为用户提供无缝的 AI 交互体验,并持续更新以引入新特性。
8dub

-
今日星标
195 -
总星标数
20,820 -
主要语言
TypeScript
https://github.com/dubinc/dub
Dub.co是一款专为营销团队设计的开源链接管理工具,能够将冗长网址转化为品牌化的短链接。它支持自定义域名提升用户信任度,内置设备定位、地区跳转、密码保护等高级功能,让不同场景的推广更精准。通过实时分析点击来源、地理位置等数据,帮助团队量化广告效果。独特的动态二维码生成功能可与短链接搭配使用,还能嵌入企业Logo增强品牌露出。支持多人协作和权限管理,满足企业级营销活动的组织需求。无论是电商促销、社交媒体推广还是线下广告,都能通过智能链接优化用户转化路径。
9ink-kit
-
今日星标
189 -
总星标数
35,623 -
主要语言
TypeScript
https://github.com/inkonchain/ink-kit
Ink Kit 是一个专为区块链应用设计的开发工具包,让开发者能快速搭建美观的交互界面。它提供现成的页面模板和主题样式,像搭积木一样轻松组合出钱包、NFT展示等常见区块链功能界面。内置的酷炫动画组件能自动实现按钮流光、数据加载动效等细节,无需手动编写复杂代码。无论是开发DeFi应用还是数字藏品平台,都能通过几行命令安装并直接调用组件库。工具包配有可视化文档和实时案例演示,边看样例边开发。项目持续更新维护,每周都会新增优化功能。特别适合想快速上线产品、同时追求界面设计感的Web3开发团队使用。
10docs
-
今日星标
163 -
总星标数
35,770 -
主要语言
MDX
https://github.com/inkonchain/docs
InkChain文档平台是一个基于Next.js和Nextra构建的现代化文档工具,专为技术团队打造结构化知识库而生。它提供开箱即用的文档编写体验,内置实时拼写检查、代码规范校验和自动化格式整理功能,确保内容专业可靠。项目支持Docker快速部署,开发时通过pnpm秒级启动调试服务器,团队协作时每个新功能分支都会自动生成临时测试环境供实时预览。文档更新后主分支自动发布到生产环境,适合需要频繁迭代的API文档、技术手册等场景。其集成AWS的CI/CD体系让开发者只需专注内容创作,是开源项目和企业内部知识管理的高效解决方案。
11OpenHands

-
今日星标
112 -
总星标数
51,875 -
主要语言
Python
https://github.com/All-Hands-AI/OpenHands
OpenHands是一个AI驱动的智能开发助手,能够像人类程序员一样完成多种开发任务。它不仅能自动编写和修改代码、执行命令,还能通过浏览器操作和API调用解决复杂问题,甚至能从技术论坛快速获取代码片段。这个工具特别适合需要快速完成重复性编码工作或探索技术方案的开发者,比如自动修复bug、搭建项目框架或验证新技术可行性。用户通过简单的Docker命令就能在本地快速部署,支持主流的AI模型灵活切换。它提供可视化界面和脚本模式,既能实时查看AI操作过程,也能批量处理开发任务。社区活跃的技术讨论和持续更新,让它成为提升编程效率的智能搭档。
12postiz-app

-
今日星标
96 -
总星标数
18,938 -
主要语言
TypeScript
https://github.com/gitroomhq/postiz-app
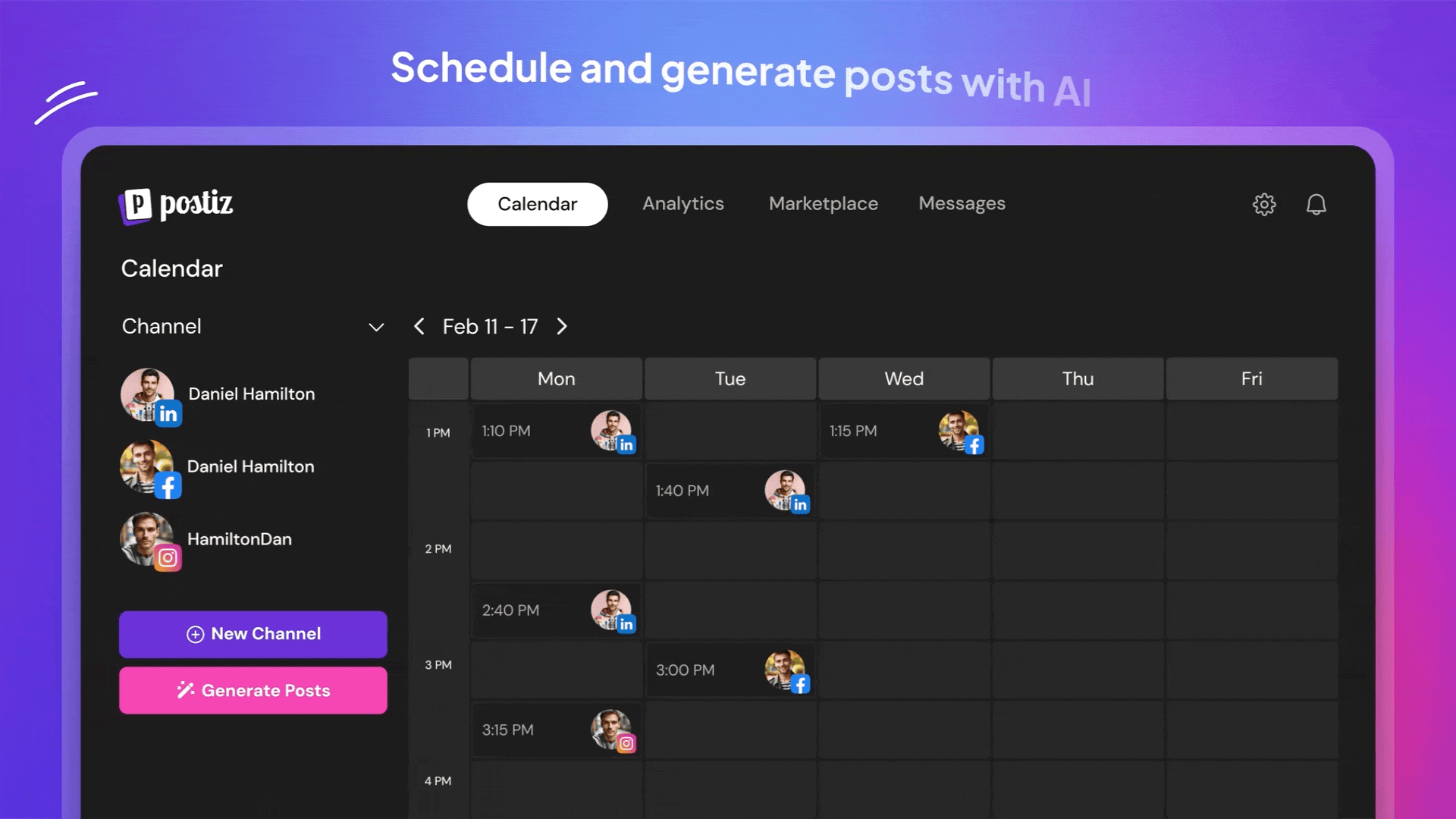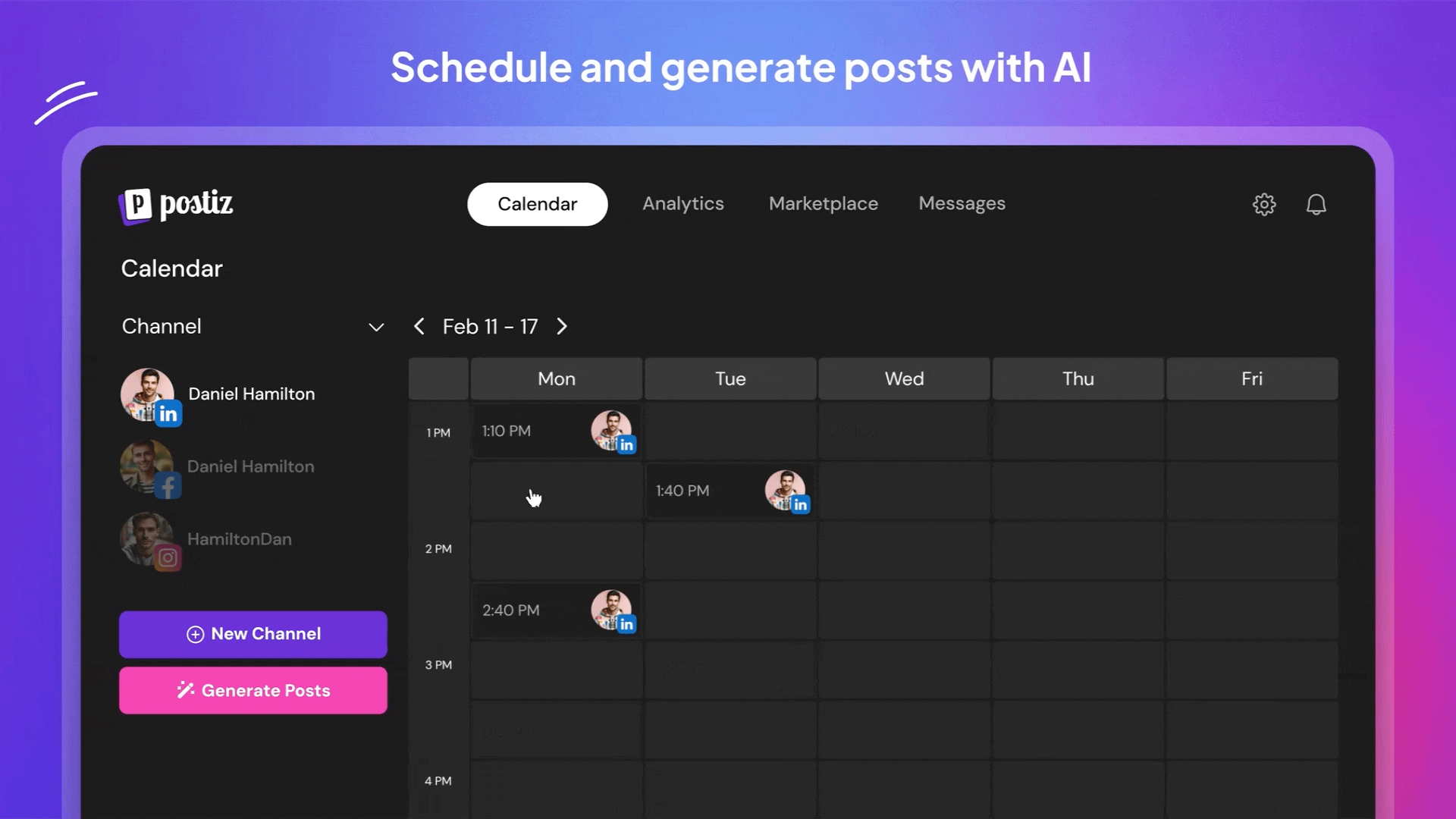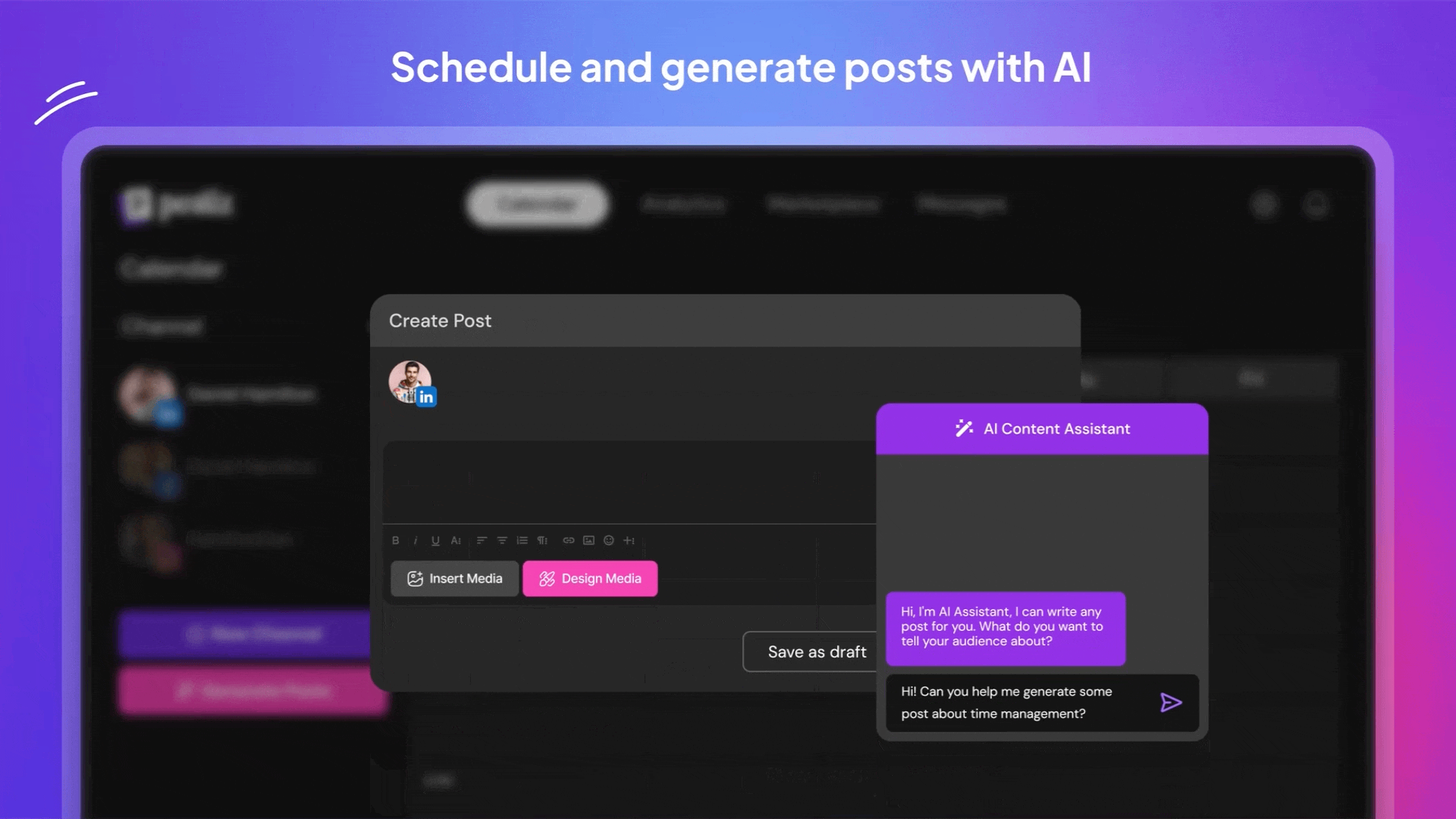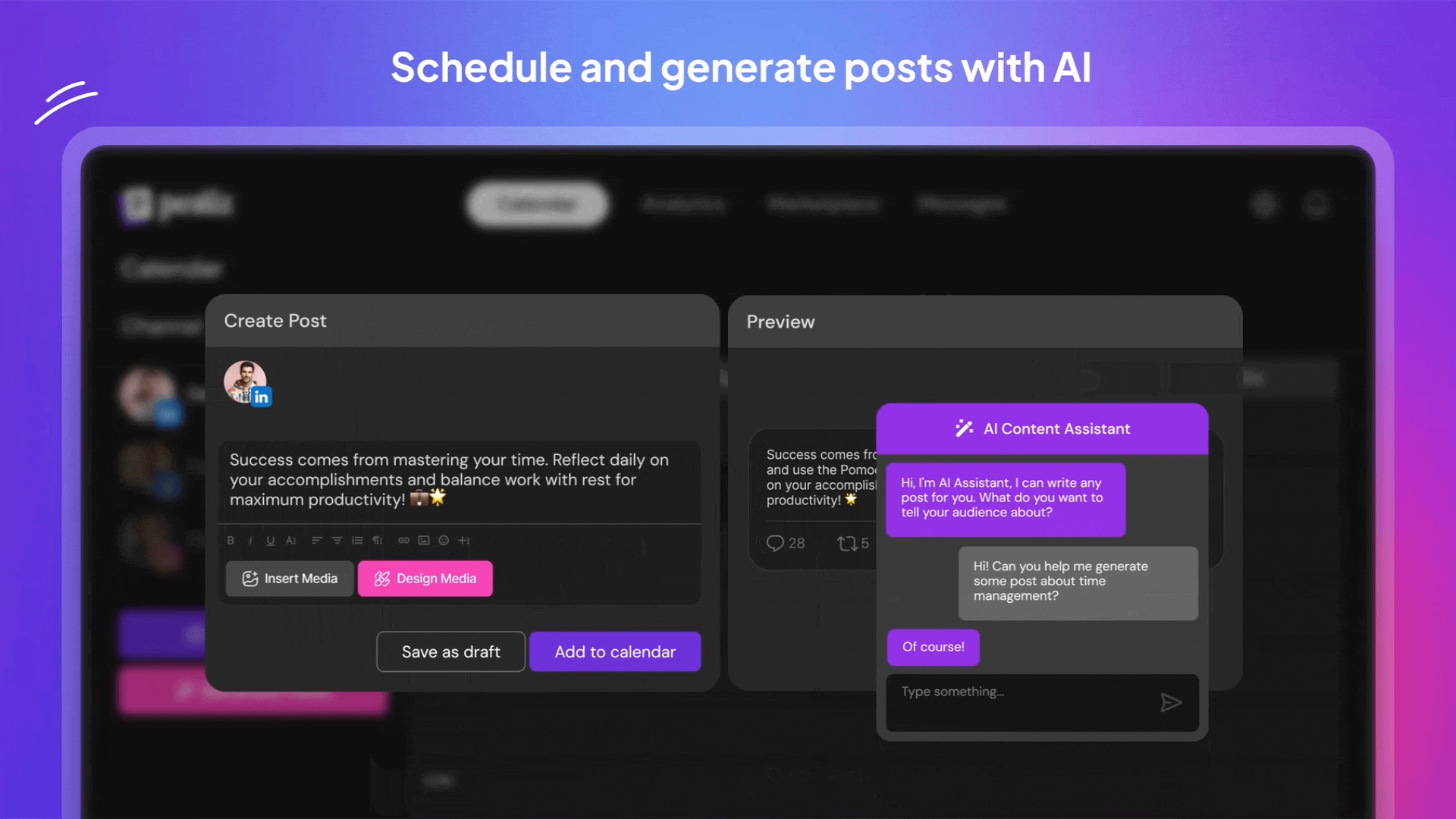
Postiz是一款智能社交媒体管理神器,能帮你一键搞定多平台发帖难题。它支持Instagram、抖音、领英等13个主流平台,像私人助理一样自动安排最佳发布时间。内置AI不仅能帮你写文案,还能优化内容吸引更多粉丝。团队协作功能让多人编辑、评论内容像在线文档一样方便,还能买卖创意帖子扩展内容库。自带数据分析看板让你实时掌握每条动态的表现,轻松调整运营策略。不管是独立创作者还是企业团队,都能用它告别手动发帖的繁琐,把更多精力花在创意策划上。
13cookbook
-
今日星标
74 -
总星标数
11,328 -
主要语言
Jupyter Notebook
https://github.com/google-gemini/cookbook
这是一个帮助开发者快速上手Gemini人工智能API的开源教程库。它通过大量实战案例和分步指南,教你如何将文字、图像、音视频等多媒体内容结合AI能力进行创新开发。项目特别适合想实现智能对话、自动生成插画/动画、实时数据分析可视化、3D场景理解等场景的开发者,提供从代码执行、网页交互到图像生成的完整解决方案。教程涵盖最新AI功能如实时音视频流处理、多模态内容创作工具,还包含将AI能力整合到Gradio界面等实际工程案例。无论是教育领域的互动课件开发,还是商业场景的智能助手搭建,都能在这里找到可复用的模版和灵感。
14nvm

-
今日星标
35 -
总星标数
83,213 -
连续上榜
2天 -
主要语言
Shell
https://github.com/nvm-sh/nvm
这是一个用于管理多个Node.js版本的工具,适合需要在不同项目间切换node版本的开发者。通过简单的命令行操作,可以快速安装、切换不同版本的Node环境,比如同时维护使用Node 14和Node 16的两个项目时,只需分别执行nvm use 14和nvm use 16即可无缝切换。它自动处理环境变量和依赖关系,支持macOS/Linux系统和Windows的WSL,还能通过.nvmrc文件为每个项目固定特定Node版本,团队协作时能保持环境统一。
15higress

-
今日星标
35 -
总星标数
4,287 -
主要语言
Go
https://github.com/alibaba/higress
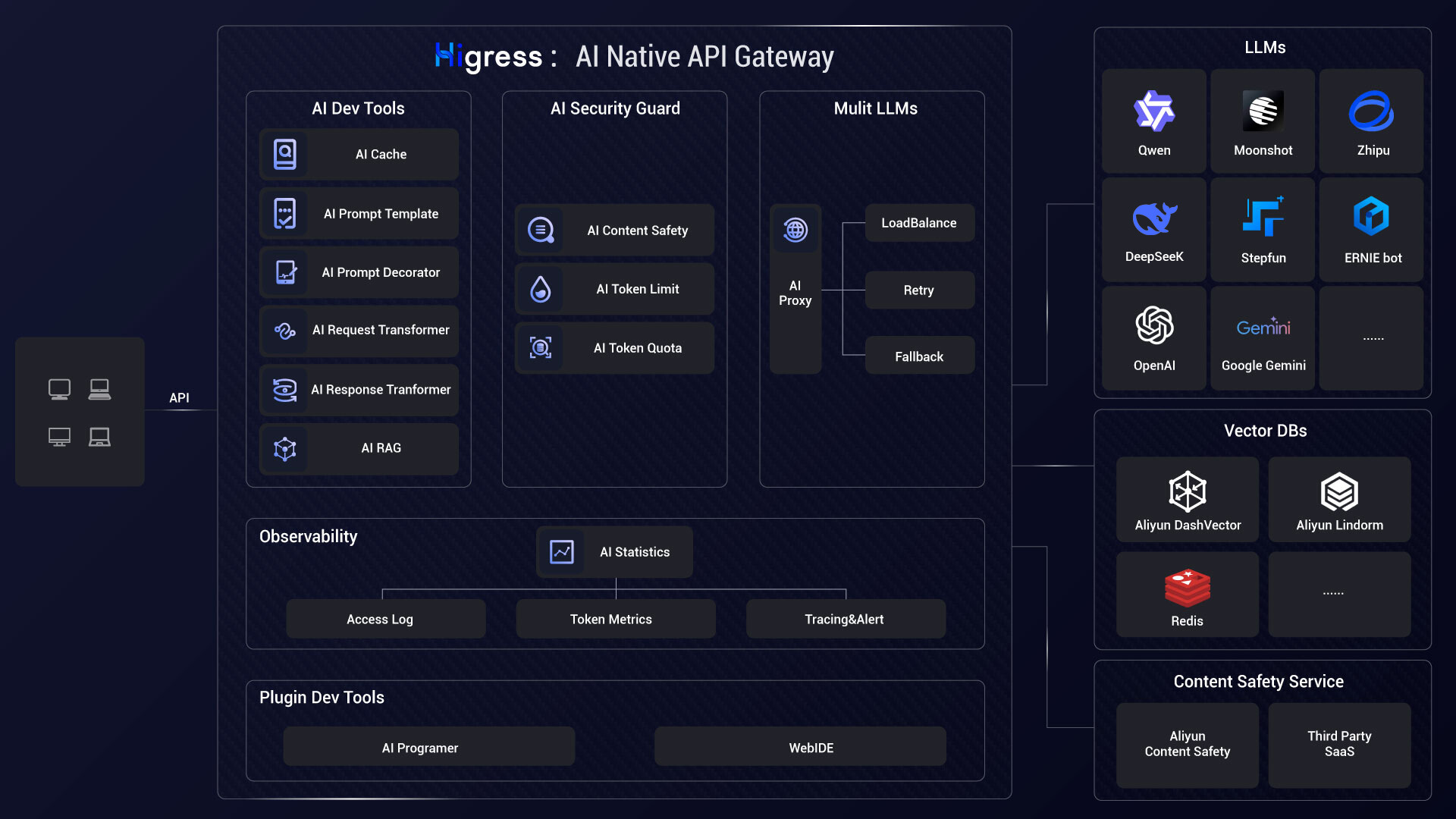
Higress是一款面向AI场景设计的云原生API网关,能够无缝对接国内外主流大模型和自建AI系统。它像智能交通管制中心一样,统一管理各类AI服务接口,提供流量监控、负载均衡、智能限流和缓存加速等核心功能,帮助企业轻松应对高并发AI调用需求。无论是支撑大语言模型应用、AI工具调用平台还是机器学习服务,它都能确保接口调用的稳定性和安全性。该网关支持动态热更新插件,可实时升级AI处理逻辑而不中断服务,特别适合需要长时间保持连接的AI应用场景。开发者和企业只需简单配置就能快速搭建生产级的AI服务网关,大幅降低复杂AI系统的接入和维护成本。
16aie-book
-
今日星标
13 -
总星标数
3,120 -
主要语言
Jupyter Notebook
https://github.com/chiphuyen/aie-book
这是一个为AI工程师打造的实用资源库,重点提供大模型落地的系统化解决方案。它包含Chip Huyen新书《AI工程》的章节要点、学习笔记和配套案例,覆盖从提示工程到模型微调的全流程。项目提供RAG策略选择指南、智能体开发模式、幻觉检测方法等实战技巧,帮助开发者解决模型响应速度慢、成本高、输出不稳定等常见难题。内含真实行业案例和对话热力图生成工具,既能辅助技术决策,也适合用作团队培训材料。无论是想优化现有AI应用,还是从零搭建生产级系统,都能找到对应的评估框架和工程实践参考。

















 3598
3598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









